教程:使用 NLP 和本体构建知识图谱
简介
在本教程中,我们将构建一个软件知识图谱,其基础是:
-
来自开发者博客平台 dev.to 的文章,以及从这些文章中(使用 NLP 技术)提取出的实体。
-
从 Wikidata 中提取的软件本体,Wikidata 是一个免费开放的知识库,充当了维基百科结构化数据的中央存储库。
完成这些工作后,我们将学习如何查询该知识图谱,以发现通过结合 NLP 和本体论所带来的有趣洞察。
|
本指南中使用的查询和数据可以在 neo4j-examples/nlp-knowledge-graph GitHub 仓库中找到。 |
视频
Jesús Barrasa 和 Mark Needham 在 2020 年 8 月 25 日的 Neo4j Connections: Knowledge Graphs 活动上进行了基于本教程的演讲。演讲视频如下所示
工具
在本教程中,我们将使用几个插件库,因此如果您想跟随示例进行操作,则需要安装这些插件。
neosemantics (n10s)

neosemantics 是一个插件,它支持在 Neo4j 中使用 RDF 及其相关词汇表,如 OWL、RDFS、SKOS 等。我们将使用此工具将本体导入 Neo4j。
|
neosemantics 仅支持 Neo4j 4.0.x 和 3.5.x 系列。它目前还不支持 Neo4j 4.1.x 系列。 |
我们可以按照 项目安装指南 中的说明安装 neosemantics。
这两个工具都可以安装在 Docker 环境中,项目仓库中包含一个 docker-compose.yml 文件,展示了如何实现这一点。
什么是知识图谱?
知识图谱 有许多不同的定义。在本教程中,知识图谱定义为包含以下内容的图:
- 事实 (Facts)
-
实例数据。这包括从任何数据源导入的图数据,可以是结构化的(如 JSON/XML)或半结构化的(如 HTML)。
- 显式知识 (Explicit Knowledge)
-
关于实例数据如何关联的明确描述。这来自本体、分类法或任何形式的元数据定义。
导入 Wikidata 本体
![]()
Wikidata 是一个可供人类和机器读取及编辑的免费开放知识库。它充当其 Wikimedia 姊妹项目(包括维基百科、维基导游、维基词典、维基文库等)结构化数据的中央存储库。
Wikidata SPARQL API
Wikidata 提供了一个 SPARQL API,允许用户直接查询数据。下图显示了 SPARQL 查询的示例以及运行该查询后的结果。

此查询从实体 Q2429814 (软件系统) 开始,然后尽可能地传递性查找该实体的子项。如果我们运行该查询,我们将得到三元组(主语、谓语、宾语)流。
现在我们将学习如何使用 neosemantics 将 Wikidata 导入 Neo4j。
CREATE CONSTRAINT n10s_unique_uri ON (r:Resource) ASSERT r.uri IS UNIQUE;CALL n10s.graphconfig.init({handleVocabUris: "MAP"});call n10s.nsprefixes.add('neo','neo4j://voc#');
CALL n10s.mapping.add("neo4j://voc#subCatOf","SUB_CAT_OF");
CALL n10s.mapping.add("neo4j://voc#about","ABOUT");现在我们将导入 Wikidata 分类法。我们可以通过点击 Code 按钮直接从 Wikidata SPARQL API 获取可导入的 URL。
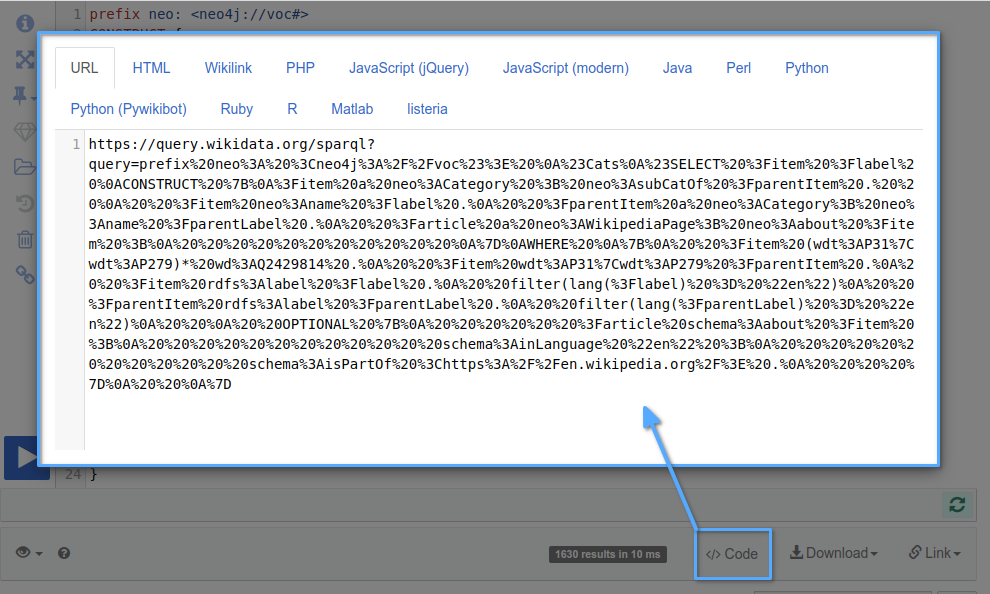
然后我们将该 URL 传递给 n10s.rdf.import.fetch 过程,它会将三元组流导入到 Neo4j 中。
以下示例包含从软件系统、编程语言和数据格式开始导入分类法的查询。
WITH "https://query.wikidata.org/sparql?query=prefix%20neo%3A%20%3Cneo4j%3A%2F%2Fvoc%23%3E%20%0A%23Cats%0A%23SELECT%20%3Fitem%20%3Flabel%20%0ACONSTRUCT%20%7B%0A%3Fitem%20a%20neo%3ACategory%20%3B%20neo%3AsubCatOf%20%3FparentItem%20.%20%20%0A%20%20%3Fitem%20neo%3Aname%20%3Flabel%20.%0A%20%20%3FparentItem%20a%20neo%3ACategory%3B%20neo%3Aname%20%3FparentLabel%20.%0A%20%20%3Farticle%20a%20neo%3AWikipediaPage%3B%20neo%3Aabout%20%3Fitem%20%3B%0A%20%20%20%20%20%20%20%20%20%20%20%0A%7D%0AWHERE%20%0A%7B%0A%20%20%3Fitem%20(wdt%3AP31%7Cwdt%3AP279)*%20wd%3AQ2429814%20.%0A%20%20%3Fitem%20wdt%3AP31%7Cwdt%3AP279%20%3FparentItem%20.%0A%20%20%3Fitem%20rdfs%3Alabel%20%3Flabel%20.