
对图算法有兴趣的朋友可以关注微信公众号 :《 Medical与AI的故事》
原文链接:《图算法》第七章-3 图算法实践
用Apache Spark分析航班数据
在本节中,我们将使用不同的场景来说明使用Spark对美国机场数据的分析。假设你是一个数据科学家,有一个相当大的旅行时间表,想深入了解航空公司航班和航班延误的信息。我们将首先研究机场和航班信息,然后深入研究两个特定机场的延误情况。社区检测将用于分析路线,并找到我们的常飞点的最佳利用。
美国交通统计局提供了大量的交通信息。为了进行分析,我们将使用他们2018年5月的航空旅行准时性能数据,其中包括当月在美国始发和结束的航班。为了添加更多关于机场的细节,例如位置信息,我们还将从一个单独的源openflights加载数据。
让我们把数据载入spark。与前几节中的情况一样,我们的数据以csv文件的形式存在,这些文件在图书的Github存储库中可用。
nodes = spark.read.csv("data/airports.csv", header=False)
cleaned_nodes = (nodes.select("_c1", "_c3", "_c4", "_c6", "_c7")
.filter("_c3 = 'United States'")
.withColumnRenamed("_c1", "name")
.withColumnRenamed("_c4", "id")s
.withColumnRenamed("_c6", "latitude")
.withColumnRenamed("_c7", "longitude")
.drop("_c3"))
cleaned_nodes = cleaned_nodes[cleaned_nodes["id"] != "\\N”]
relationships = spark.read.csv("data/188591317_T_ONTIME.csv", header=True)
cleaned_relationships = (relationships
.select("ORIGIN", "DEST", "FL_DATE", "DEP_DELAY",
"ARR_DELAY", "DISTANCE", "TAIL_NUM", "FL_NUM",
"CRS_DEP_TIME", "CRS_ARR_TIME",
"UNIQUE_CARRIER")
.withColumnRenamed("ORIGIN", "src")
.withColumnRenamed("DEST", "dst")
.withColumnRenamed("DEP_DELAY", "deptDelay")
.withColumnRenamed("ARR_DELAY", "arrDelay")
.withColumnRenamed("TAIL_NUM", "tailNumber")
.withColumnRenamed("FL_NUM", "flightNumber")
.withColumnRenamed("FL_DATE", "date")
.withColumnRenamed("CRS_DEP_TIME", "time")
.withColumnRenamed("CRS_ARR_TIME", "arrivalTime")
.withColumnRenamed("DISTANCE", "distance")
.withColumnRenamed("UNIQUE_CARRIER", "airline")
.withColumn("deptDelay",
F.col("deptDelay").cast(FloatType()))
.withColumn("arrDelay",
F.col("arrDelay").cast(FloatType()))
.withColumn("time", F.col("time").cast(IntegerType()))
.withColumn("arrivalTime",
F.col("arrivalTime").cast(IntegerType()))
)
g = GraphFrame(cleaned_nodes, cleaned_relationships)
我们必须对节点进行一些清理,因为有些机场没有有效的机场代码。我们将为这些列提供更具描述性的名称,并将一些项转换为适当的数字类型。我们还需要确保有名为id、dst和src的列,正如Spark的graphframes库所预期的那样。
我们还将创建一个单独的DataFrame,将航空公司代码映射到航空公司名称。我们将在本章的后面部分使用:
airlines_reference = (spark.read.csv("data/airlines.csv")
.select("_c1", "_c3")
.withColumnRenamed("_c1", "name")
.withColumnRenamed("_c3", "code"))
airlines_reference = airlines_reference[airlines_reference["code"] != "null"]
探索性分析
让我们从一些探索性的分析开始,看看数据是什么样子的。 首先,让我们看看我们有多少机场:
g.vertices.count()
1435
我们在这些机场之间有几条连接线?
