从非结构化数据创建知识图谱
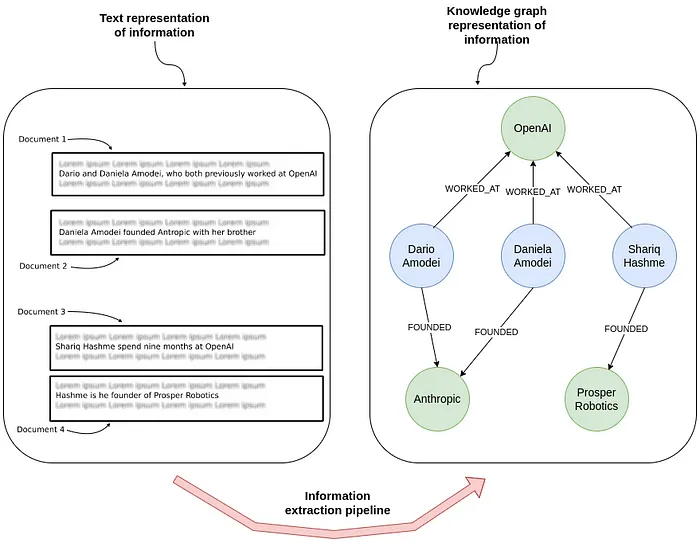
使用 Spacy、Stanford NLP、OpenNLTK 等 NLP 技术 从非结构化文本中构建图结构早已成为可能。这些方法通常要求针对待处理文本的特定领域和语言对 NLP 模型进行微调,并需要扎实的 NLP 技能才能获得最佳效果。
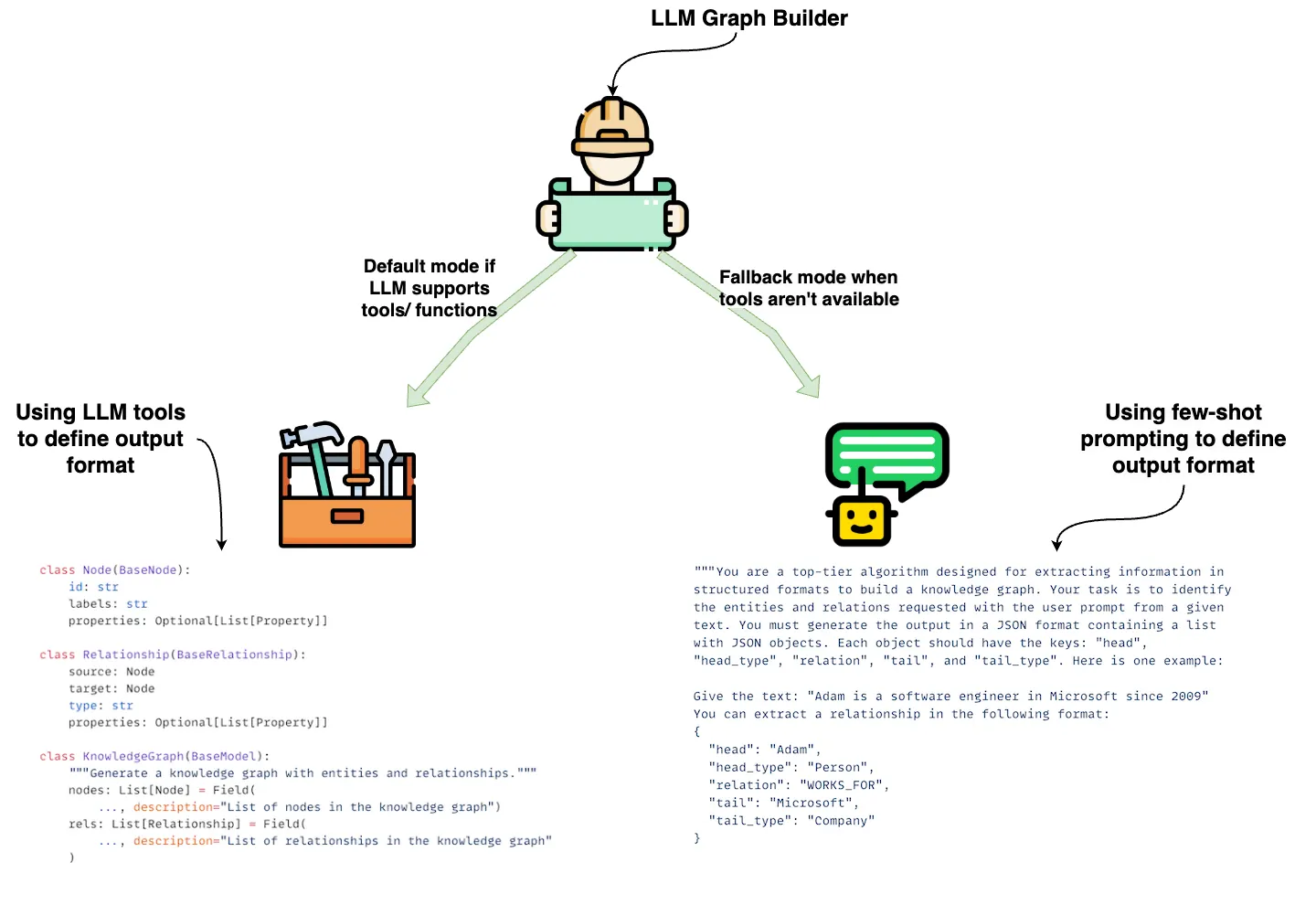
随着具备强大跨语言、跨领域语言能力的现代化大语言模型(LLM)的兴起,其能力得到了极大的扩展。通过详细的提示词(指令、示例、模式、现有实体、输出格式),可以指导 LLM 从非结构化文本、图像和音频片段中提取并去重实体和关系。提取的信息以结构化的 JSON 格式返回,可以存储在 Neo4j 等图数据库中,并关联回源文档及其他元数据。
这使得从非结构化数据构建知识图谱(KG)并将其与 Neo4j 中现有的结构化数据集成成为可能。这些知识图谱可用于多种应用,包括 GraphRAG(检索增强生成)应用,其中知识图谱用于检索相关的上下文信息,以增强 LLM 的回答。

Neo4j 产品功能
GraphRAG Python 软件包
Neo4j Python GraphRAG 软件包提供了一套完整的流水线,用于非结构化文档处理、基于图模式的实体提取、解析和存储。
SimpleKGBuilder 提供了一种简单的入门方式,若需全面配置,请使用
from neo4j_graphrag.experimental.pipeline.kg_builder import SimpleKGPipeline
ENTITIES = [
"Person",
{"label": "Company", "description": "Company or organization"},
{"label": "Location", "properties": [{"name": "city", "type": "STRING"}]},
]
RELATIONS = [
"LOCATED_AT",
{
"label": "COMPETES_WITH",
"description": "Used for competitor relationships between companies",
},
{"label": "WORKS_AT", "properties": [{"name": "fromYear", "type": "INTEGER"}]},