%0A%20%20filter(lang(%3Flabel)%20%3D%20%22en%22)%0A%20%20%3FparentItem%20rdfs%3Alabel%20%3FparentLabel%20.%0A%20%20filter(lang(%3FparentLabel)%20%3D%20%22en%22)%0A%20%20%0A%20%20OPTIONAL%20%7B%0A%20%20%20%20%20%20%3Farticle%20schema%3Aabout%20%3Fitem%20%3B%0A%20%20%20%20%20%20%20%20%20%20%20%20schema%3AinLanguage%20%22en%22%20%3B%0A%20%20%20%20%20%20%20%20%20%20%20%20schema%3AisPartOf%20%3Chttps%3A%2F%2Fen.wikipedia.org%2F%3E%20.%0A%20%20%20%20%7D%0A%20%20%0A%7D" AS softwareSystemsUri
CALL n10s.rdf.import.fetch(softwareSystemsUri, 'Turtle' , { headerParams: { Accept: "application/x-turtle" } })
YIELD terminationStatus, triplesLoaded, triplesParsed, namespaces, callParams
RETURN terminationStatus, triplesLoaded, triplesParsed, namespaces, callParams;| 终止状态 | 三元组已加载 | 三元组已解析 | 命名空间 | 调用参数 |
|---|---|---|---|---|
"OK" |
1630 |
1630 |
NULL |
{headerParams: {Accept: "application/x-turtle"}} |
WITH "https://query.wikidata.org/sparql?query=prefix%20neo%3A%20%3Cneo4j%3A%2F%2Fvoc%23%3E%20%0A%23Cats%0A%23SELECT%20%3Fitem%20%3Flabel%20%0ACONSTRUCT%20%7B%0A%3Fitem%20a%20neo%3ACategory%20%3B%20neo%3AsubCatOf%20%3FparentItem%20.%20%20%0A%20%20%3Fitem%20neo%3Aname%20%3Flabel%20.%0A%20%20%3FparentItem%20a%20neo%3ACategory%3B%20neo%3Aname%20%3FparentLabel%20.%0A%20%20%3Farticle%20a%20neo%3AWikipediaPage%3B%20neo%3Aabout%20%3Fitem%20%3B%0A%20%20%20%20%20%20%20%20%20%20%20%0A%7D%0AWHERE%20%0A%7B%0A%20%20%3Fitem%20(wdt%3AP31%7Cwdt%3AP279)*%20wd%3AQ9143%20.%0A%20%20%3Fitem%20wdt%3AP31%7Cwdt%3AP279%20%3FparentItem%20.%0A%20%20%3Fitem%20rdfs%3Alabel%20%3Flabel%20.%0A%20%20filter(lang(%3Flabel)%20%3D%20%22en%22)%0A%20%20%3FparentItem%20rdfs%3Alabel%20%3FparentLabel%20.%0A%20%20filter(lang(%3FparentLabel)%20%3D%20%22en%22)%0A%20%20%0A%20%20OPTIONAL%20%7B%0A%20%20%20%20%20%20%3Farticle%20schema%3Aabout%20%3Fitem%20%3B%0A%20%20%20%20%20%20%20%20%20%20%20%20schema%3AinLanguage%20%22en%22%20%3B%0A%20%20%20%20%20%20%20%20%20%20%20%20schema%3AisPartOf%20%3Chttps%3A%2F%2Fen.wikipedia.org%2F%3E%20.%0A%20%20%20%20%7D%0A%20%20%0A%7D" AS programmingLanguagesUri
CALL n10s.rdf.import.fetch(programmingLanguagesUri, 'Turtle' , { headerParams: { Accept: "application/x-turtle" } })
YIELD terminationStatus, triplesLoaded, triplesParsed, namespaces, callParams
RETURN terminationStatus, triplesLoaded, triplesParsed, namespaces, callParams;| 终止状态 | 三元组已加载 | 三元组已解析 | 命名空间 | 调用参数 |
|---|---|---|---|---|
"OK" |
9376 |
