apoc.export.cypher.data
|
此过程被认为从多线程运行不安全。因此,并行运行时不支持此过程。欲了解更多信息,请参阅 Cypher 手册 → 并行运行时。 |
语法 |
|
||
描述 |
将给定的 |
||
输入参数 |
名称 |
类型 |
描述 |
|
|
要导出的节点列表。 |
|
|
|
要导出的关系列表。 |
|
|
|
数据将导出的文件名。默认值为:``。 |
|
|
|
|
|
返回参数 |
名称 |
类型 |
描述 |
|
|
数据导出的文件名。 |
|
|
|
导出运行的批次数量。 |
|
|
|
导出数据的摘要。 |
|
|
|
文件导出的格式。 |
|
|
|
导出的节点数量。 |
|
|
|
导出的关系数量。 |
|
|
|
导出的属性数量。 |
|
|
|
导出持续时间。 |
|
|
|
返回的行数。 |
|
|
|
导出运行的批次大小。 |
|
|
|
已执行的 Cypher 语句。 |
|
|
|
已执行的节点语句。 |
|
|
|
已执行的关系语句。 |
|
|
|
已执行的 schema 语句。 |
|
|
|
已执行的清理语句。 |
|
配置参数
此过程支持以下配置参数
| 名称 | 类型 | 默认值 | 描述 |
|---|---|---|---|
|
|
false |
如果为 true,则也导出属性。 |
|
|
false |
将 JSON 直接流式传输到客户端的 |
|
|
cypher-shell |
导出格式。支持以下值
|
|
|
create |
Cypher 更新操作类型。支持以下值
|
useOptimizations |
MAP |
|
用于 Cypher 语句生成的优化。
|
|
|
300 |
使用 |
|
|
false |
如果为 true,则将关键字 |
导出到文件
默认情况下,导出到文件系统是禁用的。我们可以通过在 apoc.conf 中设置以下属性来启用它
apoc.export.file.enabled=true有关访问 apoc.conf 的更多信息,请参阅配置选项章节。
如果我们尝试使用任何导出过程而未首先设置此属性,将收到以下错误消息
调用过程失败:原因:java.lang.RuntimeException: 未启用文件导出,请在 apoc.conf 中设置 apoc.export.file.enabled=true。否则,如果您在没有文件系统访问权限的云环境中运行,请使用 |
导出文件将写入 import 目录,该目录由 server.directories.import 属性定义。这意味着我们提供的任何文件路径都是相对于此目录的。如果尝试写入绝对路径,例如 /tmp/filename,将收到类似于以下内容的错误消息
调用过程失败:原因:java.io.FileNotFoundException: /path/to/neo4j/import/tmp/fileName (没有此类文件或目录) |
我们可以通过在 apoc.conf 中设置以下属性来启用写入文件系统上的任何位置
apoc.import.file.use_neo4j_config=false|
现在 Neo4j 将能够写入文件系统上的任何位置,因此在设置此属性之前请务必确认这是您的意图。 |
使用示例
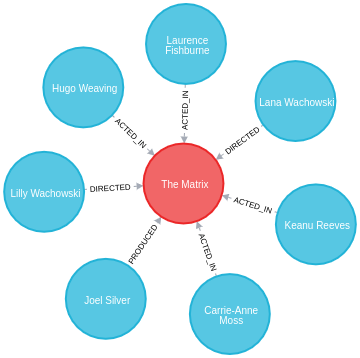
本节中的示例基于以下示例图
CREATE (TheMatrix:Movie {title:'The Matrix', released:1999, tagline:'Welcome to the Real World'})
CREATE (Keanu:Person {name:'Keanu Reeves', born:1964})
CREATE (Carrie:Person {name:'Carrie-Anne Moss', born:1967})
CREATE (Laurence:Person {name:'Laurence Fishburne', born:1961})
CREATE (Hugo:Person {name:'Hugo Weaving', born:1960})
CREATE (LillyW:Person {name:'Lilly Wachowski', born:1967})
CREATE (LanaW:Person {name:'Lana Wachowski', born:1965})
CREATE (JoelS:Person {name:'Joel Silver', born:1952})
CREATE
(Keanu)-[:ACTED_IN {roles:['Neo']}]->(TheMatrix),
(Carrie)-[:ACTED_IN {roles:['Trinity']}]->(TheMatrix),
(Laurence)-[:ACTED_IN {roles:['Morpheus']}]->(TheMatrix),
(Hugo)-[:ACTED_IN {roles:['Agent Smith']}]->(TheMatrix),
(LillyW)-[:DIRECTED]->(TheMatrix),
(LanaW)-[:DIRECTED]->(TheMatrix),
(JoelS)-[:PRODUCED]->(TheMatrix);下面的 Neo4j Browser 可视化显示了导入的图
导出到 Cypher 的过程使用 CREATE、MATCH 和 MERGE 子句生成 Cypher 语句。格式由 cypherFormat 参数配置。支持以下值
-
create- 仅使用CREATE子句(默认) -
updateAll- 使用MERGE而不是CREATE -
addStructure- 节点使用MATCH,关系使用MERGE -
updateStructure- 节点和关系都使用MERGE和MATCH