]
kg_builder = SimpleKGPipeline(
llm=llm, # an LLMInterface for Entity and Relation extraction
driver=neo4j_driver, # a neo4j driver to write results to graph
embedder=embedder, # an Embedder for chunks
from_pdf=True, # set to False if parsing an already extracted text
entities=ENTITIES,
relations=RELATIONS,
potential_schema=POTENTIAL_SCHEMA, # a optional list of node-relationship-node schema entries
)
await kg_builder.run_async(file_path=str(file_path))
完整的知识图谱(KG)构建流水线需要更多组件:
-
数据加载器 (Data loader):从文件(PDF 等)中提取文本。
-
文本分割器 (Text splitter):将文本拆分为较小的块,以便 LLM 处理(受上下文窗口/Token 限制)。
-
块嵌入器 (Chunk embedder, 可选):计算文本块的向量嵌入。
-
模式构建器 (Schema builder):提供模式以定义 LLM 提取的实体和关系的基础,从而获得易于导航的知识图谱。
-
词法图构建器 (Lexical graph builder):构建词法图(文档、块及其关系,可选)。
-
实体和关系提取器 (Entity and relation extractor):从文本中提取相关实体和关系。
-
知识图谱写入器 (Knowledge Graph writer):保存识别出的实体和关系。
-
实体解析器 (Entity resolver):将相似实体合并为单个节点。
在文档中了解更多信息
这些生成的知识图谱随后可以与相同的 Python 软件包一起使用,用于构建基于 GraphRAG 的生成式 AI 应用。
原型设计与演示
LLM 知识图谱构建器
LLM 知识图谱构建器 是一款易于使用的工具,用于从非结构化文本中构建知识图谱。