9376 |
NULL |
{headerParams: {Accept: "application/x-turtle"}} |
WITH "https://query.wikidata.org/sparql?query=prefix%20neo%3A%20%3Cneo4j%3A%2F%2Fvoc%23%3E%20%0A%23Cats%0A%23SELECT%20%3Fitem%20%3Flabel%20%0ACONSTRUCT%20%7B%0A%3Fitem%20a%20neo%3ACategory%20%3B%20neo%3AsubCatOf%20%3FparentItem%20.%20%20%0A%20%20%3Fitem%20neo%3Aname%20%3Flabel%20.%0A%20%20%3FparentItem%20a%20neo%3ACategory%3B%20neo%3Aname%20%3FparentLabel%20.%0A%20%20%3Farticle%20a%20neo%3AWikipediaPage%3B%20neo%3Aabout%20%3Fitem%20%3B%0A%20%20%20%20%20%20%20%20%20%20%20%0A%7D%0AWHERE%20%0A%7B%0A%20%20%3Fitem%20(wdt%3AP31%7Cwdt%3AP279)*%20wd%3AQ24451526%20.%0A%20%20%3Fitem%20wdt%3AP31%7Cwdt%3AP279%20%3FparentItem%20.%0A%20%20%3Fitem%20rdfs%3Alabel%20%3Flabel%20.%0A%20%20filter(lang(%3Flabel)%20%3D%20%22en%22)%0A%20%20%3FparentItem%20rdfs%3Alabel%20%3FparentLabel%20.%0A%20%20filter(lang(%3FparentLabel)%20%3D%20%22en%22)%0A%20%20%0A%20%20OPTIONAL%20%7B%0A%20%20%20%20%20%20%3Farticle%20schema%3Aabout%20%3Fitem%20%3B%0A%20%20%20%20%20%20%20%20%20%20%20%20schema%3AinLanguage%20%22en%22%20%3B%0A%20%20%20%20%20%20%20%20%20%20%20%20schema%3AisPartOf%20%3Chttps%3A%2F%2Fen.wikipedia.org%2F%3E%20.%0A%20%20%20%20%7D%0A%20%20%0A%7D" AS dataFormatsUri
CALL n10s.rdf.import.fetch(dataFormatsUri, 'Turtle' , { headerParams: { Accept: "application/x-turtle" } })
YIELD terminationStatus, triplesLoaded, triplesParsed, namespaces, callParams
RETURN terminationStatus, triplesLoaded, triplesParsed, namespaces, callParams;| 终止状态 | 三元组已加载 | 三元组已解析 | 命名空间 | 调用参数 |
|---|---|---|---|---|
"OK" |
514 |
514 |
NULL |
{headerParams: {Accept: "application/x-turtle"}} |
查看分类法
让我们看看导入了什么。我们可以通过运行以下查询来概览数据库内容:
CALL apoc.meta.stats()
YIELD labels, relTypes, relTypesCount
RETURN labels, relTypes, relTypesCount;| 标签 | 关系类型 | 关系类型计数 |
|---|---|---|
{Category: 2308, _NsPrefDef: 1, _MapNs: 1, Resource: 3868, _MapDef: 2, WikipediaPage: 1560, _GraphConfig: 1} |
{ |
{SUB_CAT_OF: 7272, _IN: 2, ABOUT: 3120} |
任何带有 _prefix 的标签或关系类型都可以忽略,因为它们代表由 n10s 库创建的元数据。
我们可以看到,我们已经导入了超过 2,000 个 Category 节点和 1,700 个 WikipediaPage 节点。我们使用 n10s 创建的每个节点都将拥有 Resource 标签,这就是为什么我们有超过 4,000 个带有此标签的节点。
我们还有超过 7,000 个连接 Category 节点的 SUB_CAT_OF 关系类型,以及 3,000 个连接 WikipediaPage 节点到 Category 节点的 ABOUT 关系类型。
现在让我们看看我们导入的一些实际数据。我们可以通过运行以下查询来查看版本控制节点的子类别:
MATCH path = (c:Category {name: "version control system"})<-[:SUB_CAT_OF*]-(child)
RETURN path
LIMIT 25;
到目前为止,一切顺利!
