apoc.export.csv.all
|
此过程不被认为是多线程安全执行的。因此,并行运行时不支持此过程。更多信息请参阅Cypher 手册 → 并行运行时。 |
语法 |
|
||
描述 |
将整个数据库导出到提供的 CSV 文件。 |
||
输入参数 |
名称 |
类型 |
描述 |
|
|
将数据导出到的文件名。 |
|
|
|
|
|
返回参数 |
名称 |
类型 |
描述 |
|
|
导出数据到的文件名。 |
|
|
|
导出数据的摘要。 |
|
|
|
文件导出的格式。 |
|
|
|
导出的节点数量。 |
|
|
|
导出的关系数量。 |
|
|
|
导出的属性数量。 |
|
|
|
导出持续时间。 |
|
|
|
返回的行数。 |
|
|
|
导出运行的批次大小。 |
|
|
|
导出运行的批次数量。 |
|
|
|
导出是否成功运行。 |
|
|
|
导出返回的数据。 |
|
使用示例
本节中的示例基于以下示例图
CREATE (TheMatrix:Movie {title:'The Matrix', released:1999, tagline:'Welcome to the Real World'})
CREATE (Keanu:Person {name:'Keanu Reeves', born:1964})
CREATE (Carrie:Person {name:'Carrie-Anne Moss', born:1967})
CREATE (Laurence:Person {name:'Laurence Fishburne', born:1961})
CREATE (Hugo:Person {name:'Hugo Weaving', born:1960})
CREATE (LillyW:Person {name:'Lilly Wachowski', born:1967})
CREATE (LanaW:Person {name:'Lana Wachowski', born:1965})
CREATE (JoelS:Person {name:'Joel Silver', born:1952})
CREATE
(Keanu)-[:ACTED_IN {roles:['Neo']}]->(TheMatrix),
(Carrie)-[:ACTED_IN {roles:['Trinity']}]->(TheMatrix),
(Laurence)-[:ACTED_IN {roles:['Morpheus']}]->(TheMatrix),
(Hugo)-[:ACTED_IN {roles:['Agent Smith']}]->(TheMatrix),
(LillyW)-[:DIRECTED]->(TheMatrix),
(LanaW)-[:DIRECTED]->(TheMatrix),
(JoelS)-[:PRODUCED]->(TheMatrix);下面的 Neo4j 浏览器可视化显示了导入的图
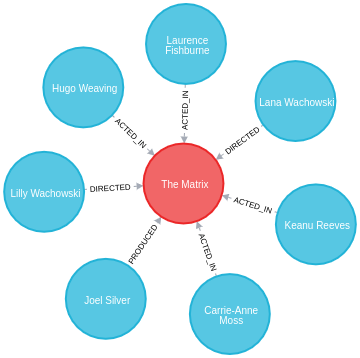
The apoc.export.csv.all 过程将整个数据库导出到 CSV 文件或作为流。
以下查询将整个数据库导出到文件 movies.csv
CALL apoc.export.csv.all("movies.csv", {})| file | source | format | nodes | relationships | properties | time | rows | batchSize | batches | done | data |
|---|---|---|---|---|---|---|---|---|---|---|---|
"movies.csv" |
"database: nodes(8), rels(7)" |
"csv" |
8 |
7 |
21 |
39 |
15 |
20000 |
1 |
TRUE |
NULL |
movies.csv 的内容如下所示
"_id","_labels","born","name","released","tagline","title","_start","_end","_type","roles"
"188",":Movie","","","1999","Welcome to the Real World","The Matrix",,,,
"189",":Person","1964","Keanu Reeves","","","",,,,
"190",":Person","1967","Carrie-Anne Moss","","","",,,,
"191",":Person","1961","Laurence Fishburne","","","",,,,
"192",":Person","1960","Hugo Weaving","","","",,,,
"193",":Person","1967","Lilly Wachowski","","","",,,,
"194",":Person","1965","Lana Wachowski","","","",,,,
"195",":Person","1952","Joel Silver","","","",,,,
,,,,,,,"189","188","ACTED_IN","[""Neo""]"
,,,,,,,"190","188","ACTED_IN","[""Trinity""]"
,,,,,,,"191","188","ACTED_IN","[""Morpheus""]"
