LangChain Neo4j 集成
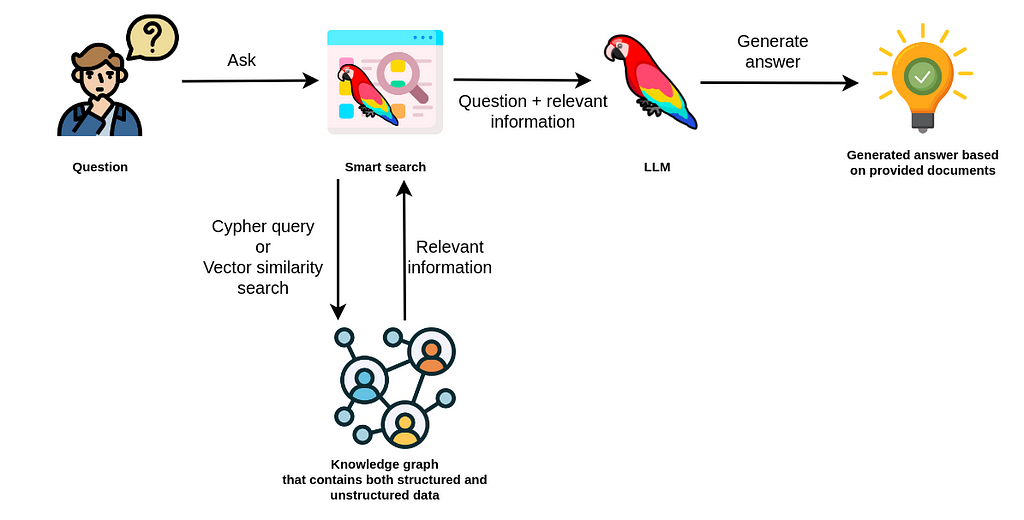
LangChain 是一个用于 GenAI 编排的庞大库,支持众多的 LLM、向量存储、文档加载器和代理。它管理模板,将组件组合成链,并支持监控和可观测性。
广泛且深入的 Neo4j 集成支持向量搜索、Cypher 生成、数据库查询以及知识图谱构建。
这里是 图集成 的概述。
| 升级到 LangChain 0.1.0+ 时,请务必阅读本文:将 GraphAcademy Neo4j 和 LLM 课程更新至 Langchain v0.1。 |

安装
pip install langchain langchain-community langchain-neo4j
# pip install langchain-openai tiktoken
# pip install neo4j功能包括
Neo4jVector
Neo4j 向量集成支持多种操作:
-
从 LangChain 文档创建向量
-
向量查询
-
结合额外图检索 Cypher 查询的向量查询
-
从现有图数据构建向量实例
-
混合搜索
-
元数据过滤
from langchain.docstore.document import Document
from langchain.text_splitter import CharacterTextSplitter
from langchain_community.document_loaders import TextLoader
from langchain_neo4j import Neo4jVector
from langchain_openai import OpenAIEmbeddings
loader = TextLoader("../../modules/state_of_the_union.txt")
documents = loader.load()
text_splitter = CharacterTextSplitter(chunk_size=1000, chunk_overlap=0)
docs = text_splitter.split_documents(documents)
embeddings = OpenAIEmbeddings()
# The Neo4jVector Module will connect to Neo4j and create a vector index if needed.
db = Neo4jVector.from_documents(
docs, embeddings, url=url, username=username, password=password
)
query = "What did the president say about Ketanji Brown Jackson"
docs_with_score = db.similarity_search_with_score(query, k=2)混合搜索
混合搜索结合了向量搜索与全文搜索,并包含结果的重排序和去重。
from langchain.docstore.document import Document
from langchain.text_splitter import CharacterTextSplitter
from langchain_community.document_loaders import TextLoader
from langchain_neo4j import Neo4jVector
from langchain_openai import OpenAIEmbeddings
loader = TextLoader("../../modules/state_of_the_union.txt")
documents = loader.load()
text_splitter = CharacterTextSplitter(chunk_size=1000, chunk_overlap=0)
docs = text_splitter.split_documents(documents)
embeddings = OpenAIEmbeddings()