导入 dev.to 文章
dev.to 是一个开发者博客平台,包含各种主题的文章,包括 NoSQL 数据库、JavaScript 框架、最新的 AWS API、聊天机器人等。首页截图如下所示。
我们将从 dev.to 导入一些文章到 Neo4j。articles.csv 包含 30 篇感兴趣的文章列表。我们可以使用 Cypher 的 LOAD CSV 子句查询此文件。
LOAD CSV WITH HEADERS FROM 'https://github.com/neo4j-examples/nlp-knowledge-graph/raw/master/import/articles.csv' AS row
RETURN row
LIMIT 10;| row |
|---|
{uri: "https://dev.to/lirantal/securing-a-nodejs—rethinkdb—tls-setup-on-docker-containers"} |
{uri: "https://dev.to/setevoy/neo4j-running-in-kubernetes-e4p"} |
{uri: "https://dev.to/divyanshutomar/introduction-to-redis-3m2a"} |
{uri: "https://dev.to/zaiste/15-git-commands-you-may-not-know-4a8j"} |
{uri: "https://dev.to/alexjitbit/removing-files-from-mercurial-history-1b15"} |
{uri: "https://dev.to/michelemauro/atlassian-sunsetting-mercurial-support-in-bitbucket-2ga9"} |
{uri: "https://dev.to/shirou/back-up-prometheus-records-to-s3-via-kinesis-firehose-54l4"} |
{uri: "https://dev.to/ionic/farewell-phonegap-reflections-on-my-hybrid-app-development-journey-10dh"} |
{uri: "https://dev.to/rootsami/rancher-kubernetes-on-openstack-using-terraform-1ild"} |
{uri: "https://dev.to/jignesh_simform/comparing-mongodb—mysql-bfa"} |
我们将使用 APOC 的 apoc.load.html 过程来抓取每个 URI 中的有趣信息。首先让我们看看如何在单篇文章上使用此过程,如下面的查询所示。
(1)
MERGE (a:Article {uri: "https://dev.to/lirantal/securing-a-nodejs--rethinkdb--tls-setup-on-docker-containers"})
WITH a
(2)
CALL apoc.load.html(a.uri, {
body: 'body div.spec__body p',
title: 'h1',
time: 'time'
})
YIELD value
UNWIND value.body AS item
(3)
WITH a,
apoc.text.join(collect(item.text), '') AS body,
value.title[0].text AS title,
value.time[0].attributes.datetime AS date
(4)
SET a.body = body , a.title = title, a.datetime = datetime(date)
RETURN a;| 1 | 如果没有,创建带有 Article 标签和 uri 属性的节点 |
| 2 | 使用提供的 CSS 选择器从 URI 抓取数据 |
| 3 | 对抓取 URI 返回的值进行后处理 |
| 4 | 更新带有 body, title, 和 datetime 属性的节点 |
| a |
|---|
(:Article {processed: TRUE, datetime: 2017-08-21T18:41:06Z, title: "在 Docker 容器上保护 Node.js + RethinkDB + TLS 设置", body: "我们在工作中跨不同项目使用 RethinkDB。它不用于任何类型的大数据应用程序,而是作为 NoSQL 数据库,它通过实时更新和关系表支持丰富了事物。RethinkDB 具有官方支持的 Node.js 驱动程序,以及名为 rethinkdbdash 的社区维护的驱动程序,它是基于 promises 的,并提供连接池。还有一个名为 rethinkdb-migrate 的数据库迁移工具,有助于管理数据库变更,例如模式变更、数据库播种、启动和拆卸功能。我们将使用 Docker Hub 中的官方 RethinkDB docker 镜像,并利用 docker-compose.yml 来启动它(稍后您可以向此设置添加其他服务)。docker-compose.yml 的一个公平示例:该 compose 文件将本地 tls 目录挂载为容器内的映射卷。tls/ 目录将包含我们的证书文件,compose 文件反映了这一点。要建立安全连接,我们需要使用证书来促进它,因此是一个初步的技术步骤:重要说明:更新 compose 文件以包含一个命令配置,该命令以所有必需的 SSL 配置启动 RethinkDB 进程重要说明:您会注意到没有任何与集群相关的配置,但如果您需要,也可以添加它们,以便它们可以加入 SSL 连接: — cluster-tls — cluster-tls-key /tls/key.pem — cluster-tls-cert /tls/cert.pem — cluster-tls-ca /tls/ca.pemRethinkDB 驱动程序支持一个 ssl 可选对象,它要么使用 ca 属性设置证书,要么设置 rejectUnauthorized 属性以在连接时接受或拒绝自签名证书。传递给驱动程序的 ssl 配置片段:现在连接已安全,仅使用非默认的用户/密码连接才有意义。要进行设置,请更新 compose 文件以还包含 — initial-password 参数,以便您可以设置默认管理员用户的密码。例如:当然,您需要将此参数附加到上述 compose 文件中的其余命令行选项。现在,更新 Node.js 驱动程序设置以使用用户和密码进行连接:恭喜!您现在有资格获得“Ready for Production”贴纸。别担心,我已经邮寄到您的地址了。", uri: "https://dev.to/lirantal/securing-a-nodejs—rethinkdb—tls-setup-on-docker-containers"}) |