如果首次导出数据库,应使用默认的 create 格式,但对于后续导出,其他格式可能更适合。
以下示例使用 create 格式将 ACTED_IN 关系和周围节点导出到 export-cypher-format-create.cypher
MATCH (person)-[r:ACTED_IN]->(movie)
WITH collect(DISTINCT person) + collect(DISTINCT movie) AS importNodes, collect(r) AS importRels
CALL apoc.export.cypher.data(importNodes, importRels,
"export-cypher-format-create.cypher",
{ format: "plain", cypherFormat: "create" })
YIELD file, batches, source, format, nodes, relationships, properties, time, rows, batchSize
RETURN file, batches, source, format, nodes, relationships, properties, time, rows, batchSize;| file | batches | source | format | nodes | relationships | properties | time | rows | batchSize |
|---|---|---|---|---|---|---|---|---|---|
"export-cypher-format-create.cypher" |
1 |
"data: nodes(5), rels(4)" |
"cypher" |
5 |
4 |
15 |
2 |
9 |
20000 |
CREATE CONSTRAINT uniqueConstraint FOR (node:`UNIQUE IMPORT LABEL`) REQUIRE (node.`UNIQUE IMPORT ID`) IS UNIQUE;
UNWIND [{_id:0, properties:{tagline:"Welcome to the Real World", title:"The Matrix", released:1999}}] AS row
CREATE (n:`UNIQUE IMPORT LABEL`{`UNIQUE IMPORT ID`: row._id}) SET n += row.properties SET n:Movie;
UNWIND [{_id:7, properties:{born:1967, name:"Carrie-Anne Moss"}},
{_id:80, properties:{born:1960, name:"Hugo Weaving"}},
{_id:27, properties:{born:1964, name:"Keanu Reeves"}},
{_id:44, properties:{born:1961, name:"Laurence Fishburne"}}] AS row
CREATE (n:`UNIQUE IMPORT LABEL`{`UNIQUE IMPORT ID`: row._id}) SET n += row.properties SET n:Person;
UNWIND [{start: {_id:27}, end: {_id:0}, properties:{roles:["Neo"]}},
{start: {_id:7}, end: {_id:0}, properties:{roles:["Trinity"]}},
{start: {_id:44}, end: {_id:0}, properties:{roles:["Morpheus"]}},
{start: {_id:80}, end: {_id:0}, properties:{roles:["Agent Smith"]}}] AS row
MATCH (start:`UNIQUE IMPORT LABEL`{`UNIQUE IMPORT ID`: row.start._id})
MATCH (end:`UNIQUE IMPORT LABEL`{`UNIQUE IMPORT ID`: row.end._id})
CREATE (start)-[r:ACTED_IN]->(end) SET r += row.properties;
MATCH (n:`UNIQUE IMPORT LABEL`) WITH n LIMIT 20000 REMOVE n:`UNIQUE IMPORT LABEL` REMOVE n.`UNIQUE IMPORT ID`;
DROP CONSTRAINT uniqueConstraint;所有图实体的创建都使用 Cypher CREATE 子句。如果这些实体可能已存在于目标数据库中,我们可以选择使用其他格式。使用 cypherFormat: "updateAll" 意味着在创建实体时将使用 MERGE 子句而不是 CREATE。
以下示例使用 updateAll 格式将 ACTED_IN 关系和周围节点导出到 export-cypher-format-create.cypher
MATCH (person)-[r:ACTED_IN]->(movie)
WITH collect(DISTINCT person) + collect(DISTINCT movie) AS importNodes, collect(r) AS importRels
CALL apoc.export.cypher.data(importNodes, importRels,
"export-cypher-format-updateAll.cypher",
{ format: "plain", cypherFormat: "updateAll" })
