图感知金融流失预测模型
面临的挑战
客户流失(Customer Churn/Attrition)是指客户停止与公司开展业务的现象。在金融和零售银行领域,获取新客户的成本远高于留住现有客户,因此流失预测是一项至关重要的任务。
然而,与基于订阅的行业(如 Netflix 或 Spotify)相比,金融流失具有独特的挑战:
-
静默流失(休眠): 在银行业,流失往往是非合同性的。客户很少会打电话说“我要离开了”。相反,他们只是停止使用银行卡、转移工资发放账户,或让账户长时间处于休眠状态。因此,金融流失预测的核心实际上是检测休眠,即识别出那些活跃度下降到事实上已经流失程度的用户。
-
类不平衡(Class Imbalance): 在一家健康的金融机构中,绝大多数客户(95% 到 99%)是活跃的。这种极端的“类不平衡”使得传统的机器学习模型难以识别流失者的特征(这无异于大海捞针)。
-
行为因素 vs. 结构因素: 传统方法(如 RFM 分析)通常孤立地看待客户,忽略了网络效应。例如,如果一个用户的家庭更换了银行,或者用户停止在关键的“高粘性”商户(如每日通勤火车)消费,这些结构性变化是流失的强预测因子,而表格数据往往会忽略这些信息。
解决方案
本解决方案利用 Neo4j 图数据科学 (GDS),通过将交易模式分析为图来预测客户流失。与仅查看个人人口统计数据的传统方法不同,该方法使用图特征来理解用户、卡片和商户之间的关系。
通过识别表现出过往流失用户结构模式的活跃用户,金融机构可以采取主动措施,例如通过精准营销或个性化优惠,在客户进入休眠状态之前留住高价值客户。
数据模型与网络结构
该解决方案的基础是一个捕获资金流向的图数据模型。数据集包括 User(用户)、Card(卡片)、Merchant(商户)和 Transaction(交易)节点。
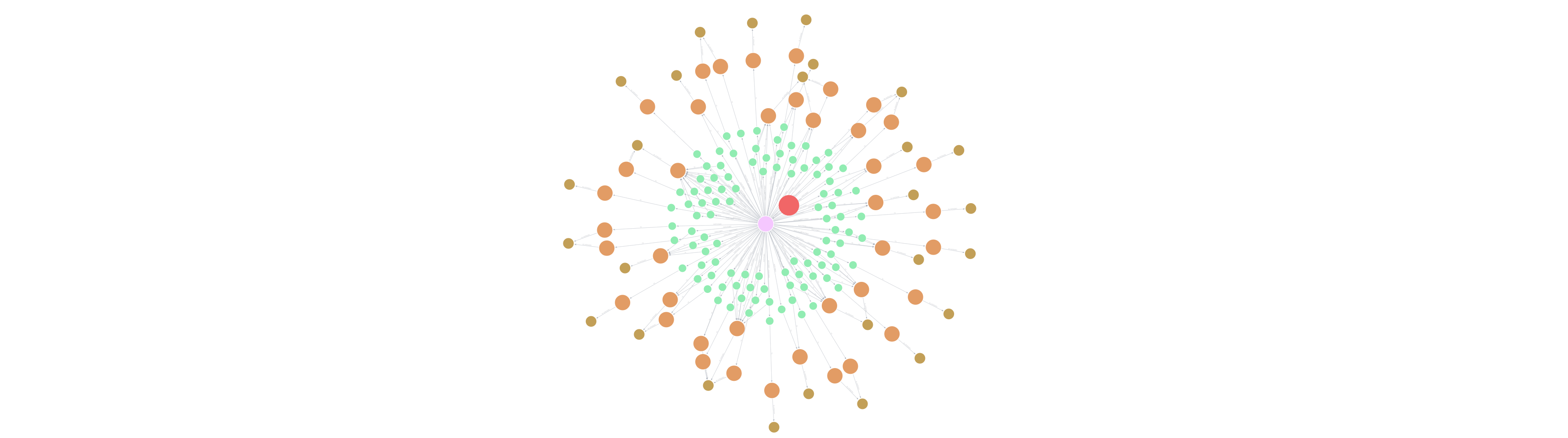
驱动分析的主要关系包括:
-
(:User)-[:OWNS]→(:Card) -
(:Card)-[:PERFORMED]→(:Transaction) -
(:Transaction)-[:TO]→(:Merchant)