,,,,,,,"192","188","ACTED_IN","[""Agent Smith""]"
,,,,,,,"193","188","DIRECTED",""
,,,,,,,"194","188","DIRECTED",""
,,,,,,,"195","188","PRODUCED",""以下查询在 data 列中返回整个数据库的流
CALL apoc.export.csv.all(null, {stream:true})
YIELD file, nodes, relationships, properties, data
RETURN file, nodes, relationships, properties, data| file | nodes | relationships | properties | data |
|---|---|---|---|---|
NULL |
8 |
7 |
21 |
"\"_id\",\"_labels\",\"born\",\"name\",\"released\",\"tagline\",\"title\",\"_start\",\"_end\",\"_type\",\"roles\" \"188\",\":Movie\",\"\",\"\",\"1999\",\"Welcome to the Real World\",\"The Matrix\",,,, \"189\",\":Person\",\"1964\",\"Keanu Reeves\",\"\",\"\",\"\",,,, \"190\",\":Person\",\"1967\",\"Carrie-Anne Moss\",\"\",\"\",\"\",,,, \"191\",\":Person\",\"1961\",\"Laurence Fishburne\",\"\",\"\",\"\",,,, \"192\",\":Person\",\"1960\",\"Hugo Weaving\",\"\",\"\",\"\",,,, \"193\",\":Person\",\"1967\",\"Lilly Wachowski\",\"\",\"\",\"\",,,, \"194\",\":Person\",\"1965\",\"Lana Wachowski\",\"\",\"\",\"\",,,, \"195\",\":Person\",\"1952\",\"Joel Silver\",\"\",\"\",\"\",,,, ,,,,,,,\"189\",\"188\",\"ACTED_IN\",\"[\"\"Neo\"\"]\" ,,,,,,,\"190\",\"188\",\"ACTED_IN\",\"[\"\"Trinity\"\"]\" ,,,,,,,\"191\",\"188\",\"ACTED_IN\",\"[\"\"Morpheus\"\"]\" ,,,,,,,\"192\",\"188\",\"ACTED_IN\",\"[\"\"Agent Smith\"\"]\" ,,,,,,,\"193\",\"188\",\"DIRECTED\",\"\" ,,,,,,,\"194\",\"188\",\"DIRECTED\",\"\" ,,,,,,,\"195\",\"188\",\"PRODUCED\",\"\" " |
你可以使用配置 sampling(默认值:false)。使用此配置,apoc.export.csv.all 过程会在内部使用 apoc.meta.nodeTypeProperties 和 apoc.meta.relTypeProperties 过程来获取属性类型。你可以使用 samplingConfig: MAP 配置来自定义这两个 apoc.meta.* 过程的配置,以限制要分析的节点/关系的数量。
因此你可以使用以下数据集执行
CREATE (:User:Sample {`last:Name`:'Galilei'}), (:User:Sample {address:'Universe'}),
(:User:Sample {foo:'bar'})-[:KNOWS {one: 'two', three: 'four'}]->(:User:Sample {baz:'baa', foo: true})结合以下查询
CALL apoc.export.csv.all('movies.csv', {sampling: true, samplingConfig: {sample: 1}})| file | source | format | nodes | relationships | properties | time | rows | batchSize | batches | done | data |
|---|---|---|---|---|---|---|---|---|---|---|---|
"movies.csv" |
"database: nodes(4), rels(1)" |
"csv" |
4 |
1 |
3 |
4 |
5 |
20000 |
1 |
TRUE |
NULL |
执行上述查询将输出类似以下内容(结果可能因 sample 而异)
"_id","_labels","baz","foo","_start","_end","_type"
"0",":Sample:User","","",,,
"1",":Sample:User","","",,,
"2",":Sample:User","","bar",,,
"3",":Sample:User","baa","true",,,
,,,,"2","3","KNOWS"