g.edges.count()
616529
热门机场
哪些机场起飞的航班最多?我们可以使用度中心性算法计算出从机场起飞的航班数:
airports_degree = g.outDegrees.withColumnRenamed("id", "oId”)
full_airports_degree = (airports_degree
.join(g.vertices, airports_degree.oId == g.vertices.id)
.sort("outDegree", ascending=False)
.select("id", "name", "outDegree”))
full_airports_degree.show(n=10, truncate=False)
如果运行该代码,我们将看到以下输出:
+-----+--------------------------------------------------+-----------+
| id | name | outDegree |
+-----+--------------------------------------------------+-----------+
| ATL | Hartsfield_Jackson_Atlanta_International_Airport | 33837 |
| ORD | Chicago_O’Hare_International_Airport | 28338 |
| DFW | Dallas_Fort_Worth_International_Airport | 23765 |
| CLT | Charlotte_Douglas_International_Airport | 20251 |
| DEN | Denver_International_Airport | 19836 |
| LAX | Los_Angeles_International_Airport | 19059 |
| PHX | Phoenix_Sky_Harbor_International_Airport | 15103 |
| SFO | San_Francisco_International_Airport | 14934 |
| LGA | La_Guardia_Airport | 14709 |
| IAH | George_Bush_Intercontinental_Houston_Airport | 14407 |
+-----+--------------------------------------------------+-----------+
大多数美国大城市都有受欢迎的机场,如Chicago、Atlanta、Los Angeles和New York。我们还可以使用以下代码创建外出航班的可视化表示:
plt.style.use('fivethirtyeight')
ax = (full_airports_degree.toPandas().head(10).plot(kind='bar', x='id', y='outDegree', legend=None))
ax.xaxis.set_label_text("")
plt.xticks(rotation=45)
plt.tight_layout()
plt.show()
结果图表如图7-11所示。
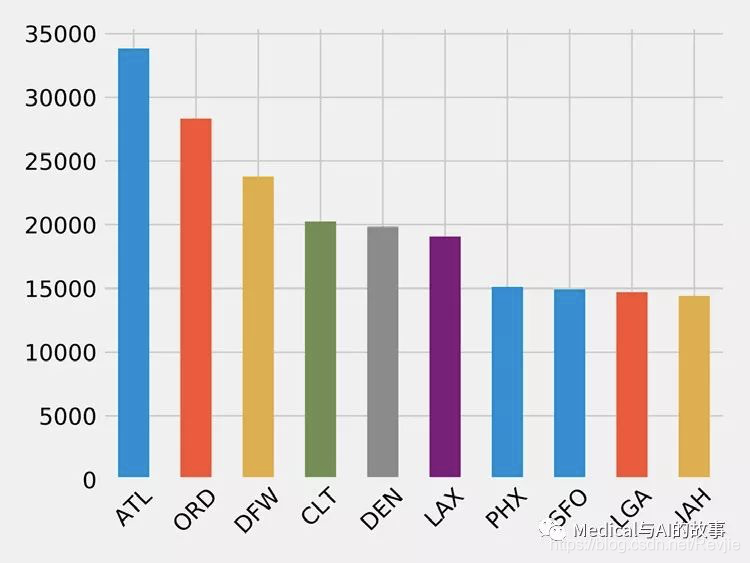 图7-11.机场离港航班
令人惊讶的是,航班数量突然减少的趋势。DEN(Denver International Airport)是第五大最受欢迎的机场,其出港航班数仅为ATL(Hartsfield Jackson Atlanta International Airport,ATL)的一半以上。
图7-11.机场离港航班
令人惊讶的是,航班数量突然减少的趋势。DEN(Denver International Airport)是第五大最受欢迎的机场,其出港航班数仅为ATL(Hartsfield Jackson Atlanta International Airport,ATL)的一半以上。
ORD机场的延误
在我们的场景中,我们经常在西海岸和东海岸之间旅行,希望通过ORD(Chicago O’Hare International Airport)这样的中间枢纽看到航班延误情况。这个数据集包含航班延误数据,所以我们可以直接进入。
以下代码按目的地机场分组得出从ORD起飞的航班的平均延误:
delayed_flights = (g.edges
.filter("src = 'ORD' and deptDelay > 0")
.groupBy("dst")
.agg(F.avg("deptDelay"), F.count("deptDelay"))
.withColumn("averageDelay",
F.round(F.col("avg(deptDelay)"), 2))