YIELD file, batches, source, format, nodes, relationships, properties, time, rows, batchSize
RETURN file, batches, source, format, nodes, relationships, properties, time, rows, batchSize;| file | batches | source | format | nodes | relationships | properties | time | rows | batchSize |
|---|---|---|---|---|---|---|---|---|---|
"export-cypher-format-updateAll.cypher" |
1 |
"data: nodes(5), rels(4)" |
"cypher" |
5 |
4 |
15 |
8 |
9 |
20000 |
CREATE CONSTRAINT uniqueConstraint FOR (node:`UNIQUE IMPORT LABEL`) REQUIRE (node.`UNIQUE IMPORT ID`) IS UNIQUE;
UNWIND [{_id:0, properties:{tagline:"Welcome to the Real World", title:"The Matrix", released:1999}}] AS row
MERGE (n:`UNIQUE IMPORT LABEL`{`UNIQUE IMPORT ID`: row._id}) SET n += row.properties SET n:Movie;
UNWIND [{_id:80, properties:{born:1960, name:"Hugo Weaving"}},
{_id:7, properties:{born:1967, name:"Carrie-Anne Moss"}},
{_id:44, properties:{born:1961, name:"Laurence Fishburne"}},
{_id:27, properties:{born:1964, name:"Keanu Reeves"}}] AS row
MERGE (n:`UNIQUE IMPORT LABEL`{`UNIQUE IMPORT ID`: row._id}) SET n += row.properties SET n:Person;
UNWIND [{start: {_id:27}, end: {_id:0}, properties:{roles:["Neo"]}},
{start: {_id:7}, end: {_id:0}, properties:{roles:["Trinity"]}},
{start: {_id:44}, end: {_id:0}, properties:{roles:["Morpheus"]}},
{start: {_id:80}, end: {_id:0}, properties:{roles:["Agent Smith"]}}] AS row
MATCH (start:`UNIQUE IMPORT LABEL`{`UNIQUE IMPORT ID`: row.start._id})
MATCH (end:`UNIQUE IMPORT LABEL`{`UNIQUE IMPORT ID`: row.end._id})
MERGE (start)-[r:ACTED_IN]->(end) SET r += row.properties;
MATCH (n:`UNIQUE IMPORT LABEL`) WITH n LIMIT 20000 REMOVE n:`UNIQUE IMPORT LABEL` REMOVE n.`UNIQUE IMPORT ID`;
DROP CONSTRAINT uniqueConstraint;如果目标数据库中已存在节点,我们可以使用 cypherFormat: "addStructure" 仅为关系创建 Cypher CREATE 语句。
以下示例使用 addStructure 格式将 ACTED_IN 关系和周围节点导出到 export-cypher-format-addStructure.cypher
MATCH (person)-[r:ACTED_IN]->(movie)
WITH collect(DISTINCT person) + collect(DISTINCT movie) AS importNodes, collect(r) AS importRels
CALL apoc.export.cypher.data(importNodes, importRels,
"export-cypher-format-addStructure.cypher",
{ format: "plain", cypherFormat: "addStructure" })
YIELD file, batches, source, format, nodes, relationships, properties, time, rows, batchSize
RETURN file, batches, source, format, nodes, relationships, properties, time, rows, batchSize;| file | batches | source | format | nodes | relationships | properties | time | rows | batchSize |
|---|---|---|---|---|---|---|---|---|---|
"export-cypher-format-addStructure.cypher" |
