
对图算法有兴趣的朋友可以关注微信公众号 :《 Medical与AI的故事》
我们已经陆续介绍了几种算法,例如LPA;但是,直到现在,我们还是强调图算法用于一般性图分析。由于图在机器学习(ML)中的应用越来越多,我们现在将研究如何使用图算法来增强ML的工作流程。
在本章中,我们重点介绍用图算法改进机器学习的最实用办法:提取连接相关的特征,并用于在关系预测。首先,我们将介绍一些基本的ML概念,并了解对提升预测的上下文数据的重要性。然后,我们将快速了解图功能的应用方式,包括用于垃圾邮件发送者欺诈、检测和链接预测。
我们将演示如何创建机器学习管道,并训练和评估连接预测的模型,并将Neo4j和Spark集成到我们的工作流程中。我们的示例将基于Citation Network Dataset,它包含作者、论文、作者关系和引用关系。我们将使用几个模型来预测研究作者将来是否有可能合作,并展示图形算法如何改进结果。
机器学习与上下文的重要性
机器学习不是人工智能,而是实现人工智能的一种方法。ML使用算法通过特定的示例和基于预期结果的渐进式改进来训练软件,而无需为如何实现这些更好的结果进行显式编程。训练包括向模型提供大量数据,并使其能够学习如何处理和合并这些信息。
从这个意义上讲,学习意味着算法迭代,不断地进行更改以接近目标,例如与训练数据相比减少分类错误。ML也是动态的,当有更多的数据时,它能够自我修改和优化。这可以发生在许多批次的使用前训练中,也可以作为使用过程中的在线学习。
最近在ML预测、大数据集的可访问性和并行计算能力方面取得的成功使ML更适合开发用于人工智能应用的概率模型。随着机器学习越来越广泛,记住它的基本目标很重要:做出与人类相似的选择。如果我们忘记了这一目标,我们最终可能只会得到另一个高目标、基于规则的软件版本。
为了提高机器学习的准确性,同时使解决方案更广泛地适用,我们需要整合大量的上下文信息,就像人们应该使用上下文来做出更好的决策一样。人类使用他们周围的环境,而不仅仅是直接的数据点,来找出在一种情况下什么是必要的,估计缺失的信息,并决定如何将经验教训应用到新的情况。上下文帮助我们改进预测。
图、上下文和准确性
如果没有周边和相关信息,试图预测行为或针对不同情况提出建议的解决方案需要更大量的训练和规定性规则。这就是为什么人工智能擅长于特定的、定义明确的任务,但却难以处理模糊性的部分原因。图增强的ML可以帮助填充丢失的上下文信息,这些信息对于更好的决策非常重要。
从图论和现实生活中我们都知道,关系往往是行为的最强预测因子。例如,如果一个人投票,他们的朋友、家人甚至同事投票的可能性就会增加。图8-1说明了R. Bond等人在2012年的论文“A 61-Million-Person Experiment in Social Influence and Political Mobilization”中研究的被报道的投票(reported voting)和Facebook朋友所产生的连锁反应。
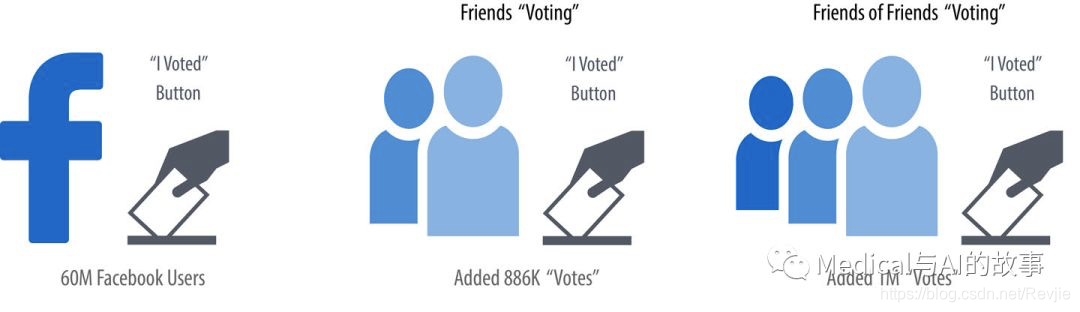 图8-1.人们受其社交网络的影响而投票。在这个例子中,两个跳点距离处的朋友就总体而言比直接的关系影响更大。
图8-1.人们受其社交网络的影响而投票。在这个例子中,两个跳点距离处的朋友就总体而言比直接的关系影响更大。