.withColumn("numberOfDelays",
F.col("count(deptDelay)")))
(delayed_flights
.join(g.vertices, delayed_flights.dst == g.vertices.id)
.sort(F.desc("averageDelay"))
.select("dst", "name", "averageDelay", "numberOfDelays")
.show(n=10, truncate=False))
一旦我们计算了按目的地分组的平均延迟,我们就用一个包含所有顶点的数据框连接生成的Spark DataFrame,这样我们就可以打印目的地机场的全名。运行此代码将返回延迟最严重的10个目的地:
+-----+---------------------------------------------+--------------+----------------+
| dst | name | averageDelay | numberOfDelays |
+-----+---------------------------------------------+--------------+----------------+
| CKB | North Central West Virginia Airport | 145.08 | 12 |
| OGG | Kahului Airport | 119.67 | 9 |
| MQT | Sawyer International Airport | 114.75 | 12 |
| MOB | Mobile Regional Airport | 102.2 | 10 |
| TTN | Trenton Mercer Airport | 101.18 | 17 |
| AVL | Asheville Regional Airport | 98.5 | 28 |
| ISP | Long Island Mac Arthur Airport | 94.08 | 13 |
| ANC | Ted Stevens Anchorage International Airport | 83.74 | 23 |
| BTV | Burlington International Airport | 83.2 | 25 |
| CMX | Houghton County Memorial Airport | 79.18 | 17 |
+-----+---------------------------------------------+--------------+----------------+
这很有趣,但有一个数据点非常突出:从ORD到CKB的12次航班平均延误超过2小时!让我们找出这些机场之间的航班,看看发生了什么:
from_expr = 'id = "ORD"'
to_expr = 'id = "CKB"'
ord_to_ckb = g.bfs(from_expr, to_expr)
ord_to_ckb = ord_to_ckb.select(
F.col("e0.date"),
F.col("e0.time"),
F.col("e0.flightNumber"),
F.col("e0.deptDelay"))
然后我们可以用以下代码绘制航班:
ax = (ord_to_ckb.sort("date").toPandas().plot(kind='bar', x='date', y='deptDelay', legend=None))
ax.xaxis.set_label_text("")
plt.tight_layout()
plt.show()
如果我们运行这个代码,我们将得到图7-12中的图表。
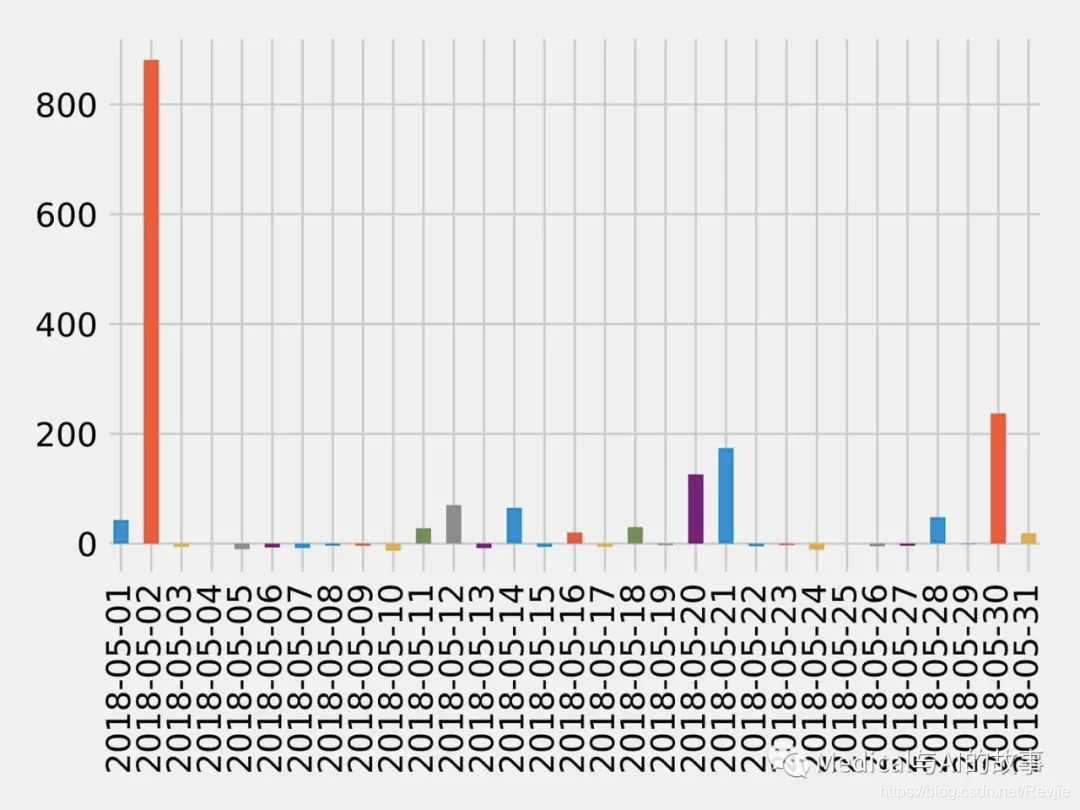 图7-12。从ORD到CKB的航班
图7-12。从ORD到CKB的航班
大约一半的航班被延误,但2018年5月2日超过14小时的延误已经严重扭曲了平均水平。
如果我们想发现进出沿海机场的延误怎么办?这些机场经常受到恶劣天气条件的影响,因此我们可能会发现一些有趣的延误。
在SFO糟糕的一天
让我们考虑一个机场的延误与雾有关的“低天花板”问题:SFO(San Francisco International Airport)。分析的一种方法是看motif,它们是反复出现的子图或模式。
 在Neo4j中和motif相当的概念是图模式(graph pattern)。图模式是用MATCH之类子句表的Cypher查询模式。
在Neo4j中和motif相当的概念是图模式(graph pattern)。图模式是用MATCH之类子句表的Cypher查询模式。
GraphFrame允许我们搜索motif,因此我们可以使用航班结构作为查询的一部分。让我们用主题来找出2018年5月11日进出旧金山的航班延误最多。以下代码将发现这些延迟:
motifs = (g.find("(a)-[ab]->(b); (b)-[bc]->(c)")