# The Neo4jVector Module will connect to Neo4j and create a vector index if needed.
db = Neo4jVector.from_documents(
docs, embeddings, url=url, username=username, password=password,
search_type="hybrid"
)
query = "What did the president say about Ketanji Brown Jackson"
docs_with_score = db.similarity_search_with_score(query, k=2)元数据过滤
元数据过滤通过允许基于特定节点属性优化搜索,增强了向量搜索。这种集成方法通过同时利用向量相似性和节点的上下文属性,确保了更精确、更相关的搜索结果。
db = Neo4jVector.from_documents(
docs,
OpenAIEmbeddings(),
url=url, username=username, password=password
)
query = "What did the president say about Ketanji Brown Jackson"
filter = {"name": {"$eq": "adam"}}
docs = db.similarity_search(query, filter=filter)Neo4j Graph
Neo4j 图集成是 Neo4j Python 驱动程序的封装。它允许以简化的方式从 LangChain 查询和更新 Neo4j 数据库。许多集成允许您将 Neo4j 图作为 LangChain 的数据源使用。
from langchain_neo4j import Neo4jGraph
graph = Neo4jGraph(url=NEO4J_URI, username=NEO4J_USERNAME, password=NEO4J_PASSWORD)
QUERY = """
MATCH (m:Movie)-[:IN_GENRE]->(:Genre {name: $genre})
RETURN m.title, m.plot
ORDER BY m.imdbRating DESC LIMIT 5
"""
graph.query(QUERY, params={"genre": "action"})CypherQAChain
CypherQAChain 是一个 LangChain 组件,允许您使用自然语言与 Neo4j 图数据库进行交互。它使用 LLM 和图谱模式将用户问题转换为 Cypher 查询,针对图谱执行该查询,并利用返回的上下文信息和原始问题,通过第二个 LLM 生成自然语言回复。
# pip install --upgrade --quiet langchain
# pip install --upgrade --quiet langchain-openai
from langchain_neo4j import Neo4jGraph, GraphCypherQAChain
from langchain_openai import ChatOpenAI
graph = Neo4jGraph(url=NEO4J_URI, username=NEO4J_USERNAME, password=NEO4J_PASSWORD)
# Insert some movie data
graph.query(
"""
MERGE (m:Movie {title:'Top Gun'})
WITH m
UNWIND ['Tom Cruise', 'Val Kilmer', 'Anthony Edwards', 'Meg Ryan'] AS actor
MERGE (a:Actor {name:actor})
MERGE (a)-[:ACTED_IN]->(m)
"""
)
chain = GraphCypherQAChain.from_llm(
ChatOpenAI(temperature=0), graph=graph, verbose=True,
