LangChain Neo4j 集成
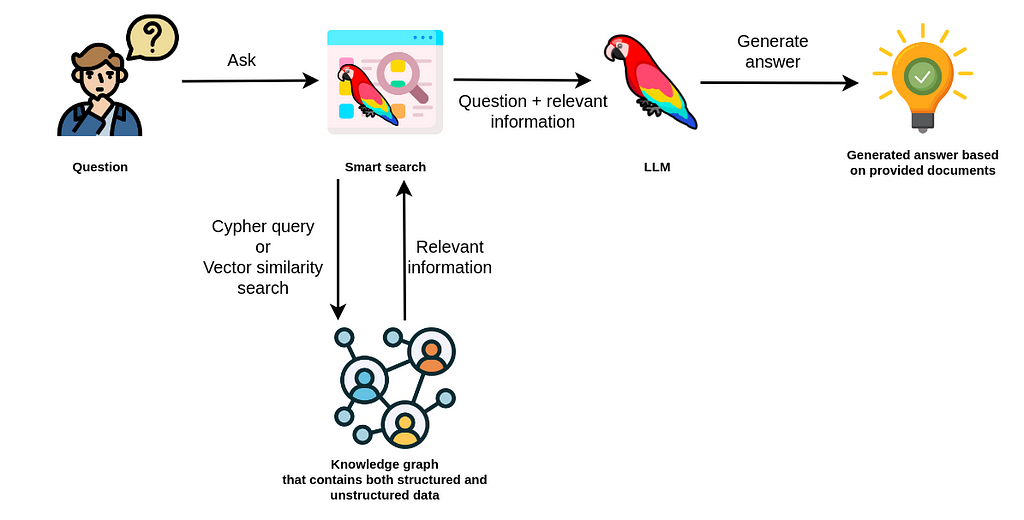
LangChain 是一个用于 GenAI 编排的庞大库,支持众多的 LLM、向量存储、文档加载器和代理。它管理模板,将组件组合成链,并支持监控和可观测性。
广泛而深入的 Neo4j 集成支持向量搜索、Cypher 生成、数据库查询以及知识图谱构建。
这是 图集成 (Graph Integrations) 的概述。
| 升级到 LangChain 0.1.0+ 时,请务必阅读本文:将 GraphAcademy Neo4j & LLM 课程更新至 Langchain v0.1。 |

安装
pip install langchain langchain-community
# pip install langchain-openai tiktoken
# pip install neo4j功能包括
Neo4jVector
Neo4j 向量集成支持多种操作:
-
从 LangChain 文档创建向量
-
向量查询
-
结合额外图检索 Cypher 查询的向量查询
-
从现有图数据构建向量实例
-
混合搜索
-
元数据过滤
from langchain.docstore.document import Document
from langchain.text_splitter import CharacterTextSplitter
from langchain_community.document_loaders import TextLoader
from langchain_community.vectorstores import Neo4jVector
from langchain_openai import OpenAIEmbeddings
loader = TextLoader("../../modules/state_of_the_union.txt")
documents = loader.load()
text_splitter = CharacterTextSplitter(chunk_size=1000, chunk_overlap=0)
docs = text_splitter.split_documents(documents)
embeddings = OpenAIEmbeddings()
# The Neo4jVector Module will connect to Neo4j and create a vector index if needed.
db = Neo4jVector.from_documents(
docs, OpenAIEmbeddings(), url=url, username=username, password=password
)
query = "What did the president say about Ketanji Brown Jackson"
docs_with_score = db.similarity_search_with_score(query, k=2)混合搜索
混合搜索结合了向量搜索与全文搜索,并包含结果的重排序和去重。
from langchain.docstore.document import Document
from langchain.text_splitter import CharacterTextSplitter
from langchain_community.document_loaders import TextLoader
from langchain_community.vectorstores import Neo4jVector
from langchain_openai import OpenAIEmbeddings
loader = TextLoader("../../modules/state_of_the_union.txt")
documents = loader.load()
text_splitter = CharacterTextSplitter(chunk_size=1000, chunk_overlap=0)
docs = text_splitter.split_documents(documents)
embeddings = OpenAIEmbeddings()