.filter("""(b.id = 'SFO') and
(ab.date = '2018-05-11' and bc.date = '2018-05-11') and
(ab.arrDelay > 30 or bc.deptDelay > 30) and
(ab.flightNumber = bc.flightNumber) and
(ab.airline = bc.airline) and
(ab.time < bc.time)"""))
这个motif (a)-[ab]->(b); (b)-[bc]->© 查找同一个机场进出航班。然后,我们过滤生成的模式以查找具有以下特征的航班:
- 第一班航班到达SFO,第二班航班离开SFO,两个航班形成一个sequence
- 抵达或离开旧金山时的延误超过30分钟
- 航班号和航空公司相同 然后我们可以获取结果并选择我们感兴趣的列:
result = (motifs.withColumn("delta", motifs.bc.deptDelay - motifs.ab.arrDelay)
.select("ab", "bc", "delta")
.sort("delta", ascending=False))
result.select(
F.col("ab.src").alias("a1"),
F.col("ab.time").alias("a1DeptTime"),
F.col("ab.arrDelay"),
F.col("ab.dst").alias("a2"),
F.col("bc.time").alias("a2DeptTime"),
F.col("bc.deptDelay"),
F.col("bc.dst").alias("a3"),
F.col("ab.airline"),
F.col("ab.flightNumber"),
F.col("delta")
).show()
我们还计算到港航班和离港航班之间的增量,这样可以看看哪些因素是归因于SFO。如果执行此代码,将得到以下结果:
+---------+--------------+-----+------------+----------+-----+------------+-----------+-----+-------+
| airline | flightNumber | a1 | a1DeptTime | arrDelay | a2 | a2DeptTime | deptDelay | a3 | delta |
+---------+--------------+-----+------------+----------+-----+------------+-----------+-----+-------+
| WN | 1454 | PDX | 1130 | -18.0 | SFO | 1350 | 178.0 | BUR | 196.0 |
| OO | 5700 | ACV | 1755 | -9.0 | SFO | 2235 | 64.0 | RDM | 73.0 |
| UA | 753 | BWI | 700 | -3.0 | SFO | 1125 | 49.0 | IAD | 52.0 |
| UA | 1900 | ATL | 740 | 40.0 | SFO | 1110 | 77.0 | SAN | 37.0 |
| WN | 157 | BUR | 1405 | 25.0 | SFO | 1600 | 39.0 | PDX | 14.0 |
| DL | 745 | DTW | 835 | 34.0 | SFO | 1135 | 44.0 | DTW | 10.0 |
| WN | 1783 | DEN | 1830 | 25.0 | SFO | 2045 | 33.0 | BUR | 8.0 |
| WN | 5789 | PDX | 1855 | 119.0 | SFO | 2120 | 117.0 | DEN | -2.0 |
| WN | 1585 | BUR | 2025 | 31.0 | SFO | 2230 | 11.0 | PHX | -20.0 |
+---------+--------------+-----+------------+----------+-----+------------+-----------+-----+-------+
最严重的情况是WN1454,它出现在最上面一排;它来得早,但出发晚了近三个小时。我们还可以看到arrDelay列中有一些负值;这意味着到SFO的航班偏早。
还请注意,一些航班,如WN5789和WN1585,在SFO的地面上弥补了时间,如图所示的负增量。
航空公司的互联机场
现在,假设我们已经旅行了很多次,我们决定使用那些频繁的飞行点,以尽可能有效地查看尽可能多的目的地,很快就会过期。如果我们从一个特定的美国机场出发,我们可以访问多少个不同的机场,然后使用同一家航空公司返回起始机场?
