apoc.export.graphml.data
语法 |
|
||
描述 |
将给定的 |
||
输入参数 |
名称 |
类型 |
描述 |
|
|
要导出的节点列表。 |
|
|
|
要导出的关系列表。 |
|
|
|
导出数据的文件名。 |
|
|
|
|
|
返回参数 |
名称 |
类型 |
描述 |
|
|
导出数据的文件名。 |
|
|
|
导出数据的摘要。 |
|
|
|
文件导出的格式。 |
|
|
|
导出的节点数量。 |
|
|
|
导出的关系数量。 |
|
|
|
导出的属性数量。 |
|
|
|
导出持续时间。 |
|
|
|
返回的行数。 |
|
|
|
导出运行的批次大小。 |
|
|
|
导出运行的批次数。 |
|
|
|
导出是否成功运行。 |
|
|
|
导出返回的数据。 |
|
配置参数
这些过程支持以下配置参数
| 参数 | 类型 | 默认 | 描述 |
|---|---|---|---|
stream |
BOOLEAN |
false |
在查询结果中返回数据,而不是将其存储到文件中。 |
compression |
|
'NONE' |
允许接收二进制数据,可以不压缩(值: |
timeoutSeconds |
INTEGER |
100 |
查询在超时前应运行的最长时间(秒)。 |
charset |
STRING |
'UTF_8' |
当前使用的 JDK 中扩展 java.nio.Charset 的字符集名称。例如: |
useTypes |
BOOLEAN |
false |
将类型添加到文件头。 |
format |
STRING |
'cypher-shell' |
导出格式。 |
source |
MAP |
false |
与 |
target |
MAP |
100 |
与 |
caption |
LIST<STRING> |
['name', 'title', 'label', 'id'] |
允许接收二进制数据,可以不压缩(值: |
使用示例
本节中的示例基于以下示例图
CREATE (TheMatrix:Movie {title:'The Matrix', released:1999, tagline:'Welcome to the Real World'})
CREATE (Keanu:Person {name:'Keanu Reeves', born:1964})
CREATE (Carrie:Person {name:'Carrie-Anne Moss', born:1967})
CREATE (Laurence:Person {name:'Laurence Fishburne', born:1961})
CREATE (Hugo:Person {name:'Hugo Weaving', born:1960})
CREATE (LillyW:Person {name:'Lilly Wachowski', born:1967})
CREATE (LanaW:Person {name:'Lana Wachowski', born:1965})
CREATE (JoelS:Person {name:'Joel Silver', born:1952})
CREATE
(Keanu)-[:ACTED_IN {roles:['Neo']}]->(TheMatrix),
(Carrie)-[:ACTED_IN {roles:['Trinity']}]->(TheMatrix),
(Laurence)-[:ACTED_IN {roles:['Morpheus']}]->(TheMatrix),
(Hugo)-[:ACTED_IN {roles:['Agent Smith']}]->(TheMatrix),
(LillyW)-[:DIRECTED]->(TheMatrix),
(LanaW)-[:DIRECTED]->(TheMatrix),
(JoelS)-[:PRODUCED]->(TheMatrix);下面的 Neo4j Browser 可视化显示了导入的图
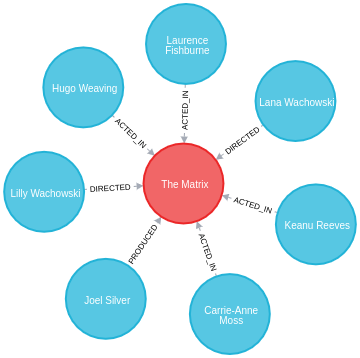
apoc.export.graphml.data 过程将指定的节点和关系导出到 CSV 文件或作为流输出。
以下查询将所有具有 :Person 标签且 name 属性以 L 开头的节点导出到文件 movies-l.csv
MATCH (person:Person)
WHERE person.name STARTS WITH "L"
WITH collect(person) AS people
CALL apoc.export.graphml.data(people, [], "movies-l.graphml", {})
YIELD file, source, format, nodes, relationships, properties, time, rows, batchSize, batches, done, data
RETURN file, source, format, nodes, relationships, properties, time, rows, batchSize, batches, done, data| file | source | format | nodes | relationships | properties | time | rows | batchSize | batches | done | data |
|---|---|---|---|---|---|---|---|---|---|---|---|
"movies-l.csv" |
"data: nodes(3), rels(0)" |
"csv" |
3 |
0 |
6 |
2 |
3 |
20000 |
1 |
TRUE |
NULL |
<?xml version="1.0" encoding="UTF-8"?>
<graphml xmlns="http://graphml.graphdrawing.org/xmlns" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://graphml.graphdrawing.org/xmlns http://graphml.graphdrawing.org/xmlns/1.0/graphml.xsd">
<key id="born" for="node" attr.name="born"/>
<key id="name" for="node" attr.name="name"/>
<key id="label" for="node" attr.name="label"/>
<graph id="G" edgedefault="directed">
<node id="n191" labels=":Person"><data key="labels">:Person</data><data key="born">1961</data><data key="name">Laurence Fishburne</data></node>
<node id="n193" labels=":Person"><data key="labels">:Person</data><data key="born">1967</data><data key="name">Lilly Wachowski</data></node>
<node id="n194" labels=":Person"><data key="labels">:Person</data><data key="born">1965</data><data key="name">Lana Wachowski</data></node>
</graph>
</graphml>以下查询在 data 列中返回所有 ACTED_IN 关系以及该关系两侧具有 Person 和 Movie 标签的节点的流
MATCH (person:Person)-[actedIn:ACTED_IN]->(movie:Movie)
WITH collect(DISTINCT person) AS people, collect(DISTINCT movie) AS movies, collect(actedIn) AS actedInRels
CALL apoc.export.graphml.data(people + movies, actedInRels, null, {stream: true})
YIELD file, nodes, relationships, properties, data
RETURN file, nodes, relationships, properties, data;| file | nodes | relationships | properties | data |
|---|---|---|---|---|
NULL |
5 |
4 |
15 |
|