作者发现,报告投票的朋友影响了另外1.4%的用户声称他们投票了,有趣的是,朋友的朋友又增加了1.7%。小的百分比可能会产生显著的影响,我们可以在图8-1中看到,两个跳点处的人总比直接的朋友有更多的影响。Nicholas Christakis和James Fowler在《Connected》(Little、Brown和Company)一书中介绍了投票和其他社会网络如何影响我们的例子。
添加图特征和上下文可以改进预测,特别是在连接很重要的情况下。例如,零售公司不仅使用历史数据,还使用有关客户相似性和在线行为的上下文数据来使产品建议更加个性化。Amazon的Alexa使用了多层上下文模型(several layers of contextual models),以提高准确性。2018年,亚马逊在回答新问题时,还引入了“上下文转移(context carryover)”,将以前的参考资料纳入对话中。
不幸的是,今天许多机器学习方法都缺少大量丰富的上下文信息。这是由于ML依赖于从元组构建的输入数据,而忽略了许多预测关系和网络数据。此外,上下文信息并不总是容易获得,或者太难访问和处理。对于传统的方法来说,即使找到四个或更多个跃点以外的连接也是一个规模上的挑战。使用图,我们可以更容易地访问和合并连接的数据。
连接特征(Connected feature)提取与选择
特征提取和选择有助于我们通过获取原始数据,创建一个合适的子集和格式来训练我们的机器学习模型。这是一个基本的步骤,当执行良好时,会使得ML产生更一致的准确预测。
特征提取与选择
特征提取是将大量数据和属性提取为一组具有代表性的描述性属性的方法。该过程为输入数据中的独特特征或模式导出数值(特征),以便我们可以在其他数据中区分类别。特征提取,在数据难以被模型直接使用时会用到,难以使用的原因可能是数据量、格式或者需要偶然比较(incidental comparison)。
特征选择是确定对目标最重要或影响最大的提取特征子集的过程。它被用来表明预测的重要性以及效率。例如,如果我们有20个特征,其中13个共同解释了我们需要预测的92%,那么我们可以在模型中消除7个特征。
将正确的特征组合在一起可以提高准确性,因为它从根本上影响我们的模型的学习方式。因为即使是适度的改进也会产生显著的差异,所以我们在本章中的重点是关联特征。连接特征(connected feature)是从图数据结构中提取的特征。这些特征可以从基于节点周围图形部分的图局部查询,用于连接特征提取的图全局查询。这些图全局查询用图算法在关系数据中识别可预测元素。
不仅要获得正确的功能组合,而且要消除不必要的功能,以降低我们的模型被错误计算(hypertargeted)。这使我们创建避免只在训练数据(称为过度拟合)上工作良好的模型,并大大扩展了适用性。我们还可以使用图算法来评估这些特征,并确定哪些特征对我们的关联特征选择模型最有影响。例如,我们可以将特征映射到图中的节点,根据相似的特征创建关系,然后计算特征的中心性。特征关系可以通过保存数据点的聚类密度来定义。该方法是由K.Henniab、N.Mezghani和C.Gouin Vallerand在“Unsupervised Graph-Based Feature Selection Via Subspace and PageRank Centrality”中使用高维和低样本量的数据集来描述的。
图嵌入(Graph Embedding)
图嵌入是将图中的节点和关系表示为特征向量。这些仅仅是具有维度映射的特征的集合,如图8-2所示的(x,y,z)坐标。