让我们首先确定所有的航空公司,并计算出每个航空公司有多少航班:
airlines = (g.edges
.groupBy("airline")
.agg(F.count("airline").alias("flights"))
.sort("flights", ascending=False))
full_name_airlines = (airlines_reference
.join(airlines, airlines.airline
== airlines_reference.code)
.select("code", "name", "flights"))
And now let’s create a bar chart showing our airlines:
ax = (full_name_airlines.toPandas()
.plot(kind='bar', x='name', y='flights', legend=None))
ax.xaxis.set_label_text("")
plt.tight_layout()
plt.show()
如果我们运行这个查询,我们将在图7-13中得到输出。
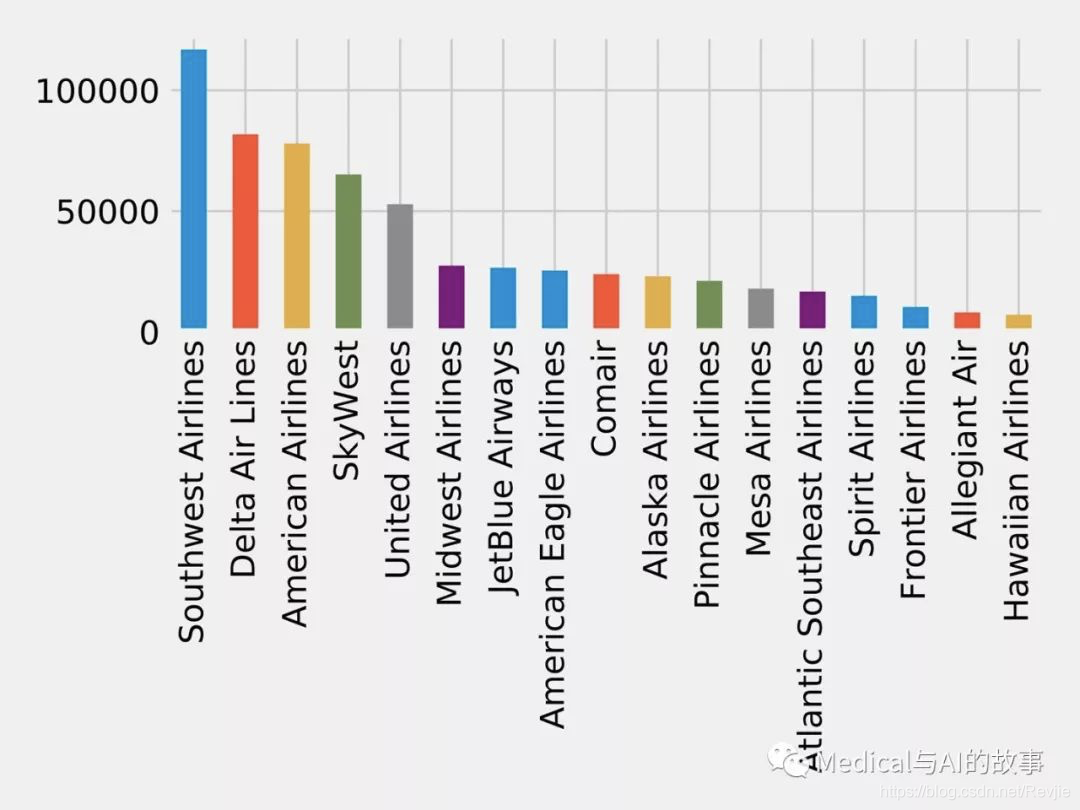 图7-13。航空公司的航班数
现在,让我们编写一个函数,该函数使用强连接组件算法查找每个航空公司的机场分组,其中所有机场都有往返该分组中所有其他机场的航班:
图7-13。航空公司的航班数
现在,让我们编写一个函数,该函数使用强连接组件算法查找每个航空公司的机场分组,其中所有机场都有往返该分组中所有其他机场的航班:
def find_scc_components(g, airline):
# Create a subgraph containing only flights on the provided airline airline_relationships = g.edges[g.edges.airline == airline] airline_graph = GraphFrame(g.vertices, airline_relationships)
# Calculate the Strongly Connected Components
scc = airline_graph.stronglyConnectedComponents(maxIter=10)
# Find the size of the biggest component and return that
return (scc
.groupBy("component") .agg(F.count("id").alias("size")) .sort("size", ascending=False) .take(1)[0]["size"])