它在后台使用 LangChain 的 LLMGraphTransformer,但提供了一个简单的 UI,用于从上传的 PDF、Office 文档、网页或 YouTube 视频字幕中提取实体和关系。它首先提取词法图(文档、块及其关系),然后使用选择的 LLM 提取实体和关系。它还可以选择对图社区摘要和嵌入进行丰富。你可以指定一个图模式来指导提取过程并可视化提取出的图。
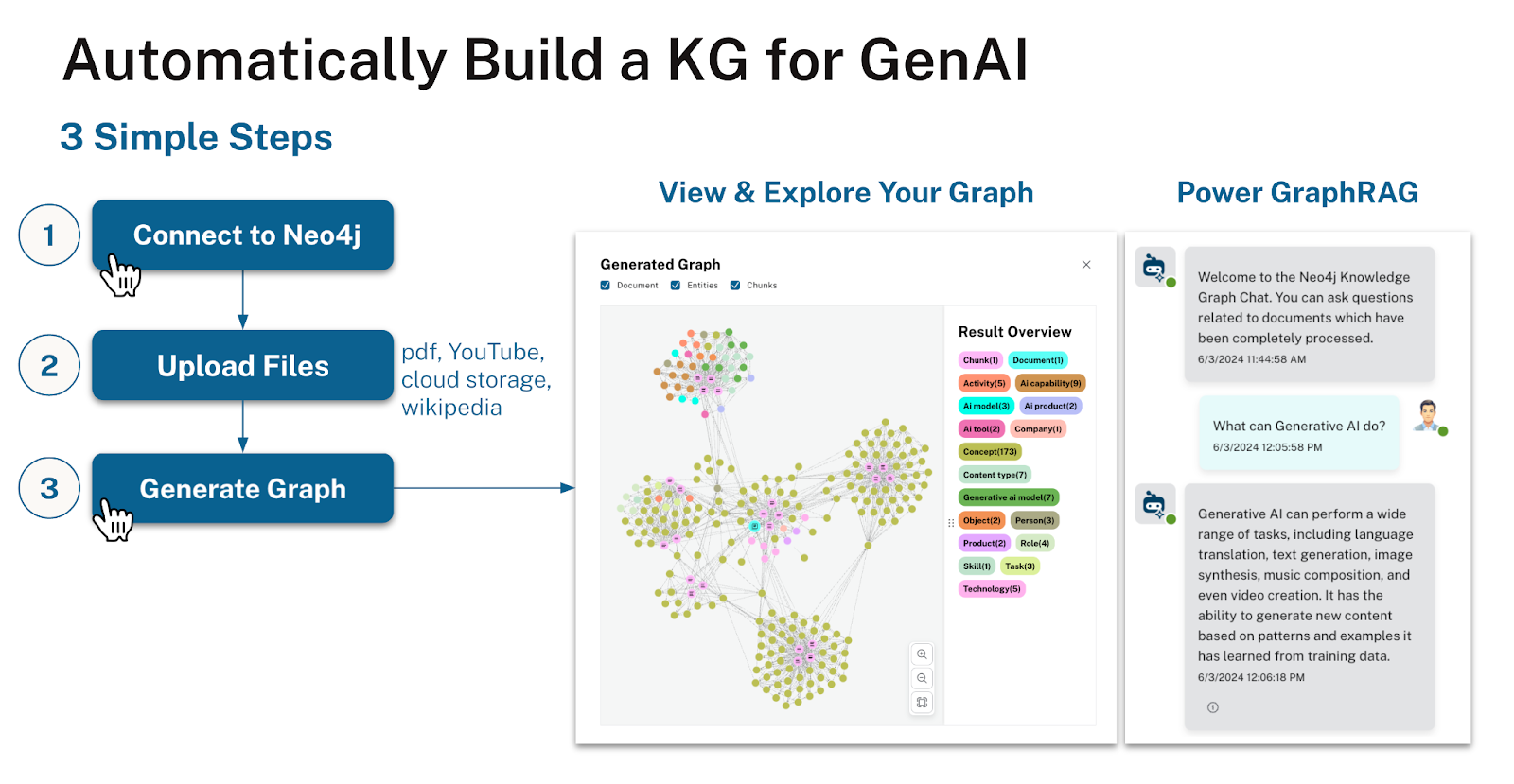
为了与提取的信息进行交互,你可以比较多种不同的检索器,包括 GraphRAG、向量检索、混合检索和 Text2Cypher。对于每个回答,你可以检查信息的来源以及用于生成该回答的检索上下文。它还允许在检索结果上运行 RAGAs 评估。
一些内部细节记录在 LLM 图构建器 - 知识图谱提取挑战 中。
使用 Neo4j MCP 服务器的 AI 助手
交互式试验知识图谱提取的快速方法是使用 AI 助手(如 Claude、ChatGPT)或支持 MCP 的 IDE(如 VS Code、Cursor、Windsurf),以交互方式处理文本或讨论,并提示 LLM 提取实体和关系。
以前,这些提取的图实体必须通过中间格式(如 JSON 或 CSV,例如通过数据导入器)或 Cypher 导入。
现在,它们可以使用 mcp-neo4j-cypher 或 mcp-neo4j-memory MCP 服务器自动保存到已连接的图中。

生态系统集成
Neo4j 与其他多种工具和框架集成,为知识图谱的提取和使用提供解决方案。
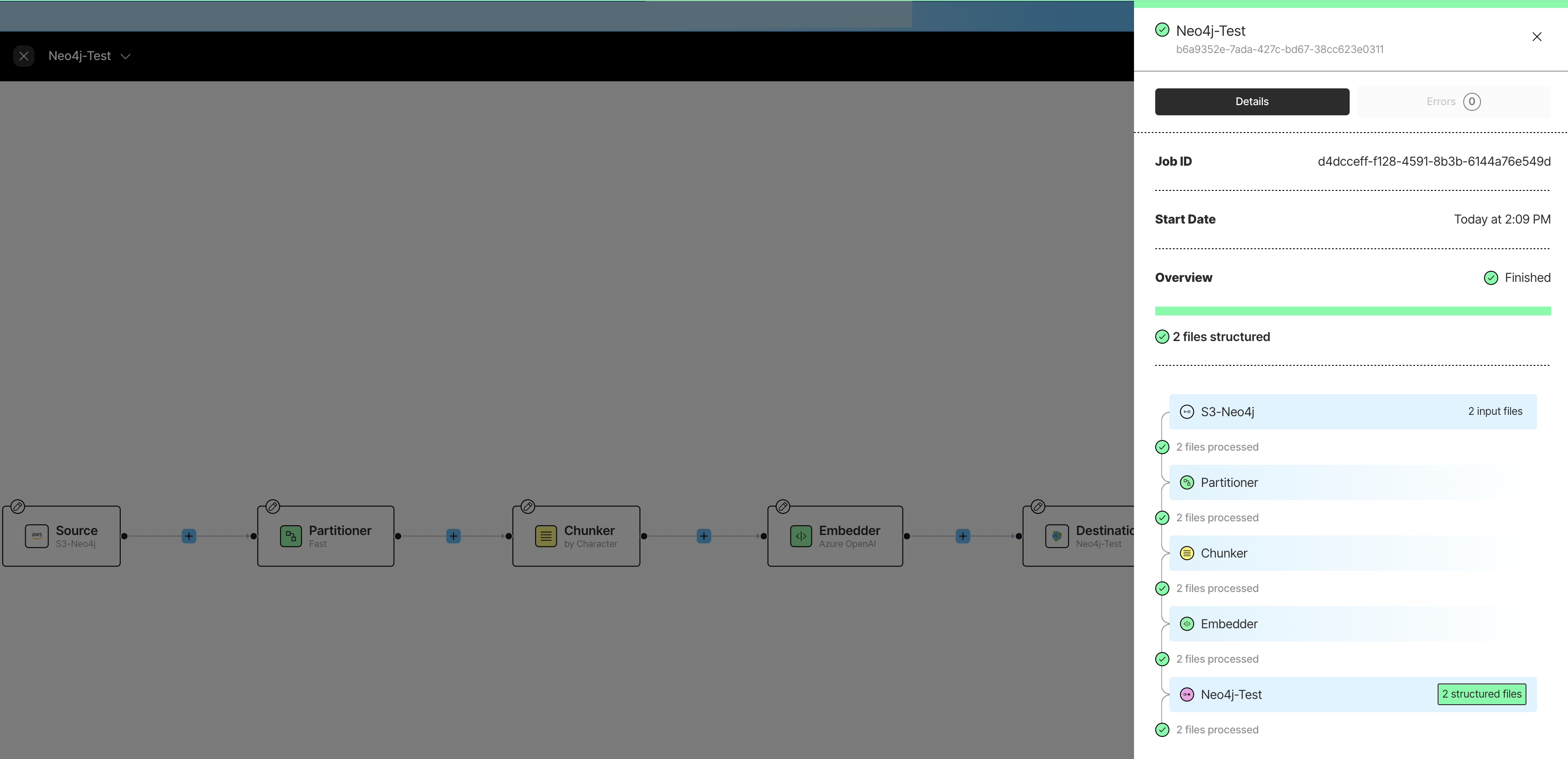
Unstructured.io
Unstructured.io 是一个用于从非结构化文档中提取结构化数据的平台和 Python 软件包。它提供了一套工具,用于解析、清理和将非结构化数据转换为结构化格式。
Neo4j 集成功能允许你从任何受支持的来源提取词法图。
Pipeline.from_configs(
context=ProcessorConfig(),
indexer_config=LocalIndexerConfig(input_path=os.getenv("LOCAL_FILE_INPUT_DIR")),
downloader_config=LocalDownloaderConfig(),
source_connection_config=LocalConnectionConfig(),
...
chunker_config=ChunkerConfig(chunking_strategy="by_title"),