1 |
"data: nodes(5), rels(4)" |
"cypher" |
5 |
4 |
15 |
4 |
9 |
20000 |
UNWIND [{_id:0, properties:{tagline:"Welcome to the Real World", title:"The Matrix", released:1999}}] AS row
MERGE (n:`UNIQUE IMPORT LABEL`{`UNIQUE IMPORT ID`: row._id}) ON CREATE SET n += row.properties SET n:Movie;
UNWIND [{_id:7, properties:{born:1967, name:"Carrie-Anne Moss"}},
{_id:27, properties:{born:1964, name:"Keanu Reeves"}},
{_id:80, properties:{born:1960, name:"Hugo Weaving"}},
{_id:44, properties:{born:1961, name:"Laurence Fishburne"}}] AS row
MERGE (n:`UNIQUE IMPORT LABEL`{`UNIQUE IMPORT ID`: row._id}) ON CREATE SET n += row.properties SET n:Person;
UNWIND [{start: {_id:27}, end: {_id:0}, properties:{roles:["Neo"]}},
{start: {_id:7}, end: {_id:0}, properties:{roles:["Trinity"]}},
{start: {_id:44}, end: {_id:0}, properties:{roles:["Morpheus"]}},
{start: {_id:80}, end: {_id:0}, properties:{roles:["Agent Smith"]}}] AS row
MATCH (start:`UNIQUE IMPORT LABEL`{`UNIQUE IMPORT ID`: row.start._id})
MATCH (end:`UNIQUE IMPORT LABEL`{`UNIQUE IMPORT ID`: row.end._id})
CREATE (start)-[r:ACTED_IN]->(end) SET r += row.properties;在此示例中,我们使用 MERGE 子句在节点不存在时创建它,并且仅在节点不存在时才创建属性。在此示例中,关系在目标数据库中不存在,需要创建。
如果这些关系确实存在但具有需要更新的属性,我们可以使用 cypherFormat: "updateStructure" 来创建我们的导入脚本。
以下示例使用 updateStructure 格式将 ACTED_IN 关系和周围节点导出到 export-cypher-format-updateStructure.cypher
MATCH (person)-[r:ACTED_IN]->(movie)
WITH collect(DISTINCT person) + collect(DISTINCT movie) AS importNodes, collect(r) AS importRels
CALL apoc.export.cypher.data(importNodes, importRels,
"export-cypher-format-updateStructure.cypher",
{ format: "plain", cypherFormat: "updateStructure" })
YIELD file, batches, source, format, nodes, relationships, properties, time, rows, batchSize
RETURN file, batches, source, format, nodes, relationships, properties, time, rows, batchSize;| file | batches | source | format | nodes | relationships | properties | time | rows | batchSize |
|---|---|---|---|---|---|---|---|---|---|
"export-cypher-format-updateStructure.cypher" |
1 |
"data: nodes(5), rels(4)" |
"cypher" |
0 |
4 |
4 |
2 |
4 |
20000 |
UNWIND [{start: {_id:27}, end: {_id:0}, properties:{roles:["Neo"]}},
{start: {_id:7}, end: {_id:0}, properties:{roles:["Trinity"]}},
{start: {_id:44}, end: {_id:0}, properties:{roles:["Morpheus"]}},
{start: {_id:80}, end: {_id:0}, properties:{roles:["Agent Smith"]}}] AS row
MATCH (start:`UNIQUE IMPORT LABEL`{`UNIQUE IMPORT ID`: row.start._id})
MATCH (end:`UNIQUE IMPORT LABEL`{`UNIQUE IMPORT ID`: row.end._id})
MERGE (start)-[r:ACTED_IN]->(end) SET r += row.properties;