我们可以编写以下代码来创建一个数据框架,其中包含每个航空公司及其最大强连接组件的机场数量:
# Calculate the largest strongly connected component for each airline
airline_scc = [(airline, find_scc_components(g, airline))
for airline in airlines.toPandas()["airline"].tolist()]
airline_scc_df = spark.createDataFrame(airline_scc, ['id', 'sccCount’])
# Join the SCC DataFrame with the airlines DataFrame so that we can show
# the number of flights an airline has alongside the number of
# airports reachable in its biggest component
airline_reach = (airline_scc_df
.join(full_name_airlines, full_name_airlines.code == airline_scc_df.id)
.select("code", "name", "flights", "sccCount")
.sort("sccCount", ascending=False))
And now let’s create a bar chart showing our airlines:
ax = (airline_reach.toPandas()
.plot(kind='bar', x='name', y='sccCount', legend=None))
ax.xaxis.set_label_text("")
plt.tight_layout()
plt.show()
如果我们运行这个查询,我们将在图7-14中得到输出。
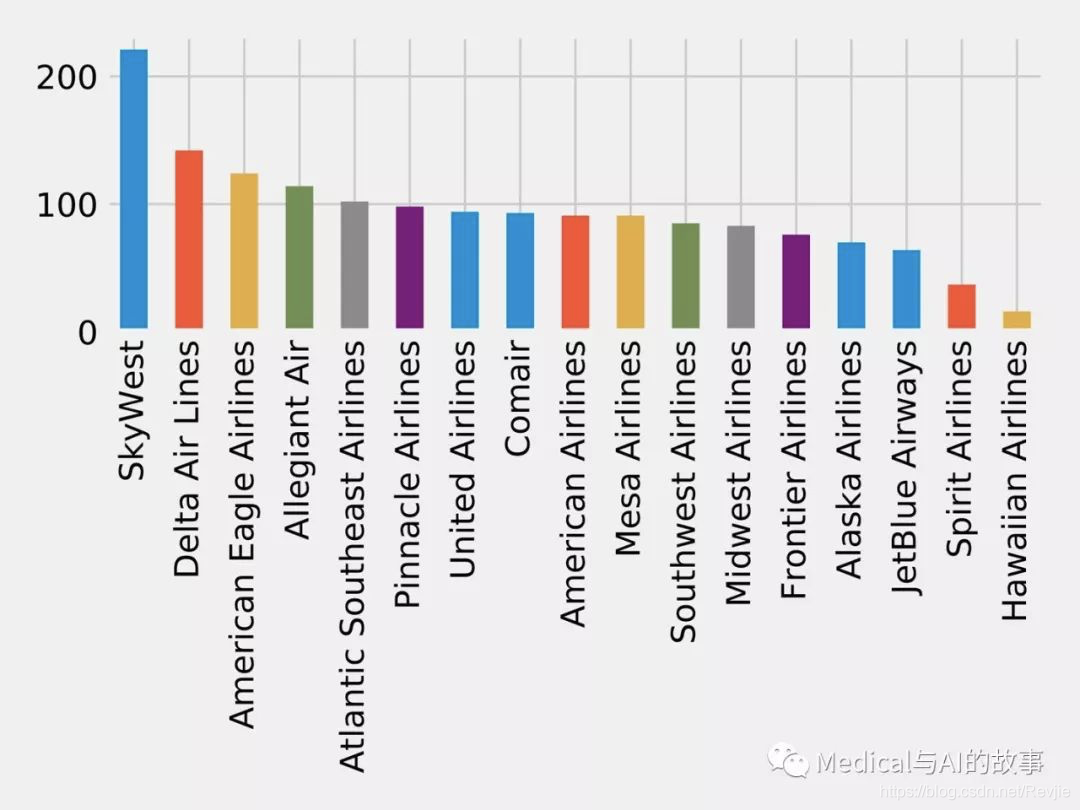 图7-14.航空公司可到达的机场数量
SkyWest拥有最大的社区,拥有200多个连接紧密的机场。这可能部分反映了其作为联属航空公司的商业模式,该公司运营合作航空公司航班中使用的飞机。另一方面,Southwest拥有最多的航班,但仅连接大约80个机场。
图7-14.航空公司可到达的机场数量
SkyWest拥有最大的社区,拥有200多个连接紧密的机场。这可能部分反映了其作为联属航空公司的商业模式,该公司运营合作航空公司航班中使用的飞机。另一方面,Southwest拥有最多的航班,但仅连接大约80个机场。
现在,让我们假设我们拥有的大多数常飞点都是Delta Airlines(DL)。我们能找到在特定航空公司网络内形成社区的机场吗?
