FastPath
电梯演讲
FastPath 是一种运行在时序图上的轻量级路径嵌入(path embedding)算法。它计算与事件序列相关联的基础节点(base nodes)的嵌入。事件根据其类型以及事件发生后经过的时间(连续变化)与向量相关联。这些向量被聚合成嵌入,可用于机器学习任务(如客户旅程分析),并能跨越不同时间段进行泛化。
图术语简注
FastPath 算法在概念上作用于图,因此本文档讨论图、节点、关系和属性。此外,这些图是异构的,因此节点标有节点标签,关系也有类型。图与实际 Snowflake 表之间的对应关系在 [_node_tables] 和 [_relationship_tables] 章节中进行了描述。
简介
FastPath 是一种路径嵌入算法。这意味着输入图是一个时序图,包含:
-
基础节点 (base nodes) — 算法旨在为其计算嵌入的目标节点
-
事件节点 (event nodes) — 标记有时间戳并与基础节点相关联的节点
支持两种图模式来编码事件链。
事件节点可以包含有关事件具体内容的信息。此信息可以采用特征向量、分类属性或与上下文节点的关系的形式。
总之,输入由一组基础节点组成,每个基础节点都有一个携带信息事件的时间序列。
对于每个基础节点,都会指定一个输出时间(output time)。输出时间控制嵌入的两个关注点。首先,仅使用直至输出时间的事件来得出嵌入。其次,算法使用经过的时间(elapsed time)而非绝对时间来计算嵌入。在确定事件对基础节点嵌入的贡献时,经过的时间是该事件与基础节点输出时间之间的时间间隔。
让我们考虑一个例子来更清楚地说明这一点:其中一个基础节点是一个叫“Joe”的人,其中一个事件代表“Joe服用了一剂阿司匹林”的事实。算法将存储:
-
事件类型 — 此处为“服用阿司匹林”
-
经过的时间 — 此处为 7 天
此外,每对事件类型和经过时间都与一个“半随机”向量相关联。这些向量是利用随机性(类似于所谓的 FastRP 算法)和时间平滑机制构建的。这使得“7天前服用阿司匹林”的向量与“8天前服用阿司匹林”的向量(相对)相似。
Joe 的嵌入将是“7天前服用阿司匹林”的向量与 Joe 发生的所有其他事件向量的加权和。权重的工作方式将在下文详细描述。
这看起来可能仅提供了对分类属性和上下文节点关系等离散事件信息的直觉。然而,事件上的特征向量可以被视为对应于向量分量的离散事件的加权和。
输出的节点嵌入可用于下游的机器学习任务,以解决与客户旅程等相关的问题。由于依赖于相对时间而非绝对时间,此类模型可以从过去图的嵌入泛化到当前图。此外,FastPath 在时间上是等变的;如果一个基础节点的所有事件都移动了 T 个时间步,并且输出时间也移动了 T 个时间步(方向相同),则基础节点的嵌入保持不变。
语法
本节介绍执行 FastPath 算法所使用的语法。
CALL graph.fastpath(
'CPU_X64_XS', (1)
{
['defaultTablePrefix': '...',] (2)
'project': {...}, (3)
'compute': {...}, (4)
'write': {...} (5)
}
);| 1 | 计算池选择器。 |
| 2 | 表引用的可选前缀。 |
| 3 | 项目配置。 |
| 4 | 计算配置。 |
| 5 | 写入配置。 |
| 名称 | 类型 | 默认 | 可选 | 描述 |