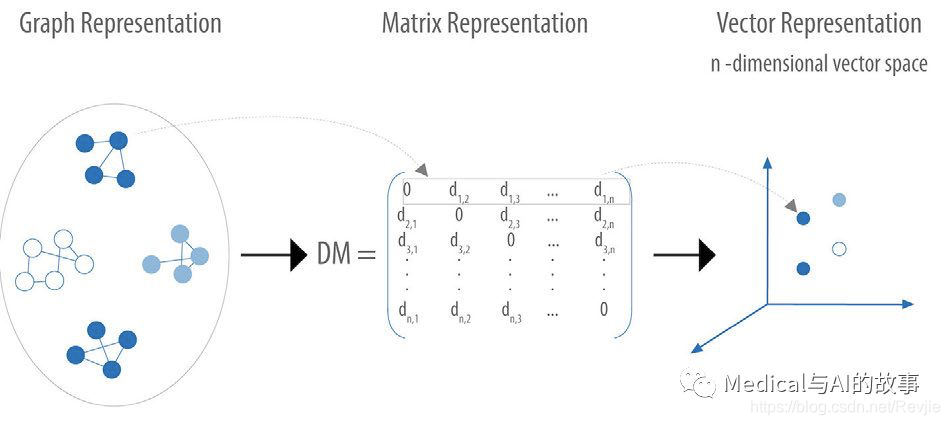 图8-2.图嵌入将图数据映射到可以可视化为多维坐标的特征向量中。
图形嵌入使用的图数据与连接特征提取略有不同。它使我们能够以数字格式表示整个图形或图形数据的子集,为机器学习任务做好准备。这对于无监督的学习尤其有用,因为数据通过关系获取更多的上下文信息,因此数据不进行分类。图嵌入还可用于数据挖掘、计算实体之间的相似性以及减少维数以辅助统计分析。(区分图嵌入和图特征提取,前者主要为无监督学习服务,后者主要为监督学习服务。本章主要致力于后者。)
图8-2.图嵌入将图数据映射到可以可视化为多维坐标的特征向量中。
图形嵌入使用的图数据与连接特征提取略有不同。它使我们能够以数字格式表示整个图形或图形数据的子集,为机器学习任务做好准备。这对于无监督的学习尤其有用,因为数据通过关系获取更多的上下文信息,因此数据不进行分类。图嵌入还可用于数据挖掘、计算实体之间的相似性以及减少维数以辅助统计分析。(区分图嵌入和图特征提取,前者主要为无监督学习服务,后者主要为监督学习服务。本章主要致力于后者。)
这是一个快速发展的空间,有多种选择,包括node2vec, struc2vec, GraphSAGE, DeepWalk, 和 DeepGL。
现在,让我们看看一些连接特征的类型以及它们是如何使用的。
图特征(graphy features)
图形特征包括关于我们的图形的任何数量的连接相关度量,例如进入或退出节点的关系数、潜在三角形数和共同的邻居。在我们的示例中,我们将从这些度量开始,因为它们很容易收集,并且是对早期假设的良好测试。此外,当我们精确地知道我们在寻找什么时,我们可以使用特征工程。
例如,如果我们想知道有多少人拥有一个最多四个跳点处的欺诈账户。这种方法使用图遍历来非常有效地查找关系的深层路径,查看诸如标签、属性、计数和推断关系等内容。
我们还可以轻松地自动化这些流程,并将这些预测性图形功能交付到我们现有的管道中。例如,我们可以提取欺诈者关系的计数,并将该数字作为节点属性添加,以用于其他机器学习任务。
图算法特征(graph algorithm features)
我们也可以使用图算法来寻找我们所寻找的一般结构的特征,而不是精确的模式。举例来说,让我们假设我们知道某些类型的社区群表示欺诈;也许有一个典型的密度或层次关系。在这种情况下,我们不需要一个固定的组织特征,而需要一个灵活的全局相关结构。在我们的示例中,我们将使用社区检测算法来提取连接的特征,但是中心性算法(如PageRank)也经常被应用。 此外,结合多种连接特征的方法似乎比坚持使用一种方法要好。例如,我们可以将连接特征与基于Louvain算法发现的社区、使用PageRank的影响节点以及三个跃点处已知欺诈者的度量指标相结合来预测欺诈。
图8-3展示了一种组合方法,作者将Pagerank和Coloring等图形算法与入链和出链等图度量相结合。此图摘自S.Fakhraei等人的论文“Collective Spammer Detection in Evolving Multi-Relational Social Networks”。