现在我们将导入其他文章。
我们将使用 apoc.periodic.iterate 过程,以便我们可以并行化此过程。此过程接收一个数据驱动语句和一个操作语句。
-
数据驱动语句包含一个要处理的项目流,即 URI 流。
-
操作语句定义了对每个项目做什么,即调用
apoc.load.html并创建带有Article标签的节点。
最后一个参数用于提供配置。我们将告诉该过程以 5 个为一批处理这些项目,可以并发运行。
我们可以在以下示例中看到对该过程的调用。
CALL apoc.periodic.iterate(
"LOAD CSV WITH HEADERS FROM 'https://github.com/neo4j-examples/nlp-knowledge-graph/raw/master/import/articles.csv' AS row
RETURN row",
"MERGE (a:Article {uri: row.uri})
WITH a
CALL apoc.load.html(a.uri, {
body: 'body div.spec__body p',
title: 'h1',
time: 'time'
})
YIELD value
UNWIND value.body AS item
WITH a,
apoc.text.join(collect(item.text), '') AS body,
value.title[0].text AS title,
value.time[0].attributes.datetime AS date
SET a.body = body , a.title = title, a.datetime = datetime(date)",
{batchSize: 5, parallel: true}
)
YIELD batches, total, timeTaken, committedOperations
RETURN batches, total, timeTaken, committedOperations;| batches | 总计 | 耗时 | 已提交的操作 |
|---|---|---|---|
7 |
32 |
15 |
32 |
现在我们有两个断开连接的子图,如下面的图所示。
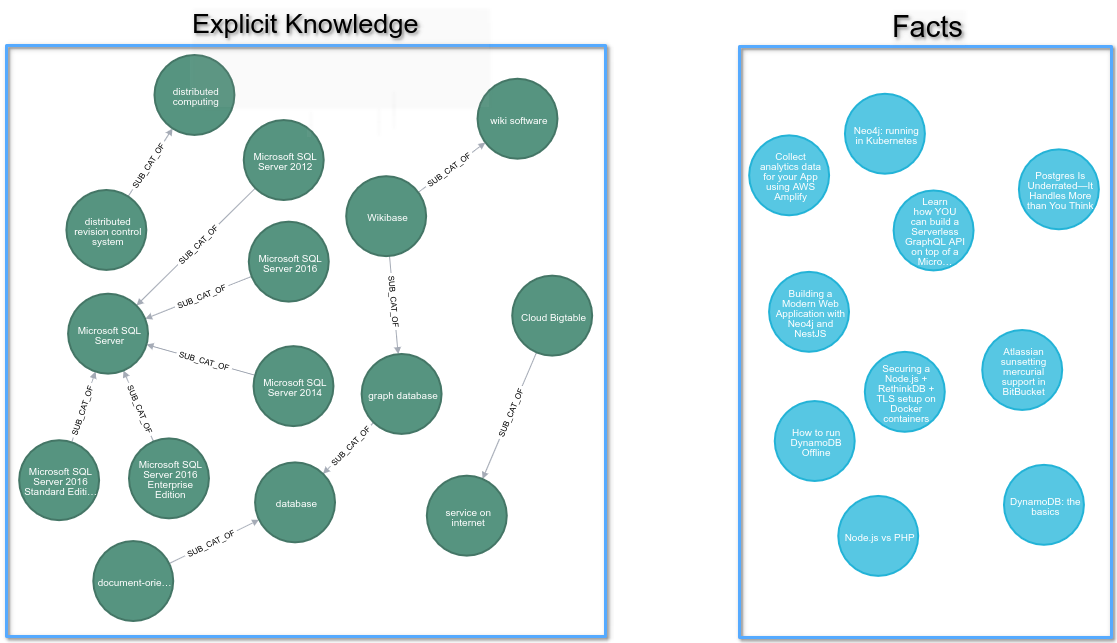
左侧是 Wikidata 分类法图,它代表了我们知识图谱中的显式知识。右侧是文章图,它代表了我们知识图谱中的事实。我们想要将这两个图连接在一起,我们将使用 NLP 技术来实现这一点。
文章实体提取

2020 年 4 月,APOC 标准库添加了 封装了 NLP API 的过程,涵盖了每个大型云提供商(AWS、GCP 和 Azure)。这些过程从节点属性中提取文本,然后将该文本发送到提取实体、关键短语、类别或情绪的 API。
我们将在我们的文章上使用 GCP 实体提取 过程。GCP NLP API 为存在页面的实体返回维基百科页面。
在此之前,我们需要创建一个有权访问自然语言 API 的 API 密钥。假设我们已经创建了一个 GCP 帐户,我们可以按照 console.cloud.google.com/apis/credentials 上的说明生成密钥。创建密钥后,我们将创建一个包含它的参数。
:params key => ("<insert-key-here>")我们将使用 apoc.nlp.gcp.entities.stream 过程,它将返回在节点属性中包含的文本内容所找到的实体流。在对所有文章运行此过程之前,让我们先对其中一篇运行它,看看返回了什么数据。
MATCH (a:Article {uri: "https://dev.to/lirantal/securing-a-nodejs--rethinkdb--tls-setup-on-docker-containers"})
CALL apoc.nlp.gcp.entities.stream(a, {
nodeProperty: 'body',
key: $key
})
YIELD node, value
SET node.processed = true
WITH node, value
UNWIND value.entities AS entity
RETURN entity
LIMIT 5;| 实体 (entity) |
|---|
{name: "RethinkDB", salience: 0.47283632, metadata: {mid: "/m/0134hdhv", wikipedia_url: "https://en.wikipedia.org/wiki/RethinkDB"}, type: "ORGANIZATION", mentions: [{type: "PROPER", text: {content: "RethinkDB", beginOffset: -1}}, {type: "PROPER", text: {content: "RethinkDB", beginOffset: -1}}, {type: "PROPER", text: {content: "RethinkDB", beginOffset: -1}}, {type: "PROPER", text: {content: "RethinkDB", beginOffset: -1}}, {type: "PROPER", text: {content: "pemThe RethinkDB", beginOffset: -1}}]} |
{name: "connection", salience: 0.04166339, metadata: {}, type: "OTHER", mentions: [{type: "COMMON", text: {content: "connection", beginOffset: -1}}, {type: "COMMON", text: {content: "connection", beginOffset: -1}}]} |
{name: "work", salience: 0.028608896, metadata: {}, type: "OTHER", mentions: [{type: "COMMON", text: {content: "work", beginOffset: -1}}]} |