|---|---|---|---|---|
computePoolSelector |
字符串 |
|
否 |
运行 FastPath 作业的计算池选择器。 |
配置 |
Map |
|
否 |
用于图项目、算法计算和结果回写的配置。 |
配置映射由以下三个条目组成。
| 有关以下项目配置的更多详细信息,请参阅 项目文档。 |
| 名称 | 类型 |
|---|---|
nodeTables |
节点表列表。 |
relationshipTables |
关系类型到关系表的映射。 |
| 名称 | 类型 | 默认 | 可选 | 描述 |
|---|---|---|---|---|
resultProperty |
字符串 |
|
是 |
将写回 Snowflake 数据库的节点属性 |
baseNodeLabel |
字符串 |
|
否 |
需要输出嵌入的节点标签 |
eventNodeLabel |
字符串 |
|
否 |
与基础节点相关的事件节点标签 |
contextNodeLabel |
字符串 |
|
是 |
描述事件的上下文节点标签 |
timeNodeProperty |
字符串 |
|
是 |
事件节点上表示时间的节点属性名称。可以是 int 或 float 类型。 |
nextRelationshipType |
字符串 |
|
是 |
事件节点之间的关系类型名称,表示事件的顺序 |
firstRelationshipType |
字符串 |
|
是 |
从基础节点到事件节点的关系类型名称,表示每个基础节点的第一个事件 |
eventFeatures |
字符串 |
|
是 |
事件节点上持有向量形式数值特征的节点属性名称 |
categoricalEventProperties |
字符串列表 |
|
是 |
事件节点上持有分类值或分类值列表的节点属性名称 |
ignoredEventCategory |
整数 |
|
是 |
一个分类值,表示该类别缺失,在构建事件嵌入时被忽略 |
outputTime |
浮点数 |
|
是 |
应产生嵌入的时间戳。在此时间戳或之后发生的事件不会被处理。 |
outputTimeProperty |
字符串 |
|
是 |
基础节点上持有数字的节点属性名称,指示应针对哪个时间戳生成输出嵌入 |
numElapsedTimes |
整数 |
|
否 |
“网格”中的时间点数量。从事件到输出时间的经过时间会被舍入到该网格。如果设置为 1,事件的时间戳将不起作用。 |
decayFactor |
浮点数 |
|
是 |
控制旧事件影响力衰减速度的系数 |
maxElapsedTime |
整数 |
|
否 |
相对于输出时间,嵌入所考虑的事件的最大年龄。 |
smoothingWindow |
整数 |
|
是 |
事件嵌入是在包含最多 2*smoothingWindow + 1 个网格时间的窗口上聚合的。 |
smoothingRate |
浮点数 |
|
是 |
控制事件的预期相似度随其时间距离增加而衰减的速度。 |
dimension |
整数 |
|
否 |
嵌入的输出维度 |
randomSeed |
整数 |
|
是 |
用于计算嵌入中所有随机性的随机种子。 |
| 关于下文写入配置的更多详细信息,请参考 写入文档。 |
| 名称 | 类型 | 默认 | 可选 | 描述 |
|---|---|---|---|---|
nodeLabel |