在该论文中,图结构(Graph Structure )章节说明了使用几种图算法进行的连接特征提取。有趣的是,作者发现从多种关系类型中提取关联特征比简单地添加更多特征更具预测性。报告子图部分(Report Subgraph)显示了如何将图形功能转换为ML模型可以使用的功能。通过在一个图增强的ML工作流程中结合多种方法,作者能够改进先前的检测方法,并分类70%以前需要手动标记的垃圾邮件发送者,准确率为90%。
即使我们提取了连接特征,我们也可以通过使用像PageRank这样的图算法来优化影响最大的特征。这使我们能够充分地表示数据,同时消除可能降低结果或处理速度的噪声变量。利用这类信息,我们还可以识别出高共现性的特征,通过特征约简进一步调整模型。这一方法在D. IENCO、R. MEO和M. Botta的研究论文“Using PageRank in Feature Selection”中进行了概述。
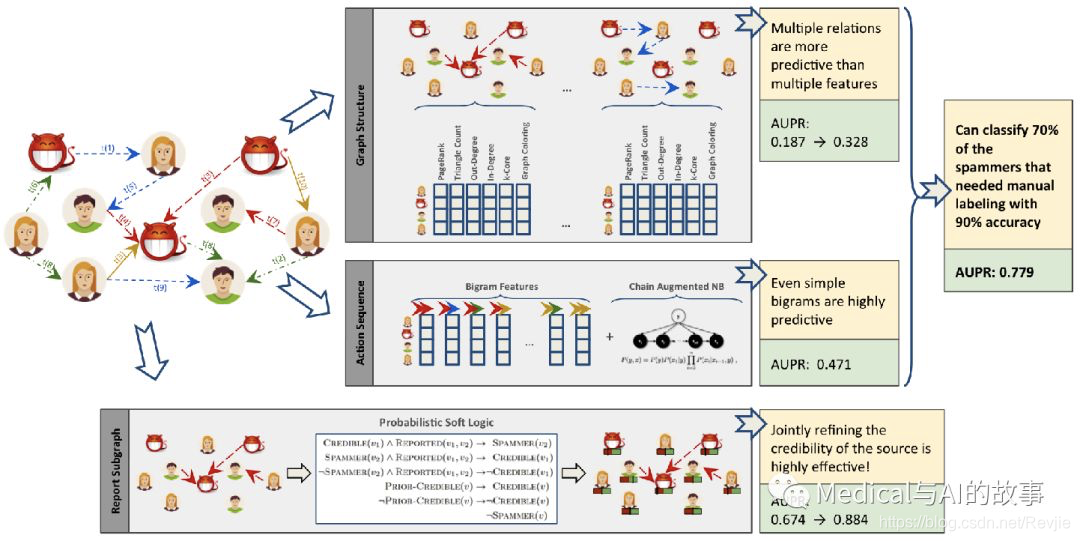 图8-3.关联特征提取可以与其他预测方法相结合,以提高结果。AUPR是指精确召回曲线下的区域,数值越大越好。
图8-3.关联特征提取可以与其他预测方法相结合,以提高结果。AUPR是指精确召回曲线下的区域,数值越大越好。
我们已经讨论了连接特征如何应用于涉及欺诈和垃圾邮件发送者检测的场景。在这些情况下,活动通常隐藏在多个模糊层和网络关系中。传统的特征提取和选择方法在没有图形所带来的上下文信息的情况下可能无法检测到这种行为。
连接特征能够增强机器学习的另一个领域(以及本章其余部分的重点)是链接预测。链接预测是一种估计关系未来形成的可能性的方法,或者该关系可能已经出现在我们的图中,但由于数据不完整而丢失。由于网络是动态的,可以快速增长,因此能够预测即将生成的链接具有广泛的适用性,从产品建议到药物重定目标,甚至推断犯罪关系。
图中的连接特征通常用来改进链接预测,在此过程中使用到了基本的图特征,以及从中心性和社区等算法中提取的特征。
基于节点邻近性或相似性的链接预测也是标准的,在论文“The Link Prediction Problem for Social Networks”中D. Liben Nowell和J. Kleinberg认为,仅网络结构就可能包含足够的潜在信息,用来检测节点邻近性,并优于直接的测量。
既然我们已经研究了连接特征如何增强机器学习,那么让我们深入到我们的链接预测示例中,看看如何应用图算法来改进预测。
实用图和机器学习:链接预测
本章的其余部分将演示一个基于引文网络数据集(Citation Network Dataset)的实践示例,该数据集是从DBLP、ACM和MAG中提取的一个研究数据集。该数据集在J. Tang等人的论文“ArnetMiner : Extraction and Mining of Academic Social Networks”中进行了描述。最新版本包含3,079,007篇论文、1,766,547位作者、9,437,718位作者关系和25,166,994位引文关系。 我们将在一个子集上工作,重点关注以下出版物中出现的文章:
- Lecture Notes in Computer Science
- Communications of the ACM
- International Conference on Software Engineering
- Advances in Computing and Communications
