
对图算法有兴趣的朋友可以关注微信公众号 :《 Medical与AI的故事》
原文链接:《图算法》第七章-2 图算法实践
旅游商务咨询
作为我们咨询服务的一部分,当有影响力的客人写下他们的住宿情况时,酒店会收到通知,以便他们采取任何必要的行动。首先,我们来看看Bellagio的收视率,由最有影响力的评论家排序:
query = """\
MATCH (b:Business {name: $hotel})
MATCH (b)<-[:REVIEWS]-(review)<-[:WROTE]-(user)
WHERE exists(user.hotelPageRank)
RETURN user.name AS name,
user.hotelPageRank AS pageRank,review.stars AS stars
"""
with driver.session() as session:
params = { "hotel": "Bellagio Hotel" }
df = pd.DataFrame([dict(record) for record in session.run(query, params)]) df = df.round(2)
df = df[["name", "pageRank", "stars"]]
top_reviews = df.sort_values(by=["pageRank"], ascending=False).head(10)
print(tabulate(top_reviews, headers='keys', tablefmt='psql', showindex=False))
如果我们运行这个代码,我们将得到这个输出:
+-----------+--------------------+-------+
| name | pageRank | stars |
+-----------+--------------------+-------+
| Misti | 12.239516000000004 | 5 |
| Michael | 11.460049 | 4 |
| J | 11.431505999999997 | 5 |
| Erica | 10.993773 | 4 |
| Christine | 10.740770499999998 | 4 |
| Jeremy | 9.576763499999998 | 5 |
| Connie | 9.118103499999998 | 5 |
| Joyce | 7.621449000000001 | 4 |
| Henry | 7.299146 | 5 |
| Flora | 6.7570075 | 4 |
+-----------+--------------------+-------+
请注意,这些结果与我们之前的最佳酒店评估表不同。这是因为在这里,我们只关注那些评价Bellagio的评论家。
Bellagio酒店的客户服务团队情况良好。前10位有影响力的人都给出了酒店的良好排名。他们可能希望鼓励这些人再次访问并分享他们的经历。
有没有什么有影响力的客人体验很差?我们可以运行以下代码来查找页面排名最高的客人,他们的消费级别低于四星级:
query = """\
MATCH (b:Business {name: $hotel})
MATCH (b)<-[:REVIEWS]-(review)<-[:WROTE]-(user)
WHERE exists(user.hotelPageRank) AND review.stars < $goodRating
RETURN user.name AS name,user.hotelPageRank AS pageRank,review.stars AS stars
"""
with driver.session() as session:
params = { "hotel": "Bellagio Hotel", "goodRating": 4 }
df = pd.DataFrame([dict(record) for record in session.run(query, params)])
df = df.round(2)
df = df[["name", "pageRank", "stars”]]
top_reviews = df.sort_values(by=["pageRank"], ascending=False).head(10)
print(tabulate(top_reviews, headers='keys', tablefmt='psql', showindex=False))
如果我们运行该代码,将得到以下结果:
+----------+----------+-------+
| name | pageRank | stars |
+----------+----------+-------+
| Chris | 5.84 | 3 |
| Lorrie | 4.95 | 2 |
| Dani | 3.47 | 1 |
| Victor | 3.35 | 3 |
| Francine | 2.93 | 3 |
| Rex | 2.79 | 2 |
| Jon | 2.55 | 3 |
| Rachel | 2.47 | 3 |
| Leslie | 2.46 | 2 |
| Benay | 2.46 | 3 |
+----------+----------+-------+
我们排名最高的Bellagio用户,Chris和Lorrie,是排名前1000位最有影响力的用户(根据我们之前的查询结果),所以可能有必要进行个人接触。此外,由于许多评论人在逗留期间都会写文章,因此实时提醒有影响力的人可能会促进更积极的互动。
Bellagio交叉推广
在我们帮助他们找到有影响力的评论员之后,Bellagio现在要求我们在关系良好的客户的帮助下,帮助确定其他企业进行交叉推广。在我们的场景中,我们建议他们通过吸引来自不同类型社区的新客人来增加客户群。我们可以使用之前讨论过的中介中心性算法来计算出哪些Bellagio评论员不仅在整个Yelp网络中有很好的联系,而且还可以作为不同组之间的桥梁。
我们只对在Las Vegas寻找有影响力的人感兴趣,所以我们首先要标记这些用户:
MATCH (u:User)
WHERE exists((u)-[:WROTE]->()-[:REVIEWS]->()-[:IN_CITY]->(:City {name: "Las Vegas"}))
SET u:LasVegas
在我们的Las Vegas用户上运行中介中心性算法需要很长时间,因此我们将使用RA-Brandes变体。该算法通过采样节点计算中介性得分,并且仅探索到某个深度的最短路径。
经过一些实验,我们改进了一些参数设置不同于默认值的结果。我们将使用最多4个跳点的最短路径(maxDepth=4)并对20%的节点进行采样(概率为0.2)。请注意,增加跳数和节点数通常会提高准确性,但需要花费更多时间来计算结果。对于任何特定问题,最佳参数通常需要测试以识别收益递减点。
以下查询将执行算法并将结果存储在between属性中:
CALL algo.betweenness.sampled('LasVegas', 'FRIENDS',
{write: true, writeProperty: "between", maxDepth: 4, probability: 0.2}
)
在我们在查询中使用这些分数之前,让我们编写一个快速的探索性查询来查看分数的分布方式:
MATCH (u:User)
WHERE exists(u.between)
RETURN count(u.between) AS count,
avg(u.between) AS ave,
toInteger(percentileDisc(u.between, 0.5)) AS `50%`,
toInteger(percentileDisc(u.between, 0.75)) AS `75%`,
toInteger(percentileDisc(u.between, 0.90)) AS `90%`,
toInteger(percentileDisc(u.between, 0.95)) AS `95%`,
toInteger(percentileDisc(u.between, 0.99)) AS `99%`,
toInteger(percentileDisc(u.between, 0.999)) AS `99.9%`,
toInteger(percentileDisc(u.between, 0.9999)) AS `99.99%`,