{name: "projects", salience: 0.028608896, metadata: {}, type: "OTHER", mentions: [{type: "COMMON", text: {content: "projects", beginOffset: -1}}]} |
{name: "database", salience: 0.01957906, metadata: {}, type: "OTHER", mentions: [{type: "COMMON", text: {content: "database", beginOffset: -1}}]} |
每一行都包含一个描述实体的 name 属性。salience 是该实体对整个文档文本的重要性或中心性的指标。
一些实体还包含维基百科 URL,通过 metadata.wikipedia_url 键找到。第一个实体 RethinkDB 是此列表中唯一具有此类 URL 的实体。我们将过滤返回的行,仅包括具有维基百科 URL 的行,然后我们将 Article 节点连接到具有该 URL 的 WikipediaPage 节点。
让我们看看我们将如何为一篇文章完成此操作:
MATCH (a:Article {uri: "https://dev.to/lirantal/securing-a-nodejs--rethinkdb--tls-setup-on-docker-containers"})
CALL apoc.nlp.gcp.entities.stream(a, {
nodeProperty: 'body',
key: $key
})
(1)
YIELD node, value
SET node.processed = true
WITH node, value
UNWIND value.entities AS entity
(2)
WITH entity, node
WHERE not(entity.metadata.wikipedia_url is null)
(3)
MERGE (page:Resource {uri: entity.metadata.wikipedia_url})
SET page:WikipediaPage
(4)
MERGE (node)-[:HAS_ENTITY]->(page)| 1 | node 是文章,value 包含提取的实体 |
| 2 | 仅包括具有维基百科 URL 的实体 |
| 3 | 查找匹配维基百科 URL 的节点。如果不存在,则创建一个。 |
| 4 | 在 Article 节点和 WikipediaPage 之间创建 HAS_ENTITY 关系 |
我们可以通过查看以下 Neo4j 浏览器可视化,了解运行此查询如何连接文章和分类法子图。

现在我们可以再次借助 apoc.periodic.iterate 过程对其余文章运行实体提取技术。
CALL apoc.periodic.iterate(
"MATCH (a:Article)
WHERE not(exists(a.processed))
RETURN a",
"CALL apoc.nlp.gcp.entities.stream([item in $_batch | item.a], {
nodeProperty: 'body',
key: $key
})
YIELD node, value
SET node.processed = true
WITH node, value
UNWIND value.entities AS entity
WITH entity, node
WHERE not(entity.metadata.wikipedia_url is null)
MERGE (page:Resource {uri: entity.metadata.wikipedia_url})
SET page:WikipediaPage
MERGE (node)-[:HAS_ENTITY]->(page)",
{batchMode: "BATCH_SINGLE", batchSize: 10, params: {key: $key}})
YIELD batches, total, timeTaken, committedOperations
RETURN batches, total, timeTaken, committedOperations;| batches | 总计 | 耗时 | 已提交的操作 |
|---|---|---|---|
4 |
31 |
29 |
31 |
查询知识图谱
现在是查询知识图谱的时候了。
语义搜索
我们要做的第一个查询是语义搜索。n10s.inference.nodesInCategory 过程允许我们从顶级类别进行搜索,找到其所有传递性子类别,然后返回连接到任何这些类别的节点。
在我们的图中,连接到类别节点的节点是 WikipediaPage 节点。因此,我们需要向查询中添加一个额外的 MATCH 子句,通过 HAS_ENTITY 关系类型找到连接的文章。我们可以在以下查询中看到如何实现这一点。
MATCH (c:Category {name: "NoSQL database management system"})
CALL n10s.inference.nodesInCategory(c, {
inCatRel: "ABOUT",
subCatRel: "SUB_CAT_OF"
})
YIELD node
MATCH (node)<-[:HAS_ENTITY]-(article)
RETURN article.uri AS uri, article.title AS title, article.datetime AS date,
collect(n10s.rdf.getIRILocalName(node.uri)) as explicitTopics
ORDER BY date DESC
LIMIT 5;| uri | 标题 | date | 显式主题 |
|---|---|---|---|
"https://dev.to/arthurolga/newsql-an-implementation-with-google-spanner-2a86" |
"NewSQL:使用 Google Spanner 的实现" |
2020-08-10T16:01:25Z |
["NoSQL"] |
"https://dev.to/goaty92/designing-tinyurl-it-s-more-complicated-than-you-think-2a48" |