字符串 |
|
否 |
内存中图中用于写入节点属性的节点标签。 |
outputTable |
字符串 |
|
否 |
Snowflake 数据库中写入节点属性的表。 |
配置概念说明
本节将更详细地介绍如何配置算法的特定方面。
图模式和关系配置
该算法支持两种不同的模式来连接基础节点和事件节点。
-
要使用第一种模式配置,请提供
firstRelationshipType和nextRelationshipType,而timeNodeProperty是可选的。在这种配置下,假定每个基础节点和事件节点都属于以下模式路径的一部分:(:baseNodeLabel)-[:firstRelationshipType]-(:eventNodeLabel)-[:nextRelationshipType]-…-[:nextRelationshipType]→(:eventNodeLabel)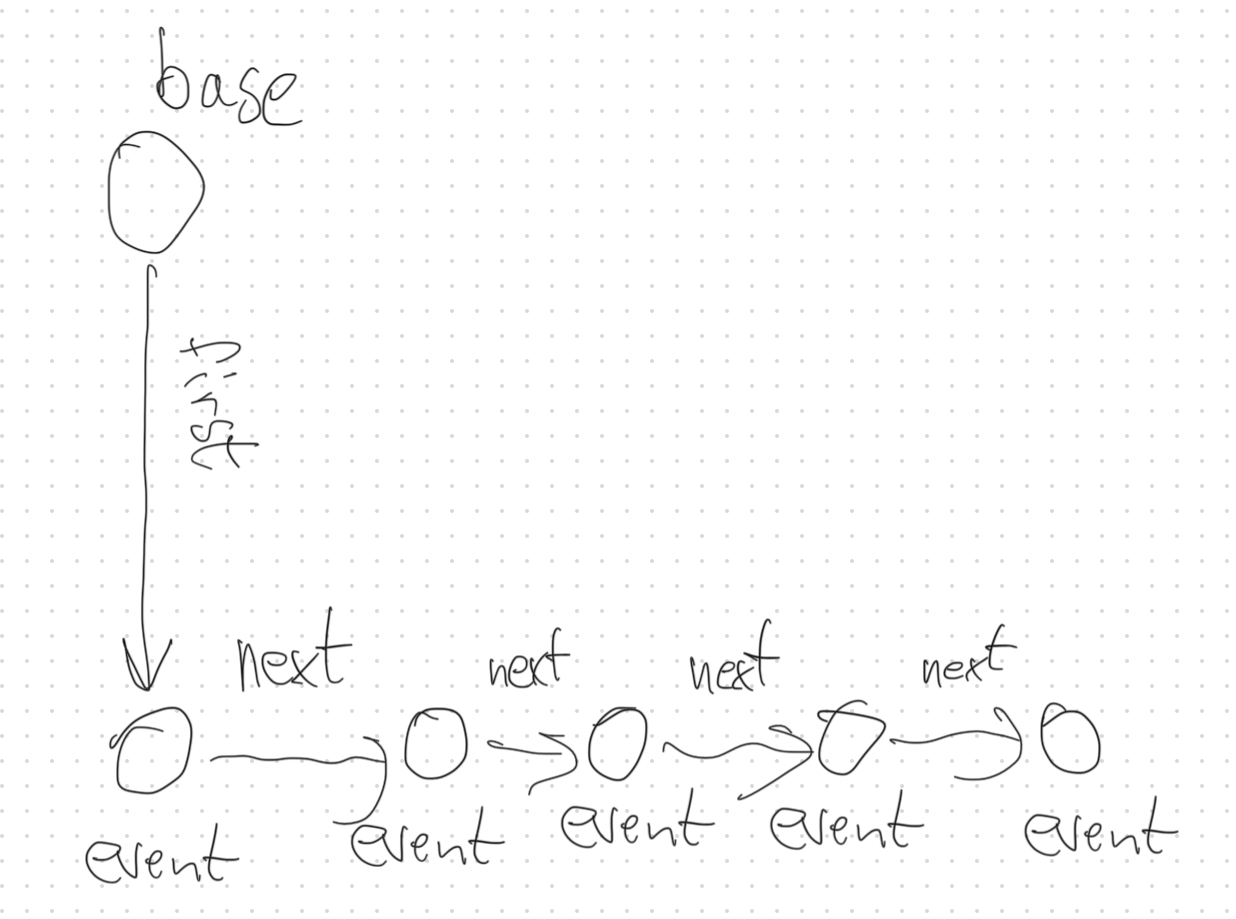
-
要使用第二种模式配置,仅提供
timeNodeProperty。然后假定每个基础节点都有到其每个事件节点的传出关系:(:baseNodeLabel)-[:]→(:eventNodeLabel)

可选地,模式还可以包含一个名为 contextNodeLabel 的节点标签,参见下方的 事件输入特征。
定义事件时间戳
有两种方法可以为事件节点指定时间戳。第一种方法是提供 timeNodeProperty,在这种情况下,每个事件节点必须持有一个代表时间戳的该名称属性。
但是,如果提供了 nextRelationshipType,则不必提供 timeNodeProperty。在这种情况下,时间戳将以如下图所示的直观方式生成。
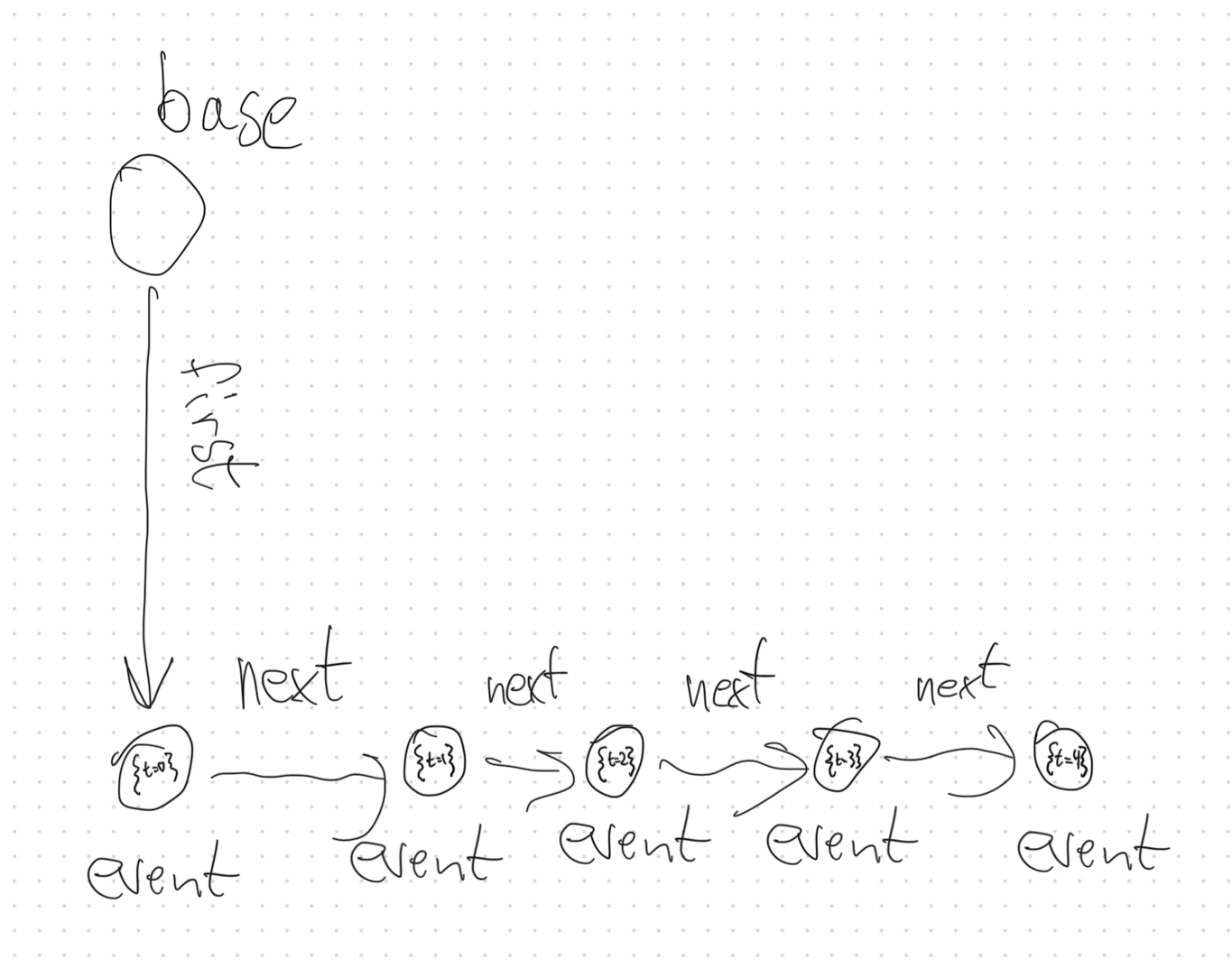
“时间戳生成”图示:到事件的 nextRelationshipType 路径长度将定义其时间戳。因此,通过 firstRelationshipType 关系从基础节点连接的事件链中的第一个事件节点的时间戳为 0。通过第一个事件节点的 nextRelationshipType 关系访问的下一个事件节点的时间戳为 1,依此类推。
请注意,即使使用了 nextRelationshipType,您仍然可以提供 timeNodeProperty。在这种情况下,nextRelationshipType 不会用于推断时间戳,而是用于确定事件节点所属的基础节点。
事件输入特征
事件的特征表示可能受到三个不同输入源的影响。它们彼此独立,既可以一起使用,也可以单独使用。事件特征向量将是所有已启用输入源的总和。
-
要启用上下文节点(Context nodes)输入源,请提供
contextNodeLabel。在这种情况下,假定可能存在从事件节点到上下文节点的传出关系,即以下模式:
(:eventNodeLabel)-[:]→(:contextNodeLabel) -
要启用事件特征向量属性(Event feature vector properties)输入源,请提供
eventFeatures。这应该是所有事件节点上存在的向量属性的名称。 -
要启用分类事件属性(Categorical event properties)输入源,请提供
categoricalEventProperties。这应该是持有代表类别的整数或此类整数列表的属性名称。该属性必须存在于所有事件节点上。