airline_relationships = g.edges.filter("airline = 'DL'")
airline_graph = GraphFrame(g.vertices, airline_relationships)
clusters = airline_graph.labelPropagation(maxIter=10)
(clusters
.sort("label")
.groupby("label")
.agg(F.collect_list("id").alias("airports"),
F.count("id").alias("count"))
.sort("count", ascending=False)
.show(truncate=70, n=10))
如果运行该查询,我们将看到以下输出:
+---------------+------------------------------------------------------------------------+-------+
| label | airports | count |
+---------------+------------------------------------------------------------------------+-------+
| 1606317768706 | [IND, ORF, ATW, RIC, TRI, XNA, ECP, AVL, JAX, SYR, BHM, GSO, MEM, C… | 89 |
| 1219770712067 | [GEG, SLC, DTW, LAS, SEA, BOS, MSN, SNA, JFK, TVC, LIH, JAC, FLL, M… | 53 |
| 17179869187 | [RHV] | 1 |
| 25769803777 | [CWT] | 1 |
| 25769803776 | [CDW] | 1 |
| 25769803782 | [KNW] | 1 |
| 25769803778 | [DRT] | 1 |
| 25769803779 | [FOK] | 1 |
| 25769803781 | [HVR] | 1 |
| 42949672962 | [GTF] | 1 |
+---------------+------------------------------------------------------------------------+-------+
DL使用的大多数机场都分为两组,让我们深入研究一下。这里有太多的机场要显示,所以我们只显示最大度(degree)的机场(进出航班)。我们可以编写以下代码来计算每个机场的度:
all_flights = g.degrees.withColumnRenamed("id", "aId")
然后,我们将把它与属于最大集群的机场结合起来:
(clusters
.filter("label=1606317768706")
.join(all_flights, all_flights.aId == result.id)
.sort("degree", ascending=False)
.select("id", "name", "degree")
.show(truncate=False))
如果我们运行这个查询,我们将得到这个输出:
+-----+--------------------------------------------------------------+--------+
| id | name | degree |
+-----+--------------------------------------------------------------+--------+
| DFW | Dallas_Fort_Worth_International_Airport | 47514 |
| CLT | Charlotte_Douglas_International_Airport | 40495 |
| IAH | George_Bush_Intercontinental_Houston_Airport | 28814 |
| EWR | Newark_Liberty_International_Airport | 25131 |
| PHL | Philadelphia_International_Airport | 20804 |
| BWI | Baltimore/Washington_International_Thurgood_Marshall_Airport | 18989 |
| MDW | Chicago_Midway_International_Airport | 15178 |
| BNA | Nashville_International_Airport | 12455 |
| DAL | Dallas_Love_Field | 12084 |
| IAD | Washington_Dulles_International_Airport | 11566 |
| STL | Lambert_St_Louis_International_Airport | 11439 |
| HOU | William_P_Hobby_Airport | 9742 |
| IND | Indianapolis_International_Airport | 8543 |
| PIT | Pittsburgh_International_Airport | 8410 |
| CLE | Cleveland_Hopkins_International_Airport | 8238 |
| CMH | Port_Columbus_International_Airport | 7640 |
| SAT | San_Antonio_International_Airport | 6532 |
| JAX | Jacksonville_International_Airport | 5495 |