"设计 TinyURL:它比你想象的更复杂" |
2020-08-10T10:21:05Z |
["Apache_ZooKeeper"] |
"https://dev.to/nipeshkc7/dynamodb-the-basics-360g" |
"DynamoDB:基础" |
2020-06-02T04:09:36Z |
["NoSQL", "Amazon_DynamoDB"] |
"https://dev.to/subhransu/realtime-chat-app-using-kafka-springboot-reactjs-and-websockets-lc" |
"使用 Kafka, SpringBoot, ReactJS 和 WebSockets 的实时聊天应用" |
2020-04-25T23:17:22Z |
["Apache_ZooKeeper"] |
"https://dev.to/codaelux/running-dynamodb-offline-4k1b" |
"如何离线运行 DynamoDB" |
2020-03-23T21:48:31Z |
["NoSQL", "Amazon_DynamoDB"] |
尽管我们搜索了 NoSQL,但从结果中可以看到,有几篇文章并未直接链接到该类别。例如,我们有几篇关于 Apache Zookeeper 的文章。我们可以通过编写以下查询来查看该类别是如何连接到 NoSQL 的。
match path = (c:WikipediaPage)-[:ABOUT]->(category)-[:SUB_CAT_OF*]->(:Category {name: "NoSQL database management system"})
where c.uri contains "Apache_ZooKeeper"
RETURN path;
因此,Apache Zookeeper 实际上距离 NoSQL 类别有几个级别之遥。
相似文章
我们可以使用知识图谱做的另一件事是根据文章共有的实体查找相似文章。此查询的最简单版本是查找共享共有实体的其他文章,如下面的查询所示。
MATCH (a:Article {uri: "https://dev.to/qainsights/performance-testing-neo4j-database-using-bolt-protocol-in-apache-jmeter-1oa9"}),
path = (a)-[:HAS_ENTITY]->(wiki)-[:ABOUT]->(cat),
otherPath = (wiki)<-[:HAS_ENTITY]-(other)
return path, otherPath;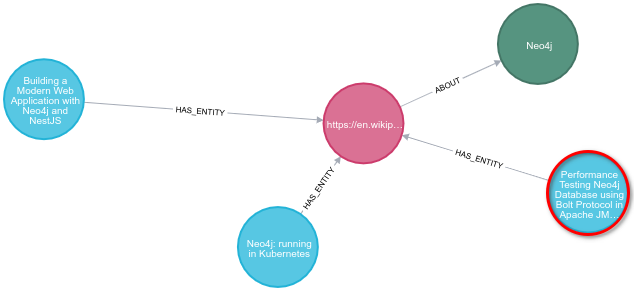
这篇 Neo4j 性能测试文章是关于 Neo4j 的,还有另外两篇 Neo4j 文章,我们可以推荐给喜欢这篇文章的读者。
我们还可以在查询中使用类别分类法。我们可以通过编写以下查询来查找共享共同父类别的文章。
MATCH (a:Article {uri: "https://dev.to/qainsights/performance-testing-neo4j-database-using-bolt-protocol-in-apache-jmeter-1oa9"}),
entityPath = (a)-[:HAS_ENTITY]->(wiki)-[:ABOUT]->(cat),
path = (cat)-[:SUB_CAT_OF]->(parent)<-[:SUB_CAT_OF]-(otherCat),
otherEntityPath = (otherCat)<-[:ABOUT]-(otherWiki)<-[:HAS_ENTITY]-(other)
RETURN other.title, other.uri,
[(other)-[:HAS_ENTITY]->()-[:ABOUT]->(entity) | entity.name] AS otherCategories,
collect([node in nodes(path) | node.name]) AS pathToOther;| other.title | other.uri | otherCategories | pathToOther |
|---|---|---|---|
"带有 ASP.NET Core 的 Couchbase GeoSearch" |
"https://dev.to/ahmetkucukoglu/couchbase-geosearch-with-asp-net-core-i04" |
["ASP.NET", "Couchbase Server"] |
[["Neo4j", "专有软件", "Couchbase Server"], ["Neo4j", "自由软件", "ASP.NET"], ["Neo4j", "自由软件", "Couchbase Server"]] |
"终极 Postgres vs MySQL 博客文章" |
"https://dev.to/dmfay/the-ultimate-postgres-vs-mysql-blog-post-1l5f" |
["YAML", "Python", "JavaScript", "NoSQL 数据库管理系统", "结构化查询语言", "JSON", "可扩展标记语言", "逗号分隔值", "PostgreSQL", "MySQL", "Microsoft SQL Server", "MongoDB", "MariaDB"] |
[["Neo4j", "专有软件", "Microsoft SQL Server"], ["Neo4j", "自由软件", "PostgreSQL"]] |
"2020 年学习 Apache Kafka 的 5 门最佳课程" |
"https://dev.to/javinpaul/5-best-courses-to-learn-apache-kafka-in-2020-584h" |
["Java", "Scratch", "Scala", "Apache ZooKeeper"] |
[["Neo4j", "自由软件", "Scratch"], ["Neo4j", "自由软件", "Apache ZooKeeper"]] |
"使用 Neo4j 和 NestJS 构建现代 Web 应用程序" |
"https://dev.to/adamcowley/building-a-modern-web-application-with-neo4j-and-nestjs-38ih" |
["TypeScript", "JavaScript", "Neo4j"] |