我们生成的数据集包含51,956篇论文、80,299位作者、140,575位作者关系和28,706个引文关系。我们将根据合作论文的作者创建一个合作者图,然后预测未来两个作者之间的合作。我们只对没有合作过的作者之间的合作感兴趣,在合作者之间有多个合作的,不是我们的关注重点。
在本章的其余部分,我们将建立所需的工具,并将数据导入Neo4j。然后我们将介绍如何正确平衡数据(均匀化),并将样本拆分为Spark DataFrame,以便进行训练和测试。在此之后,我们会在Spark中创建机器学习管道之前,解释链路预测假设和方法。
最后,我们将通过训练和评估各种预测模型,从基本的图特征开始,添加更多使用Neo4j提取的图算法特征。
工具和数据
让我们从设置工具和数据开始。然后我们将探索我们的数据集并创建一个机器学习管道。
在我们做其他事情之前,让我们先设置本章中使用的库:

 我们使用MLlib作为机器学习库的一个示范。本章所示的方法可以与其他ML库,如Scikit learn等等,结合使用。
所有显示的代码都将在PySpark REPL中运行。我们可以通过运行以下命令来启动REPL:
我们使用MLlib作为机器学习库的一个示范。本章所示的方法可以与其他ML库,如Scikit learn等等,结合使用。
所有显示的代码都将在PySpark REPL中运行。我们可以通过运行以下命令来启动REPL:
export SPARK_VERSION="spark-2.4.0-bin-hadoop2.7"
./${SPARK_VERSION}/bin/pyspark \
--driver-memory 2g \
--executor-memory 6g \
--packages julioasotodv:spark-tree-plotting:0.2
这类似于我们在第3章中启动REPL时使用的命令,但是我们加载的不是GraphFrames,而是spark-tree-plotting这个包。在编写时,Spark的最新发布版本是spark-2.4.0-bin-hadoop2.7,但由于这一版本可能在你阅读本文时有所更改,请确保适当更改Spark版本环境变量。 启动后,我们将导入以下要使用的库:
from py2neo import Graph
import pandas as pd
from numpy.random import randint
from pyspark.ml import Pipeline
from pyspark.ml.classification import RandomForestClassifier
from pyspark.ml.feature import StringIndexer, VectorAssembler
from pyspark.ml.evaluation import BinaryClassificationEvaluator
from pyspark.sql.types import *
from pyspark.sql import functions as F
from sklearn.metrics import roc_curve, auc
from collections import Counter
from cycler import cycler
import matplotlib
matplotlib.use('TkAgg')
import matplotlib.pyplot as plt