示例
假设我们有一个包含以下表的 Snowflake 模式 patient_db.general:
-
patient表,具有nodeid和output_time列 -
encounter表,具有nodeid、embedding和time列 -
has_encounter表,具有sourcenodeid和targetnodeid列
这些表代表医疗患者记录图。
要运行查询,需要为应用程序、您的消费者角色和您的环境设置必要的权限。请参阅 入门 页面以了解更多信息。
我们还假设应用程序名称为默认的 Neo4j_Graph_Analytics。如果您在安装过程中选择了不同的应用程序名称,请将其替换为该名称。
可以通过执行如下语句在此图上运行 FastPATH 算法:
CALL Neo4j_Graph_Analytics.graph.fastpath('CPU_X64_M', {
'defaultTablePrefix': 'patient_db.general',
'project': {
'nodeTables': ['patient', 'encounter'],
'relationshipTables': {
'has_encounter': {
'sourceTable': 'patient',
'targetTable': 'encounter'
}
}
},
'compute': {
'baseNodeLabel': 'patient',
'eventNodeLabel': 'encounter',
'eventFeatures': 'embedding',
'outputTimeProperty': 'output_time',
'timeNodeProperty': 'time',
'dimension': 32, -- in reality, a higher value is recommended
'numElapsedTimes': 30,
'maxElapsedTime': 3650,
'smoothingRate': 0.9,
'smoothingWindow': 2,
'decayFactor': 0.0
},
'write': [{
'nodeLabel': 'patient',
'outputTable': 'embeddings'
}]
});输出示例如下:
| JOB_ID | JOB_STATUS | JOB_START | JOB_END | JOB_RESULT |
|---|---|---|---|---|
job_91200aa45c0e4b81a14f68a70ecadeda |
SUCCESS |
2025-11-28T15:35:42.979010 |
2025-11-28T15:35:58.612925 |
{
"fastpath": {
"predictMillis": 5288
},
"project": {
"graphName": "snowgraph",
"nodeCount": 11,
"nodeLabels": {
"ENCOUNTER": {
"count": 3,
"nodeId": {
"dataType": "int8"
},
"properties": {
"embedding": {
"dataType": "ndarray[float32]",
"dimension": 2
},
"time": {