为了优化图数据科学算法,该流程构建了一个简化的加权网络:(:User)-[:SHOPPED_AT {weight: count}]→(:Merchant)
这一投影使算法能够分析用户对特定商户的忠诚度,以及基于共同购物习惯的用户相似性。
方法论:图数据科学流水线
该解决方案在 Neo4j 内部实现了一个完整的端到端流水线,由 Neo4j Python 客户端进行编排。
1. 处理类不平衡
为了解决流失样本稀缺的问题,流水线创建了一个平衡的训练队列(Training Cohort)。它选取 100% 的历史流失用户,并对活跃用户进行欠采样(例如只选取其中的 5%),从而创建一个平衡的数据集。这使得分类器能够学习流失者的特定特征,而不会被多数类淹没。
2. 图特征工程
模型不再仅仅依赖静态人口统计数据(收入、债务、信用评分),而是使用通过 GDS 算法计算出的拓扑特征来丰富数据:
-
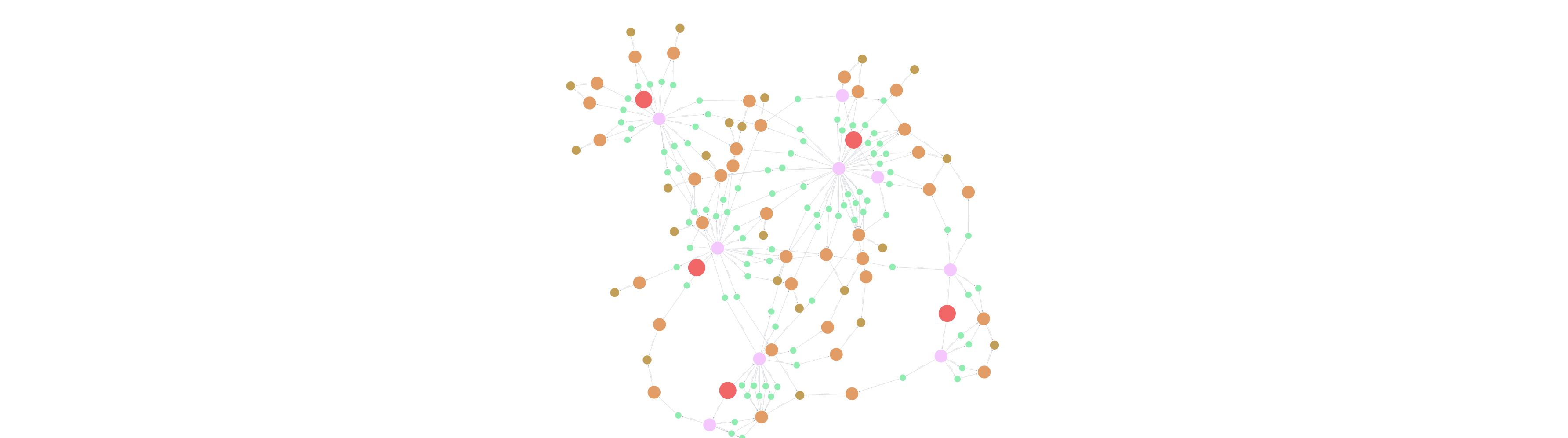
FastRP(快速随机投影): 该算法为用户和商户生成 32 维节点嵌入。这些嵌入捕捉了复杂的图拓扑结构,有效地将“用户在哪里购物”和“用户购物习惯像谁”转换成机器学习模型可以处理的数值向量。这捕捉到了行为相似的潜在用户社区。
-
PageRank & 中心性: PageRank 用于衡量交易网络中节点的权力和中心性。在特定商户社区中具有高中心性的用户可能是“潮流引领者”或“大客户”,他们的行为高度预示着更广泛的趋势。
-
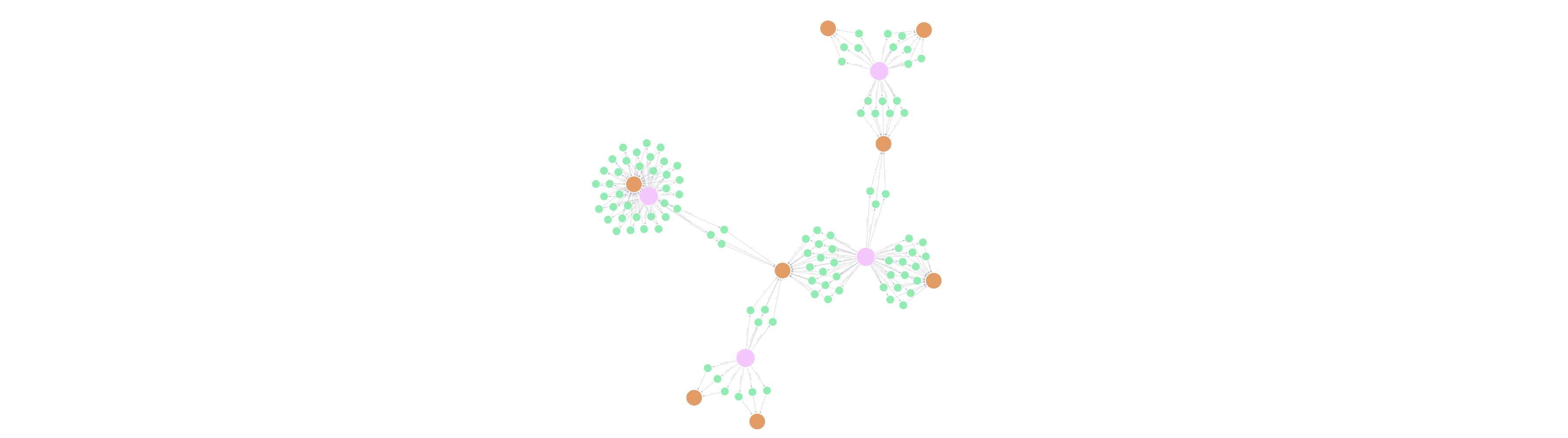
地理空间与时间特征: 该模型还结合了地理空间数据(
user_latitude,user_longitude)和时间趋势(比较最近 30 天与之前 30 天的交易计数和金额),以检测活跃度的突然下降。
业务效益
-
早期检测: 识别出那些仍然活跃但表现出与已流失用户相似行为模式的“高危”客户(例如断开与关键商户的联系)。
-
全方位的客户视角: 超越简单的“账户余额”指标,了解客户关系的结构性健康状况。
-
运营效率: 通过在 Neo4j 内部运行整个流水线(ETL、特征工程、训练和推理),最大限度地减少了数据移动,从而支持更频繁的模型重训和实时风险评分。
资源
-
图数据科学库: Neo4j GDS 文档