embedder_config=EmbedderConfig(embedding_provider="huggingface"),
destination_connection_config=Neo4jConnectionConfig(
access_config=Neo4jAccessConfig(password=os.getenv("NEO4J_PASSWORD")),
username=os.getenv("NEO4J_USERNAME"),
uri=os.getenv("NEO4J_URI"),
database=os.getenv("NEO4J_DATABASE"),
),
stager_config=Neo4jUploadStagerConfig(),
uploader_config=Neo4jUploaderConfig(batch_size=100)
).run()LangChain
其用法非常简单,如 构建知识图谱 中所述。你可以使用 convert_to_graph_documents 方法将 LangChain 文档列表转换为图文档(节点和关系)。为了指导提取过程,你可以指定包含允许的节点和关系的模式,以及属性和其他提取说明。
from langchain_experimental.graph_transformers import LLMGraphTransformer
llm_transformer = LLMGraphTransformer(
llm=llm,
allowed_nodes=["Person", "Country", "Organization"],
allowed_relationships=["NATIONALITY", "LOCATED_IN", "WORKED_AT", "SPOUSE"],
node_properties=["born_year"],
)
graph_documents = llm_transformer.convert_to_graph_documents(documents)[0]
print(f"Nodes: {graph_documents.nodes} Rels: {graph_documents.relationships}")
graph.add_graph_documents(graph_documents, include_source=True)
LlamaIndex