"dataType": "int8",
"dimension": 1
}
},
"table": "PATIENT_DB.GENERAL.ENCOUNTER"
},
"PATIENT": {
"count": 8,
"nodeId": {
"dataType": "int8"
},
"properties": {
"embedding": {
"dataType": "ndarray[float32]",
"dimension": 3
},
"has_diabetes": {
"dataType": "int8",
"dimension": 1
},
"output_time": {
"dataType": "int8",
"dimension": 1
}
},
"table": "PATIENT_DB.GENERAL.PATIENT"
}
},
"nodeMillis": 563,
"relationshipCount": 3,
"relationshipMillis": 211,
"relationshipTypes": {
"HAS_ENCOUNTER": {
"count": 3,
"direction": "NATURAL",
"sourceTable": "PATIENT_DB.GENERAL.PATIENT",
"table": "PATIENT_DB.GENERAL.HAS_ENCOUNTER",
"targetTable": "PATIENT_DB.GENERAL.ENCOUNTER"
}
},
"totalMillis": 774
},
"write_node_property_0": {
"nodeLabel": "PATIENT",
"outputTable": "PATIENT_DB.GENERAL.EMBEDDINGS",
"rowsWritten": 8,
"writeMillis": 2764
}
} |
产生的节点嵌入可以简单地进行探索,如下所示:
SELECT * FROM patient_db.general.embeddings LIMIT 10;它返回以下格式的数据:
NODEID EMBEDDING
0 [5.341047,3.848688,-5.973229,-6.814521,4.745209,9.643475,-0.045684,4.210951,-2.004807,4.428759,13.497086,-6.179376,-0.986118,-7.707472,-0.555529,-6.073474,4.083053,1.602635,1.958997,12.649292,-0.603967,10.158164,-0.338394,-0.608493,-4.837356,15.097547,-6.569559,-2.797304,0.338724,6.874722,9.505033,-8.754766]
1 [-6.724641,-11.390027,-4.453455,4.120544,-2.017518,-2.675358,2.027915,-7.672874,-2.879899,17.374033,11.240053,7.185143,10.593451,-0.032012,6.947659,-29.623604,0.166914,11.507900,-12.466205,-1.891875,-8.164936,7.390674,-10.806652,2.019349,-1.903723,29.574389,1.859032,3.853385,0.566263,-5.038345,4.792415,3.326340]