现在让我们创建一个到Neo4j数据库的连接:
graph = Graph("bolt://localhost:7687", auth=("neo4j", "neo"))
将数据导入Neo4j 现在我们准备将数据加载到Neo4j中,并为我们的训练和测试创建一个平衡的分割。我们需要下载数据集版本10的zip文件,解压它,并将内容放在导入文件夹中。我们应该有以下文件:
- dblp-ref-0.json
- dblp-ref-1.json
- dblp-ref-2.json
- dblp-ref-3.json 在导入文件夹中包含这些文件后,需要将以下属性添加到Neo4j设置文件中,以便使用APOC库处理这些文件:
apoc.import.file.enabled=true
apoc.import.file.use_neo4j_config=true
首先,我们将创建约束以确保不创建重复的文章或作者:
CREATE CONSTRAINT ON (article:Article)
ASSERT article.index IS UNIQUE;
CREATE CONSTRAINT ON (author:Author)
ASSERT author.name IS UNIQUE;
现在,我们可以运行以下查询从JSON文件导入数据:
CALL apoc.periodic.iterate(
'UNWIND ["dblp-ref-0.json","dblp-ref-1.json",
"dblp-ref-2.json","dblp-ref-3.json"] AS file
CALL apoc.load.json("file:///" + file)
YIELD value
WHERE value.venue IN ["Lecture Notes in Computer Science",
"Communications of The ACM",
"international conference on software engineering",
"advances in computing and communications"]
return value',
'MERGE (a:Article {index:value.id})
ON CREATE SET a += apoc.map.clean(value,["id","authors","references"],[0])
WITH a,value.authors as authors
UNWIND authors as author
MERGE (b:Author{name:author})
MERGE (b)<-[:AUTHOR]-(a)'
, {batchSize: 10000, iterateList: true});
这将生成图8-4中的图模式。
 图8-4.引文关系图
这是一个连接文章和作者的简单图表,因此我们将添加更多可以从关系中推断的信息,以帮助预测。
图8-4.引文关系图
这是一个连接文章和作者的简单图表,因此我们将添加更多可以从关系中推断的信息,以帮助预测。
合著关系图
我们希望预测未来作者之间的合作,所以我们将从创建一个合著关系图开始。以下Neo4j Cypher查询将在每对合作论文的作者之间创建合作作者关系:
MATCH (a1)<-[:AUTHOR]-(paper)-[:AUTHOR]->(a2:Author)