在 LlamaIndex 中,PropertyGraphIndex 是管理知识图谱的主要组件,包括从非结构化数据中构建知识图谱。对于提取实体和关系,可以使用不同的提取器,例如 SchemaLLMPathExtractor。
from typing import Literal
from llama_index.core.indices.property_graph import SchemaLLMPathExtractor
entities = Literal["Person", "Place", "Thing"]
relations = Literal["PART_OF", "HAS", "IS_A"]
schema = {
"Person": ["PART_OF", "HAS", "IS_A"],
"Place": ["PART_OF", "HAS"],
"Thing": ["IS_A"],
}
kg_extractor = SchemaLLMPathExtractor(
llm=llm,
possible_entities=entities,
possible_relations=relations,
kg_validation_schema=schema,
strict=True, # if false, will allow triplets outside of the schema
num_workers=4,
max_triplets_per_chunk=10,
)
graph_store = Neo4jPropertyGraphStore(
username="neo4j",
password="<password>",
url="neo4j+s://xxx.databases.neo4j.io",
)
# creates an index
index = PropertyGraphIndex.from_documents(
documents,
property_graph_store=graph_store,
# optional, neo4j also supports vectors directly
vector_store=vector_store,
embed_kg_nodes=True,
)Neo4j-PropertyGraphIndex 可用于 GraphRAG 作为检索器,例如通过 VectorContextRetriever、LLMSynonymRetriever、TextToCypherRetriever 或 CypherTemplateRetriever。