2 [-2.920011,-2.048257,-5.708614,-2.373963,-0.244315,2.887959,-23.091557,-0.587305,4.643905,-0.775859,7.227013,-1.861291,-4.952862,-7.039846,-11.932112,-8.986797,-1.304907,2.019032,3.064439,-4.360886,-2.295964,6.218091,0.975781,-3.919339,8.686658,17.961964,-7.780995,-1.146844,-6.269790,20.006420,-1.216949,-3.596368]
3 [-8.567083,-9.307947,-11.381653,-0.802077,-1.286643,-3.037168,5.494521,-1.814128,-1.623972,-0.085408,-8.678900,6.716533,-3.552778,10.777124,8.609731,2.346340,-6.656413,4.587024,-6.891663,0.081429,-3.976248,-3.998426,-0.445967,4.443917,-7.440049,15.908058,-6.126621,-9.205961,-3.693087,5.798036,-10.521414,25.272419]
4 [-3.993221,-15.716671,-7.102195,-22.005224,-0.855417,9.282584,-2.253866,-16.234423,24.112732,2.810601,-13.975744,-12.062764,-2.387400,20.061924,-1.067919,12.701017,-4.327281,-17.721920,23.729225,-9.824536,-8.265147,-2.768445,-25.310749,8.047261,13.448681,51.172272,-15.435410,14.756327,-4.342721,11.190716,28.090958,9.425692]
5 [-13.833055,-3.474358,-29.580704,15.354573,46.242706,13.694808,32.601025,26.757681,-7.090479,57.280357,-0.735581,38.106731,26.968494,3.217232,-23.623219,2.485056,-6.973878,0.877117,-15.995618,55.822735,18.801920,52.809269,-47.148773,39.193768,-4.173650,-12.601570,-14.213085,-21.923597,12.738949,-27.862555,-9.950893,-20.819094]