| BDL | Bradley_International_Airport | 4866 |
| RSW | Southwest_Florida_International_Airport | 4569 |
+-----+--------------------------------------------------------------+--------+
在图7-15中,我们可以看到这个集群实际上集中在美国中西部的东海岸。
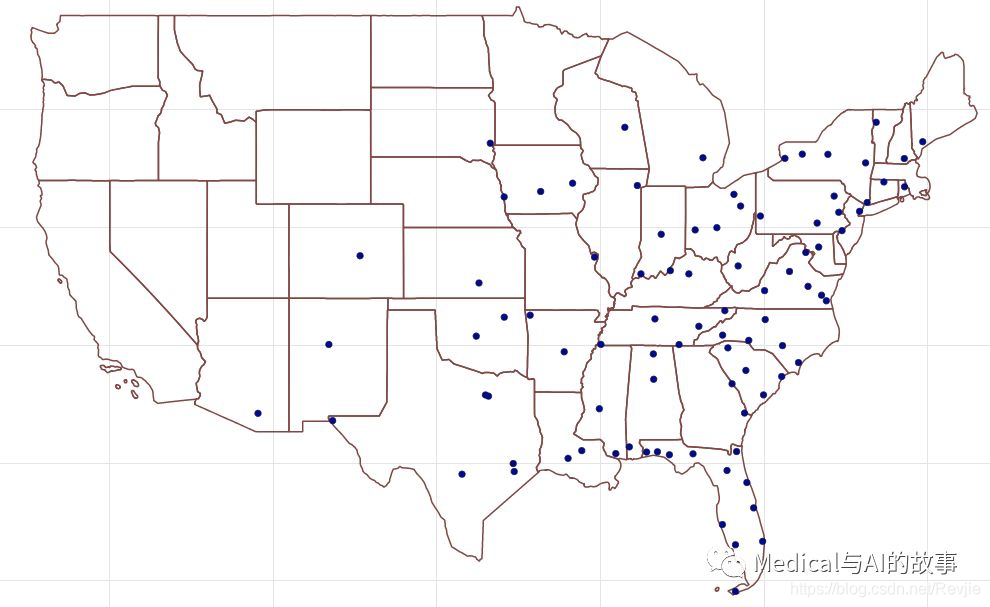 图7-15。集群1606317768706机场
图7-15。集群1606317768706机场
现在让我们对第二大集群做同样的事情:
(clusters
.filter("label=1219770712067")
.join(all_flights, all_flights.aId == result.id)
.sort("degree", ascending=False)
.select("id", "name", "degree")
.show(truncate=False))
如果运行该查询,我们将得到以下输出:
+-----+------------------------------------------------------------+--------+
| id | name | degree |
+-----+------------------------------------------------------------+--------+
| ATL | Hartsfield Jackson Atlanta International Airport | 67672 |
| ORD | Chicago O’Hare International Airport | 56681 |
| DEN | Denver International Airport | 39671 |
| LAX | Los Angeles International Airport | 38116 |
| PHX | Phoenix Sky Harbor International Airport | 30206 |
| SFO | San Francisco International Airport | 29865 |
| LGA | LA Guardia Airport | 29416 |
| LAS | McCarran International Airport | 27801 |
| DTW | Detroit Metropolitan Wayne County Airport | 27477 |
| MSP | Minneapolis-St Paul International/Wold-Chamberlain Airport | 27163 |
| BOS | General Edward Lawrence Logan International Airport | 26214 |
| SEA | Seattle Tacoma International Airport | 24098 |
| MCO | Orlando International Airport | 23442 |
| JFK | John F Kennedy International Airport | 22294 |
| DCA | Ronald Reagan Washington National Airport | 22244 |
| SLC | Salt Lake City International Airport | 18661 |
| FLL | Fort Lauderdale Hollywood International Airport | 16364 |
| SAN | San Diego International Airport | 15401 |
| MIA | Miami International Airport | 14869 |
| TPA | Tampa International Airport | 12509 |
+-----+------------------------------------------------------------+--------+
在图7-16中,我们可以看到这个集群显然更加集中于枢纽,沿途还有一些西北方向的站点。
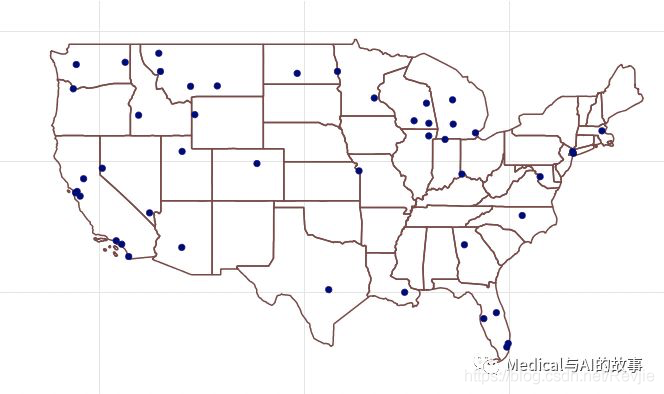 图7-16。集群1219770712067机场
我们用来生成这些映射的代码可以在书的Github存储库中找到。
在查看DL网站上的飞行常客计划时,我们注意到一个use-two-get-one-free(买二赠一)的促销计划。如果我们将积分用于两个航班,我们将免费获得另一个,但前提是我们在两个集群中的一个内飞行!用好我们的时间和得出来的成果,让我们在一个集群中飞行。
图7-16。集群1219770712067机场
我们用来生成这些映射的代码可以在书的Github存储库中找到。
在查看DL网站上的飞行常客计划时,我们注意到一个use-two-get-one-free(买二赠一)的促销计划。如果我们将积分用于两个航班,我们将免费获得另一个,但前提是我们在两个集群中的一个内飞行!用好我们的时间和得出来的成果,让我们在一个集群中飞行。
读者练习
- 使用最短路径算法评估从你家到Bozeman Yellowstone International Airport(BZN)的航班数量。
- 如果使用关系权重,有什么区别吗?
总结
在前面几章中,我们详细介绍了Apache Spark和Neo4j中用于路径查找、中心性和社区检测的关键图算法是如何工作的。
在本章中,我们介绍了一些工作流程,其中包括在其他任务和分析中使用几种算法。我们使用旅行业务场景分析Neo4j中的Yelp数据,并使用个人航空旅行场景评估Spark中的美国航空公司数据。
下一步,我们将研究图算法越来越重要的用途:用图来增强机器学习。