WITH a1, a2, paper
ORDER BY a1, paper.year
WITH a1, a2, collect(paper)[0].year AS year, count(*) AS collaborations
MERGE (a1)-[coauthor:CO_AUTHOR {year: year}]-(a2)
SET coauthor.collaborations = collaborations;
我们在查询中对合作作者关系设置的Year属性是这两个作者协作的最早年份。我们只对第一次有两位作者合作感兴趣,随后的合作与此无关。
图8-5是创建图的一部分示例(注意,这是一个很小的局部)。我们已经可以看到一些有趣的社区结构。
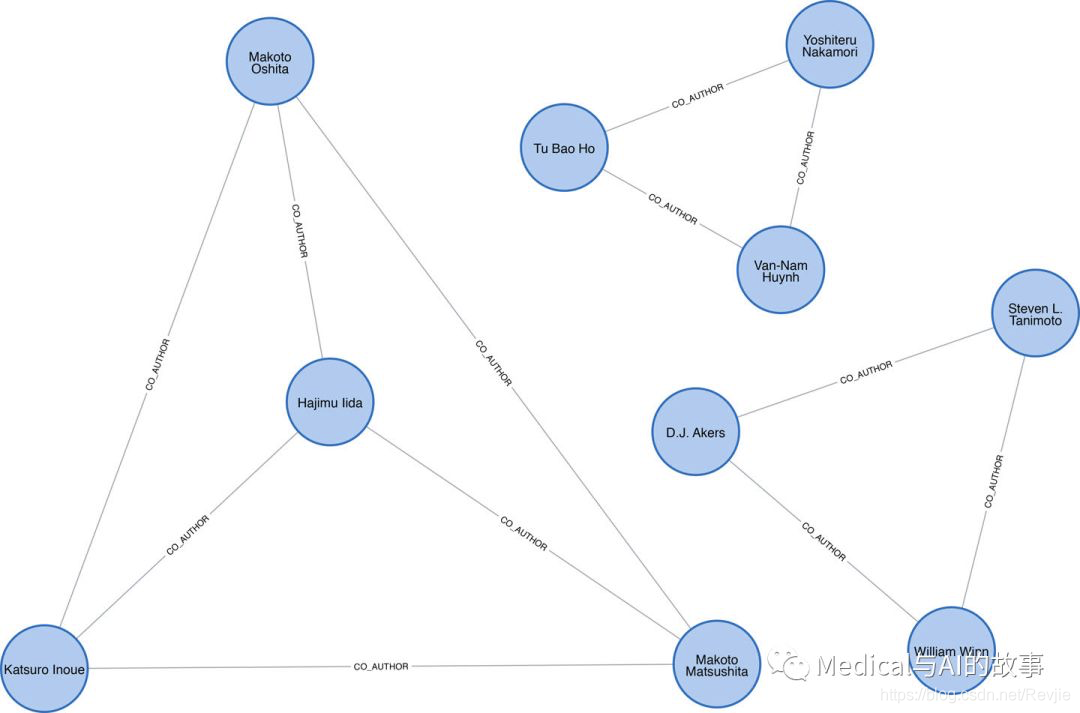 图8-5.合著者图
图中的每个圆代表一个作者,它们之间的线是CO_AUTHOR关系,因此我们有四个作者在左侧彼此协作,然后在右侧有三个合作作者的两个示例。现在我们已经加载了数据和一个基本的图表,让我们创建训练和测试需要的两个数据集。
图8-5.合著者图
图中的每个圆代表一个作者,它们之间的线是CO_AUTHOR关系,因此我们有四个作者在左侧彼此协作,然后在右侧有三个合作作者的两个示例。现在我们已经加载了数据和一个基本的图表,让我们创建训练和测试需要的两个数据集。
创建均衡(balanced)的训练和测试数据集
对于链接预测问题,我们希望尝试并预测未来创建的链接。这个数据集可以很好地实现这一点,因为我们在文章中有可以用来分割数据的日期。我们需要计算出用哪一年来定义我们的训练/测试划分。我们将在那一年之前对我们的模型进行各方面的训练,然后用那一年之后的样本创建链接上测试模型。 让我们先看看这些文章是什么时候发表的。我们可以编写以下查询来获取按年份分组的文章数:
query = """
MATCH (article:Article)
RETURN article.year AS year, count(*) AS count
ORDER BY year
"""
by_year = graph.run(query).to_data_frame()
让我们将其可视化为条形图,使用以下代码就可以做到:
plt.style.use('fivethirtyeight')
ax = by_year.plot(kind='bar', x='year', y='count', legend=None, figsize=(15,8))
ax.xaxis.set_label_text("")
plt.tight_layout()
plt.show()
我们可以在图8-6中看到执行此代码生成的图表。
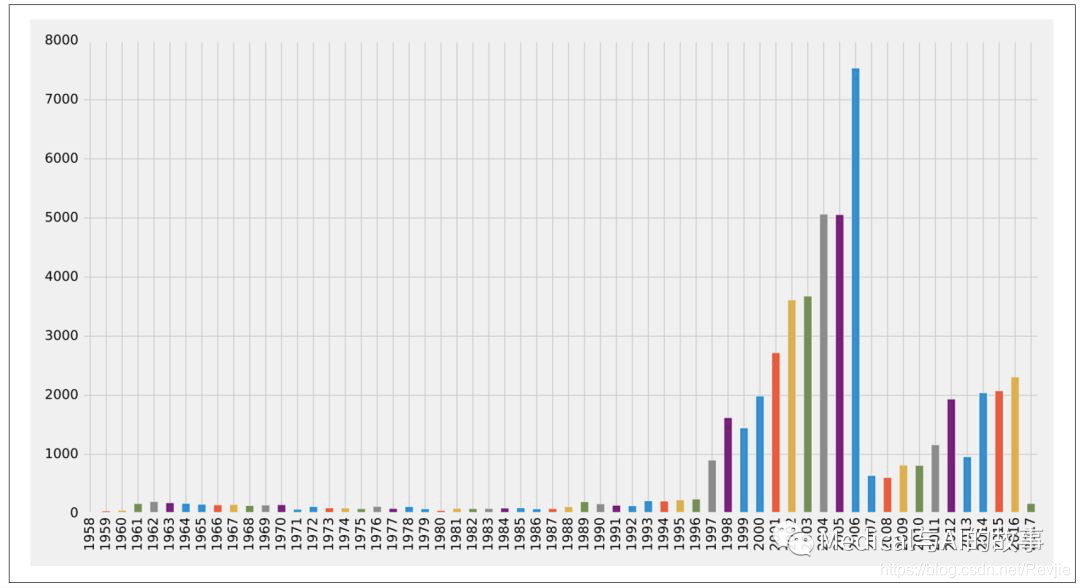 图8-6.按年份排列的文章
1997年之前发表的文章很少,2001年至2006年期间发表了大量文章,之后就减少了,然后是2011年以来的逐步攀升(2013年除外)。2006年似乎是一个很好的一年,可以将我们的数据分割开来,以训练我们的模型并做出预测。让我们看看那一年之前发表了多少论文,以及在那一年和那之后发表了多少论文。我们可以编写以下查询来计算:
图8-6.按年份排列的文章