# The Neo4jVector Module will connect to Neo4j and create a vector index if needed.
db = Neo4jVector.from_documents(
docs, OpenAIEmbeddings(), url=url, username=username, password=password,
search_type: 'hybrid'
)
query = "What did the president say about Ketanji Brown Jackson"
docs_with_score = db.similarity_search_with_score(query, k=2)元数据过滤
元数据过滤通过允许基于特定节点属性优化搜索,增强了向量搜索。这种集成方法通过同时利用向量相似性和节点的上下文属性,确保了更精确、更相关的搜索结果。
db = Neo4jVector.from_documents(
docs,
OpenAIEmbeddings(),
url=url, username=username, password=password
)
query = "What did the president say about Ketanji Brown Jackson"
filter = {"name": {"$eq": "adam"}}
docs = db.similarity_search(query, filter=filter)Neo4j Graph
Neo4j Graph 集成是 Neo4j Python 驱动程序的包装器。它允许以简化方式从 LangChain 查询和更新 Neo4j 数据库。许多集成允许您将 Neo4j Graph 用作 LangChain 的数据源。
from langchain_community.graphs import Neo4jGraph
graph = Neo4jGraph(url=NEO4J_URI, username=NEO4J_USERNAME, password=NEO4J_PASSWORD)
QUERY = """
"MATCH (m:Movie)-[:IN_GENRE]->(:Genre {name:$genre})
RETURN m.title, m.plot
ORDER BY m.imdbRating DESC LIMIT 5"
"""
graph.query(QUERY, genre="action")CypherQAChain
CypherQAChain 是一个 LangChain 组件,允许您使用自然语言与 Neo4j 图数据库进行交互。它使用 LLM 和图谱模式将用户问题转换为 Cypher 查询,针对图谱执行该查询,并利用返回的上下文信息和原始问题,通过第二个 LLM 生成自然语言回复。
# pip install --upgrade --quiet langchain
# pip install --upgrade --quiet langchain-openai
from langchain.chains import GraphCypherQAChain
from langchain_community.graphs import Neo4jGraph
from langchain_openai import ChatOpenAI
graph = Neo4jGraph(url=NEO4J_URI, username=NEO4J_USERNAME, password=NEO4J_PASSWORD)
# Insert some movie data
graph.query(
"""
MERGE (m:Movie {title:"Top Gun"})
WITH m
UNWIND ["Tom Cruise", "Val Kilmer", "Anthony Edwards", "Meg Ryan"] AS actor
MERGE (a:Actor {name:actor})
MERGE (a)-[:ACTED_IN]->(m)
"""
)
chain = GraphCypherQAChain.from_llm(
ChatOpenAI(temperature=0), graph=graph, verbose=True
)
chain.run("Who played in Top Gun?")高级 RAG 策略
除了基础 RAG 策略外,LangChain 中的 Neo4j 集成还支持高级 RAG 策略,允许实现更复杂的检索方案。这些策略也可作为 LangChain 模板使用。
-
常规 RAG - 直接向量搜索
-
父子检索器 (Parent-Child Retriever) - 将代表特定概念的嵌入分块链接到父文档
-