6 [13.704840,13.533702,-5.135115,-6.226133,-5.701371,-2.703825,5.956636,3.647114,2.735878,2.559484,-15.129639,9.952298,2.568221,1.664974,-0.048340,-10.921870,-17.725523,1.495797,-9.043520,25.950590,-0.110576,9.694299,-18.446062,-6.852248,6.842557,35.075626,8.634172,7.099162,-5.890983,9.706918,-8.494190,6.583567]
7 [-2.812654,2.941338,1.067755,-4.293394,-3.086962,-0.469450,3.613479,-2.819084,5.120227,7.050265,-2.466012,-2.169495,0.909174,2.145000,3.638202,-2.498263,-5.502569,-3.852499,5.146134,1.659534,-0.714558,-0.469029,2.176041,-1.869031,-4.940216,3.088835,3.752839,3.714232,-2.807177,-0.698254,-5.012471,2.528090]
8 [-7.303960,-7.729638,-4.773112,-9.641366,2.609788,-20.279972,6.826665,8.960463,19.718428,3.388449,7.409564,-17.707247,-0.936261,28.070925,-3.749211,-9.148918,16.058552,4.065396,10.297297,9.403608,-10.898782,-10.801480,-25.112486,3.316337,17.157797,12.428331,19.813198,10.889541,-1.723780,-1.651543,-0.261916,9.012156]
9 [-6.429783,-20.400585,16.191334,-16.042753,9.880158,-5.386495,-10.220762,15.675117,9.438731,-3.742106,10.518373,3.956760,6.789544,-0.625264,-8.893956,1.050145,-15.966327,-6.890019,-2.499497,8.597721,3.010286,3.782031,-10.274326,20.255251,1.046289,17.648533,-6.685064,13.613426,7.041289,13.350776,-3.143279,-5.788550]附录
以下部分为对算法内部工作原理感兴趣的读者提供了关于 FastPath 的更详细信息。
算法工作原理
下面将算法分解为各个步骤,这仅是概念上的。它不反映实际的实现细节,例如循环顺序、数据结构等。我们将描述如何为具有输出时间 to 的基础节点 b 计算 FastPATH 嵌入。输出时间根据所选参数 outputTime 或 outputTimeProperty 计算。属于 b 的任意事件将表示为 e,其时间戳假定为 te。在我们希望计算 b 嵌入的时刻 to,e 的经过时间为:
tel = to - te,即事件时间戳与对应基础节点输出时间之间的时间量。