allow_dangerous_requests=True
)
chain.run("Who acted in Top Gun?")高级 RAG 策略
除了基础的 RAG 策略外,LangChain 中的 Neo4j 集成还支持高级 RAG 策略,从而实现更复杂的检索策略。这些也以 LangChain 模板的形式提供。
-
常规 RAG - 直接向量搜索
-
父子检索器 (parent - child retriever) - 将表示特定概念的嵌入块链接到父文档
-
假设性问题 - 从文档块生成问题并对其进行向量索引,以便为用户的问题找到更好的匹配候选者
-
摘要 - 索引文档的摘要而非完整文档
pip install -U "langchain-cli[serve]"
langchain app new my-app --package neo4j-advanced-rag
# update server.py to add the neo4j-advanced-rag template as an endpoint
cat <<EOF > server.py
from fastapi import FastAPI
from langserve import add_routes
from neo4j_advanced_rag import chain as neo4j_advanced_chain
app = FastAPI()
# Add this
add_routes(app, neo4j_advanced_chain, path="/neo4j-advanced-rag")
if __name__ == "__main__":
import uvicorn
uvicorn.run(app, host="0.0.0.0", port=8000)
EOF
langchain serve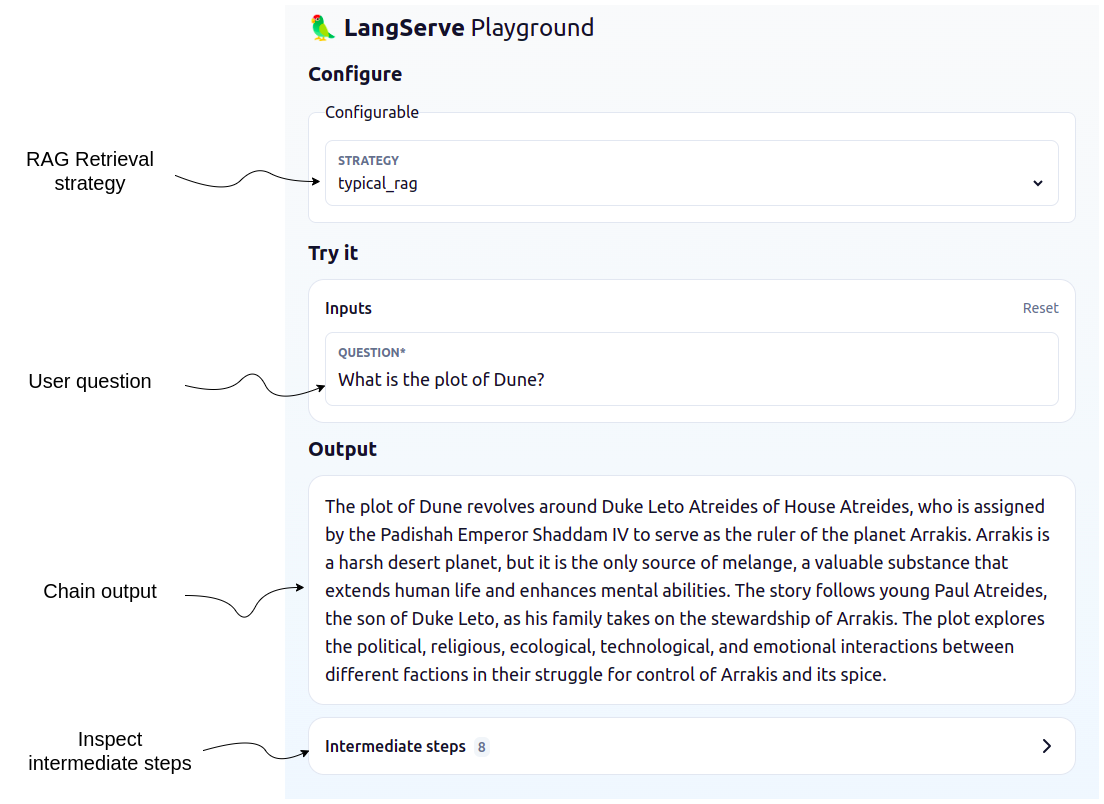
语义层
(图)数据库之上的语义层不依赖于自动查询生成,而是提供多种 API 和工具,让 LLM 能够访问数据库及其结构。
与自动生成的查询不同,这些工具使用起来很安全,因为它们是使用正确的查询和交互实现的,并且仅从 LLM 获取参数。
许多云(LLM)提供商通过函数调用(OpenAI、Anthropic)或扩展(Google Vertex AI、AWS Bedrock)提供类似的集成。
此类工具或函数的示例包括:
-
检索具有特定名称的实体
-
检索节点的邻居
-
检索两个节点之间的最短路径
对话记忆
在图中存储对话(即用户会话的问题和答案流)允许您分析对话历史记录,并将其用于改善用户体验。
您可以为问题和答案创建嵌入索引,并将它们链接回图中检索到的块和实体,并利用用户反馈来重新排序这些输入,以用于未来类似的问题。
知识图谱构建
从 PDF 文档等非结构化数据创建知识图谱曾经是一项复杂且耗时的任务,需要训练和使用专门的大型 NLP 模型。
图转换器 (Graph Transformers) 是一些工具,允许您从非结构化文档中提取结构化数据并将其转换为知识图谱。
| 您可以查看使用 LLM Graph Builder 从 PDF、YouTube 转录稿、维基百科文章等提取知识图谱的实际应用、代码和演示。 |
入门套件
此 入门套件 (starter-kit) 展示了如何使用 LangChain 运行 FastAPI 服务器,以回答存储在 Neo4j 实例中的数据查询。该单一端点可用于通过 向量索引链、GraphCypherQA 链 或两者的复合答案来检索答案。langserve 分支包含使用 LangServe 的相同服务示例。
有关使用入门套件的更多详细信息和说明,请参阅此 开发者博客文章。
相关链接
作者 |
|
社区支持 |
|
LangChain 仓库 |
|
LangChain 问题反馈 |
|
LangChain Neo4j 仓库 |
|
LangChain Neo4j API 文档 |
|
LangChain Neo4j 问题反馈 |
|
文档 |
|
文档 |
|
入门套件 |
|
Jupyter |