[["Neo4j", "自由软件", "TypeScript"]] |
"在 Docker 容器上保护 Node.js + RethinkDB + TLS 设置" |
"https://dev.to/lirantal/securing-a-nodejs—rethinkdb—tls-setup-on-docker-containers" |
["NoSQL 数据库管理系统", "RethinkDB"] |
[["Neo4j", "自由软件", "RethinkDB"]] |
请注意,在此查询中,我们还返回了从初始文章到其他文章的路径。因此,对于“带有 ASP.NET Core 的 Couchbase GeoSearch”,存在一条从初始文章到 Neo4j 类别,从那里到专有软件类别,该类别也是 Couchbase Server 类别的父级,该文章连接到该类别的路径,“带有 ASP.NET Core 的 Couchbase GeoSearch”文章连接到该类别。
这展示了知识图谱的另一个好功能 - 除了做出推荐外,解释为什么做出推荐也同样容易。
添加自定义本体
我们可能不认为专有软件是衡量两个技术产品相似性的一个很好的标准。我们不太可能根据这种相似性来寻找相似的文章。
但软件产品连接的一种常见方式是通过 技术栈。因此,我们可以创建自己的包含其中一些栈的本体。
nsmntx.org/2020/08/swStacks 包含一个用于 GRANDstack, MEAN Stack 和 LAMP Stack 的本体。在我们导入此本体之前,让我们在 n10s 中设置一些映射。
CALL n10s.nsprefixes.add('owl','http://www.w3.org/2002/07/owl#');
CALL n10s.nsprefixes.add('rdfs','http://www.w3.org/2000/01/rdf-schema#');
CALL n10s.mapping.add("http://www.w3.org/2000/01/rdf-schema#subClassOf","SUB_CAT_OF");
CALL n10s.mapping.add("http://www.w3.org/2000/01/rdf-schema#label","name");
CALL n10s.mapping.add("http://www.w3.org/2002/07/owl#Class","Category");现在我们可以通过运行以下查询来预览本体的导入。
CALL n10s.rdf.preview.fetch("http://www.nsmntx.org/2020/08/swStacks","Turtle");
看起来不错,所以让我们通过运行以下查询来导入它。
CALL n10s.rdf.import.fetch("http://www.nsmntx.org/2020/08/swStacks","Turtle")
YIELD terminationStatus, triplesLoaded, triplesParsed, namespaces, callParams
RETURN terminationStatus, triplesLoaded, triplesParsed, namespaces, callParams;| 终止状态 | 三元组已加载 | 三元组已解析 | 命名空间 | 调用参数 |
|---|---|---|---|---|
"OK" |
58 |
58 |
NULL |
{} |
我们现在可以重新运行相似性查询,现在它将返回以下结果。
| other.title | other.uri | otherCategories | pathToOther |
|---|---|---|---|
"GraphQL 初学者指南" |
"https://dev.to/leonardomso/a-beginners-guide-to-graphql-3kjj" |
["GraphQL", "JavaScript"] |
[["Neo4j", "GRAND Stack", "GraphQL"]] |
"了解您如何构建基于微服务架构的无服务器 GraphQL API,第一部分" |
"https://dev.to/azure/learn-how-you-can-build-a-serverless-graphql-api-on-top-of-a-microservice-architecture-233g" |
["Node.js", "GraphQL"] |
[["Neo4j", "GRAND Stack", "GraphQL"]] |
"终极 Postgres vs MySQL 博客文章" |
"https://dev.to/dmfay/the-ultimate-postgres-vs-mysql-blog-post-1l5f" |
["结构化查询语言", "可扩展标记语言", "PostgreSQL", "MariaDB", "JSON", "MySQL", "Microsoft SQL Server", "MongoDB", "逗号分隔值", "JavaScript", "YAML", "Python", "NoSQL 数据库管理系统"] |
[["Neo4j", "专有软件", "Microsoft SQL Server"], ["Neo4j", "自由软件", "PostgreSQL"]] |
"带有 ASP.NET Core 的 Couchbase GeoSearch" |
"https://dev.to/ahmetkucukoglu/couchbase-geosearch-with-asp-net-core-i04" |
["ASP.NET", "Couchbase Server"] |
[["Neo4j", "专有软件", "Couchbase Server"], ["Neo4j", "自由软件", "ASP.NET"], ["Neo4j", "自由软件", "Couchbase Server"]] |
"使用 Neo4j 和 NestJS 构建现代 Web 应用程序" |
"https://dev.to/adamcowley/building-a-modern-web-application-with-neo4j-and-nestjs-38ih" |
["JavaScript", "TypeScript", "Neo4j"] |
[["Neo4j", "自由软件", "TypeScript"]] |
这次我们在顶部增加了几篇关于 GraphQL 的文章,它是 GRANDstack 中的工具之一,Neo4j 也是其一部分。