1997年之前发表的文章很少,2001年至2006年期间发表了大量文章,之后就减少了,然后是2011年以来的逐步攀升(2013年除外)。2006年似乎是一个很好的一年,可以将我们的数据分割开来,以训练我们的模型并做出预测。让我们看看那一年之前发表了多少论文,以及在那一年和那之后发表了多少论文。我们可以编写以下查询来计算:
MATCH (article:Article)
RETURN article.year < 2006 AS training, count(*) AS count
其结果如下,其中true是指2006年之前发表的论文:
+----------+-------+
| training | count |
+----------+-------+
| false | 21059 |
| true | 30897 |
+----------+-------+
结果还不错!60%的论文在2006年之前发表,40%在2006年期间或之后发表。对于我们的训练和测试来说,这是一个相当均衡的数据分割。 现在我们有了一个很好的文件分割,让我们使用2006年的相同分割来进行合著。我们将在第一次合作是在2006年之前的两位作者之间建立一种CO_AUTHOR_EARLY关系。
MATCH (a1)<-[:AUTHOR]-(paper)-[:AUTHOR]->(a2:Author)
WITH a1, a2, paper
ORDER BY a1, paper.year
WITH a1, a2, collect(paper)[0].year AS year, count(*) AS collaborations
WHERE year < 2006
MERGE (a1)-[coauthor:CO_AUTHOR_EARLY {year: year}]-(a2)
SET coauthor.collaborations = collaborations;
然后,我们将在2006年或之后首次合作的两位作者之间建立CO_AUTHOR_LATE关系:
MATCH (a1)<-[:AUTHOR]-(paper)-[:AUTHOR]->(a2:Author)
WITH a1, a2, paper
ORDER BY a1, paper.year
WITH a1, a2, collect(paper)[0].year AS year, count(*) AS collaborations
WHERE year >= 2006
MERGE (a1)-[coauthor:CO_AUTHOR_LATE {year: year}]-(a2)
SET coauthor.collaborations = collaborations;
在构建我们的训练和测试集之前,让我们检查有多少对节点之间有链接。以下查询将找到CO_AUTHOR_EARLY的数量:
MATCH ()-[:CO_AUTHOR_EARLY]->()
RETURN count(*) AS count
运行该查询将返回此处显示的结果:
+-------+
| count |
+-------+
| 81096 |
+-------+
此查询将找到CO_AUTHOR_LATE的数目:
MATCH ()-[:CO_AUTHOR_LATE]->()
RETURN count(*) AS count
运行该查询将返回此结果:
+-------+
| count |
+-------+
| 74128 |
+-------+
现在我们已经准备好构建我们的训练和测试数据集了。