请注意,事件可能属于具有不同输出时间的多个基础节点。这意味着涉及某个事件的一些计算必须为每个关联的基础节点重新计算,但幸运的是,这些计算彼此独立。
-
预处理
将输入预处理为包含基础节点、事件节点和(可选)上下文节点的图。基础节点和事件节点是连接的,事件和上下文节点也是连接的。如果事件没有给出时间戳,则通过遍历每个基础节点的事件链来生成时间戳。 -
过滤相关事件
在属于基础节点b的事件中,删除任何经过时间超过maxElapsedTime的事件,或任何在to或之后发生的事件。b的剩余相关事件将称为E(b)。 -
创建网格
在时间上创建一个网格,下文简称为网格。 -
生成随机向量
稀疏随机向量是针对下方每个输入源独立生成的(如果已选择)。
对于网格中的每个时间和每个输入源,生成向量如下:-
事件特征向量属性:为输入事件特征向量的每个维度
i生成一个向量ri,t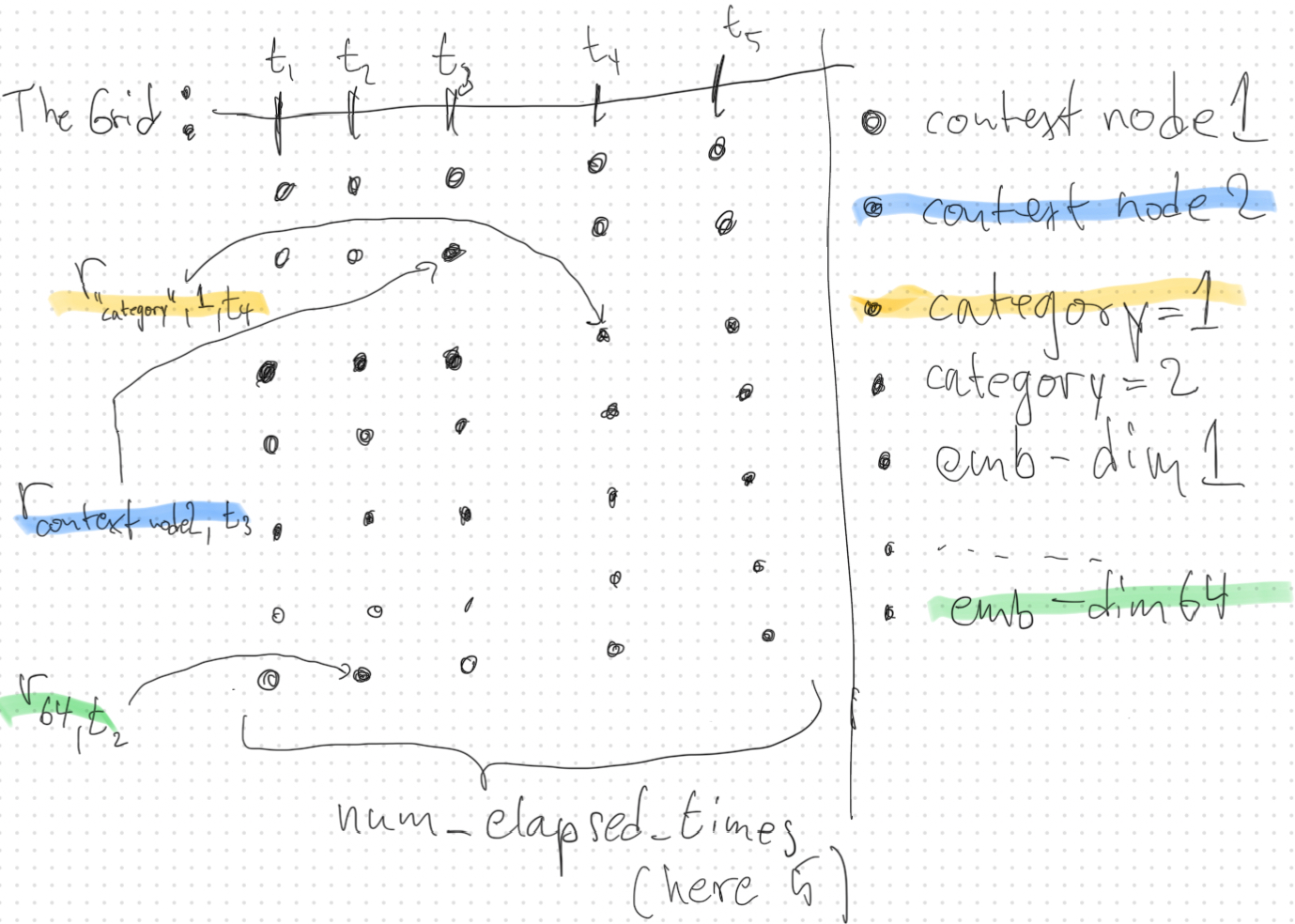
-
上下文节点:对于每个上下文节点
c,生成rc,t -
分类事件属性:对于每个分类节点属性
prop和该属性的每个值v,初始化一个随机向量rprop,v,t。
如果任何事件的属性值是一个类别列表[v1, v2, …],且v是这些值中的任何一个,我们初始化一个随机向量rprop,v,t。
-
-
计算事件节点预嵌入
事件e在时间t的预嵌入表示为xe,t,初始化为全零。对于下方适用的所有输入源,将步骤 3 中生成的随机向量的加权和添加到xe,t中:-
事件特征向量属性:
xe,t += ∑i ri,t * inpi
其中inp是e的输入向量,i遍历inp的维度。 -
上下文节点:
xe,t += ∑c rc,t
其中c遍历事件e的所有邻居。 -
分类事件属性:
xe,t += ∑prop rprop,e.prop,t
其中prop遍历所有选定的分类事件属性。
或者当e.prop是一个列表时:xe,t = ∑prop ∑v in e.prop rprop,v,t
-
-
计算事件嵌入
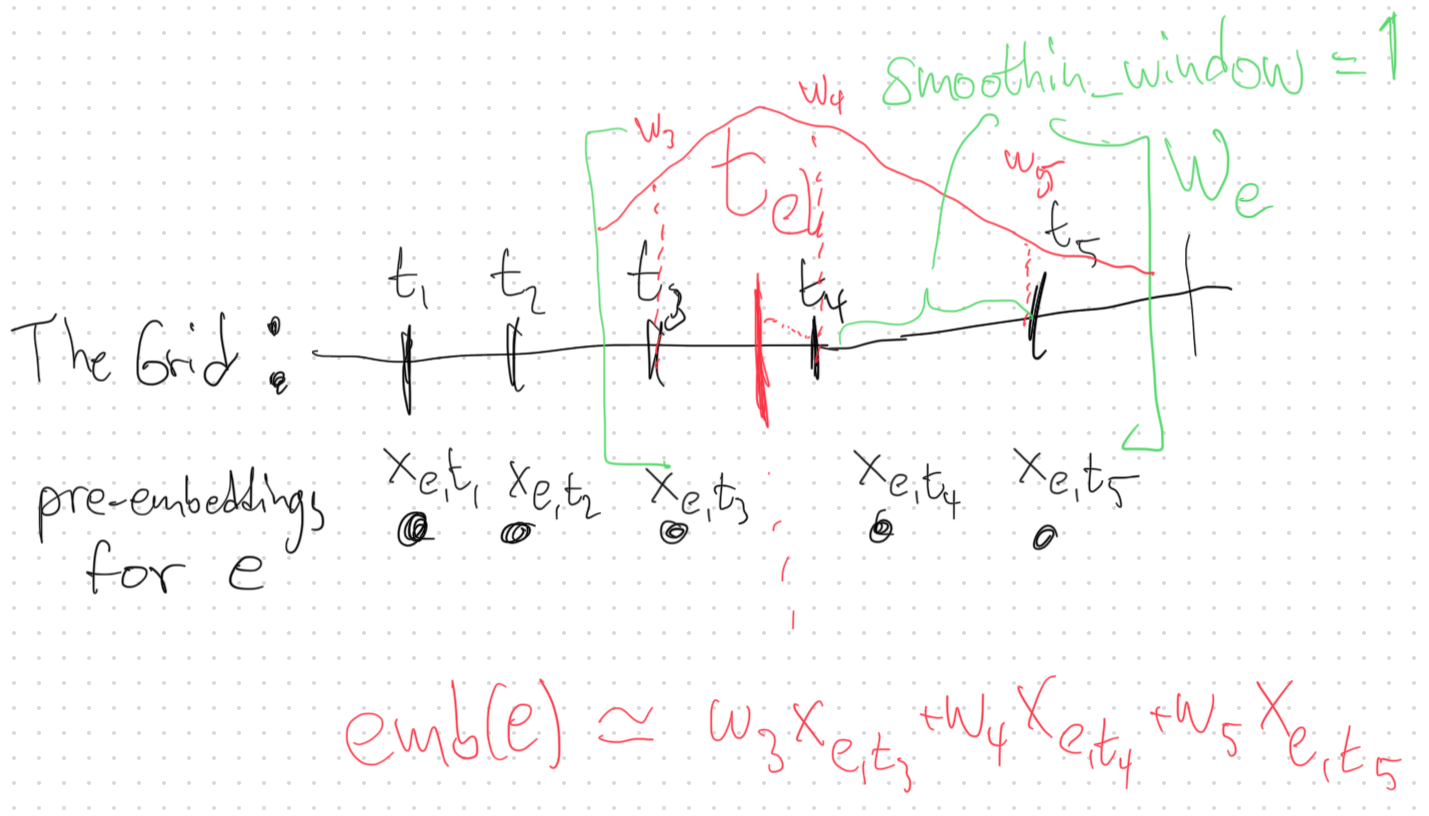
我们使用事件e在不同时间导出的预嵌入来计算其嵌入。我们找到网格中距离经过时间tel = to - te最近的时间tcl。然后,将tcl两侧最多smoothingWindow个点添加到网格中,从而获得事件的相关网格时间窗口We。在图中,smoothingWindow = 1且tcl=t4。因此We = {t3,t4,t5}。对于We中的每个t,我们将网格点t的权重设置为:
w(t) = exp(-|t - tel| * smoothingRate ) / Ze,
其中 Ze 是确保∑t in W_e w(t) = 1的常数。
现在我们可以最终将输出时间to的事件嵌入设置为:
emb(e|to) = ∑t in W_e w(t) * xe,t。因此,我们通过对预嵌入网格(或者如果您愿意,即基向量)取平均值,构建了时间平滑嵌入。时间平滑机制的目的是确保在所有其他因素相同的情况下,嵌入随经过时间的变化而连续变化。 -
计算基础节点嵌入
基础节点b的嵌入最终由下式给出:
emb(b) = ∑e in E(b) wb,e * emb(e)
其中
wb,e = exp(-decayFactor * (to - te)),且E(b)在步骤 2 中定义。
下图概述了哪些因素影响事件嵌入,以及它们如何根据输出时间和经过时间流向基础节点的嵌入。