假设性问题 (Hypothetical questions) - 从文档分块生成问题并对其进行向量索引,以便为用户问题找到更好的匹配候选项
-
摘要 (Summary) - 索引文档的摘要,而非整个文档
-
https://python.langchain.ac.cn/docs/templates/neo4j-advanced-rag
pip install -U "langchain-cli[serve]"
langchain app new my-app --package neo4j-advanced-rag
# update server.py to add the neo4j-advanced-rag template as an endpoint
cat <<EOF > server.py
from fastapi import FastAPI
from langserve import add_routes
from neo4j_advanced_rag import chain as neo4j_advanced_chain
app = FastAPI()
# Add this
add_routes(app, neo4j_advanced_chain, path="/neo4j-advanced-rag")
if __name__ == "__main__":
import uvicorn
uvicorn.run(app, host="0.0.0.0", port=8000)
EOF
langchain serve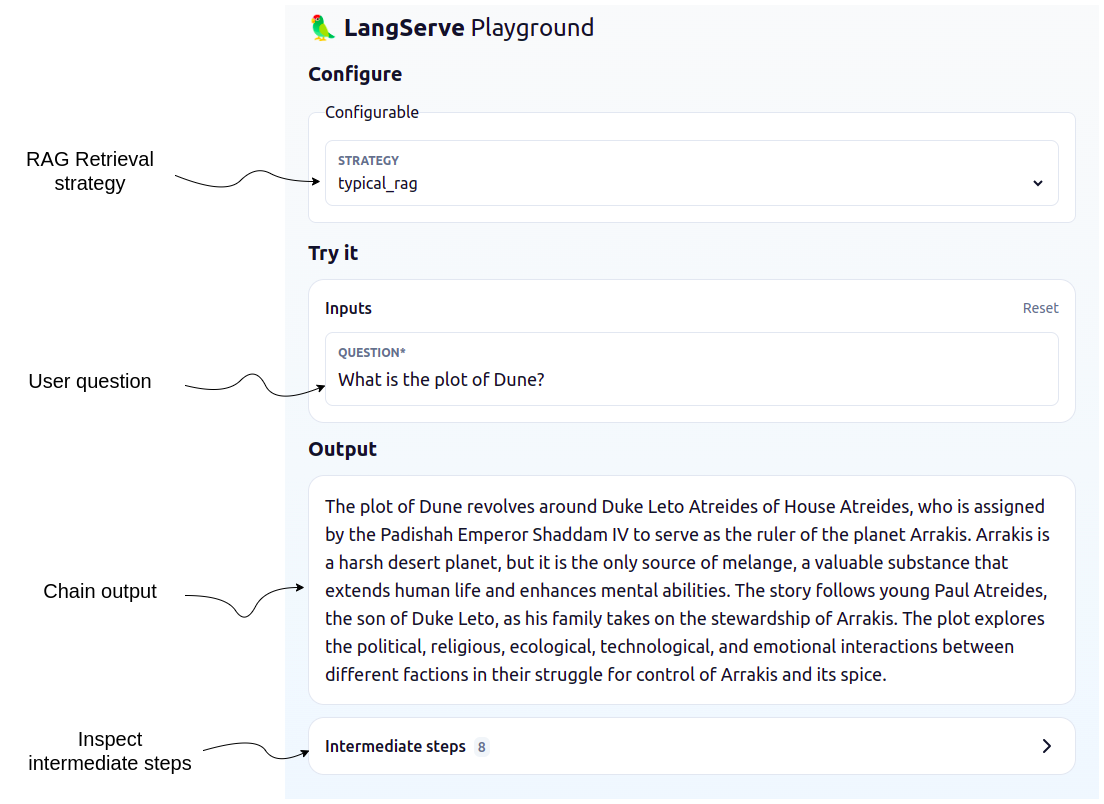
LangChain 模板
Langchain 模板 是一组预配置的链和组件,可用于构建 GenAI 工作流和应用程序。您可以在 LangChain Playground 中交互式测试它们,并通过 LangServe 将其作为 REST API 运行;它们还与 [LangSmith] 集成以实现监控和可观测性。
通过从模板创建应用程序,其源代码会被添加到您的应用程序中,您可以根据需要进行修改。
模板列表
此 Cypher 模板 允许您使用 OpenAI LLM 以自然语言与 Neo4j 图数据库交互。
它将自然语言问题转换为 Cypher 查询(用于从 Neo4j 数据库获取数据),执行查询,并根据查询结果提供自然语言响应。
Cypher-FT 模板 额外利用了全文索引,以高效地将文本值映射到数据库条目,从而增强了准确 Cypher 语句的生成。
Cypher 记忆模板 还具备对话记忆模块,将对话历史存储在 Neo4j 图数据库中。对话记忆针对每个用户会话进行独立维护,确保了个性化的交互。
Neo4j 生成模板 将基于 OpenAI 函数的 LLM 知识图谱提取与全托管云图数据库 Neo4j AuraDB 相结合。
Neo4j 向量记忆模板 允许您将 LLM 与使用 Neo4j 作为向量存储的向量检索系统集成。此外,它利用 Neo4j 数据库的图功能来存储和检索特定用户会话的对话历史。将对话历史存储为图谱不仅能实现流畅的对话流程,还使您能够通过图分析来分析用户行为和文本分块检索。
父子检索器模板 允许您通过将文档拆分为较小的块并检索其原始或更大的文本信息,来平衡精确嵌入和上下文保留。
该包使用 Neo4j 向量索引通过向量相似性搜索查询子节点,并检索对应的父级文本。
Neo4j 语义层模板 旨在实现一个代理,通过使用 OpenAI 函数调用的语义层与 Neo4j 等图数据库进行交互。语义层为代理配备了一套强大的工具,使其能够根据用户的意图与图数据库进行交互。
语义层
位于(图)数据库之上的语义层不依赖自动查询生成,而是提供多种 API 和工具,使 LLM 能够访问数据库及其结构。
与自动生成的查询不同,这些工具使用起来是安全的,因为它们通过正确的查询和交互实现,并且只接收来自 LLM 的参数。
许多云(LLM)提供商通过函数调用(OpenAI, Anthropic)或扩展(Google Vertex AI, AWS Bedrock)提供类似的集成。
此类工具或函数的示例包括:
-
检索具有特定名称的实体
-
检索节点的邻居
-
检索两个节点之间的最短路径
对话记忆
将对话(即用户会话的问题和答案流程)存储在图谱中,使您能够分析对话历史并利用它来改善用户体验。
您可以为问题和答案创建嵌入索引,并将它们链接回图谱中检索到的分块和实体,并利用用户反馈来重新排序这些输入,以供后续类似问题使用。
知识图谱构建
从 PDF 文档等非结构化数据创建知识图谱曾经是一项复杂且耗时的任务,需要训练和使用专门的大型 NLP 模型。
图转换器 (Graph Transformers) 是允许您从非结构化文档中提取结构化数据并将其转换为知识图谱的工具。
| 您可以通过 LLM Graph Builder 查看提取 PDF、YouTube 字幕、维基百科文章等内容中知识图谱的实际应用、代码和演示。 |