toInteger(percentileDisc(u.between, 0.99999)) AS `99.999%`,
toInteger(percentileDisc(u.between, 1)) AS p100
如果我们运行该代码,将得到以下结果:
+--------+-------------+-----+-------+--------+---------+---------+----------+-----------+-----------+------------+
| count | ave | 50% | 75% | 90% | 95% | 99% | 99.9% | 99.99% | 99.999% | 100% |
+--------+-------------+-----+-------+--------+---------+---------+----------+-----------+-----------+------------+
| 506028 | 320538.6014 | 0 | 10005 | 318944 | 1001655 | 4436409 | 34854988 | 214080923 | 621434012 | 1998032952 |
+--------+-------------+-----+-------+--------+---------+---------+----------+-----------+-----------+------------+
我们有一半的用户得分为0,这意味着他们根本没有很好的联系。前1个百分位数(99%列)位于我们500000个用户组之间至少400万条最短路径上。综上所述,我们知道我们的大多数用户连接不良,但有一些用户对信息施加了很大的控制;这是小世界网络的典型行为。
我们可以通过运行以下查询来了解我们的超级连接者是谁:
MATCH(u:User)-[:WROTE]->()-[:REVIEWS]->(:Business {name:"Bellagio Hotel"})
WHERE exists(u.between)
RETURN u.name AS user,toInteger(u.between) AS betweenness,u.hotelPageRank AS pageRank, size((u)-[:WROTE]->()-[:REVIEWS]->()-[:IN_CATEGORY]->AS hotelReviews ORDER BY u.between DESC LIMIT 10
输出如下:
+-----------+-------------+--------------------+--------------+
| user | betweenness | pageRank | hotelReviews |
+-----------+-------------+--------------------+--------------+
| Misti | 841707563 | 12.239516000000004 | 19 |
| Christine | 236269693 | 10.740770499999998 | 16 |
| Erica | 235806844 | 10.993773 | 6 |
| Mike | 215534452 | NULL | 2 |
| J | 192155233 | 11.431505999999997 | 103 |
| Michael | 161335816 | 5.105143 | 31 |
| Jeremy | 160312436 | 9.576763499999998 | 6 |
| Michael | 139960910 | 11.460049 | 13 |
| Chris | 136697785 | 5.838922499999999 | 5 |
| Connie | 133372418 | 9.118103499999998 | 7 |
+-----------+-------------+--------------------+--------------+
我们在这里看到的一些人和之前在pagerank查询中看到的人一样,Mike是一个有趣的例外。他被排除在外,因为他没有审查足够的酒店(三家是底线),但似乎他在Las Vegas的Yelp世界中有相当好的联系。
为了接触更多的客户,我们将查看这些“连接者”显示的其他偏好,以了解我们应该推广什么。这些用户中的许多人也对餐馆进行了审查,因此我们编写以下查询,以找出他们最喜欢的餐馆:
// Find the top 50 users who have reviewed the Bellagio
MATCH (u:User)-[:WROTE]->()-[:REVIEWS]->(:Business {name:"Bellagio Hotel"}) WHERE u.between > 4436409
WITH u ORDER BY u.between DESC LIMIT 50
// Find the restaurants those users have reviewed in Las Vegas
MATCH (u)-[:WROTE]->(review)-[:REVIEWS]-(business)
WHERE (business)-[:IN_CATEGORY]->(:Category {name: "Restaurants"}) AND (business)-[:IN_CITY]->(:City {name: "Las Vegas"})
// Only include restaurants that have more than 3 reviews by these users
WITH business, avg(review.stars) AS averageReview, count(*) AS numberOfReviews WHERE numberOfReviews >= 3
RETURN business.name AS business, averageReview, numberOfReviews ORDER BY averageReview DESC, numberOfReviews DESC LIMIT 10
这个查询找到了我们最具影响力的50个连接者,并找到了Las Vegas最具影响力的10个餐厅,其中至少有3个人评价过该餐厅。如果我们运行它,我们将看到这里显示的输出:
+-----------------------------------+---------------+-----------------+
| business | averageReview | numberOfReviews |
+-----------------------------------+---------------+-----------------+
| Jean Georges Steakhouse | 5.0 | 6 |
| Sushi House Goyemon | 5.0 | 6 |
| Art of_Flavors | 5.0 | 4 |
| é by José Andrés | 5.0 | 4 |
| Parma By Chef Marc | 5.0 | 4 |
| Yonaka Modern Japanese | 5.0 | 4 |
| Kabuto | 5.0 | 4 |
| Harvest by Roy Ellamar | 5.0 | 3 |
| Portofino by Chef Michael LaPlaca | 5.0 | 3 |
| Montesano’s Eateria | 5.0 | 3 |
+-----------------------------------+---------------+-----------------+
我们现在可以建议Bellagio与这些餐厅联合举办一次促销活动,以吸引来自他们通常无法接触的群体的新客人。评价Bellagio的这些超级连接者,成为了我们评估哪些餐馆可能吸引新类型目标访客的代理。 既然我们已经帮助Bellagio接触到了新的群体,我们将了解如何使用社区检测来进一步改进我们的应用程序。
找到类似类别
当我们的最终用户使用该应用程序查找酒店时,我们希望展示他们可能感兴趣的其他业务。Yelp数据集包含1000多个类别,其中一些类别似乎彼此类似。我们将使用这种相似性为我们的用户可能会感兴趣的新业务提供应用内建议。
我们的图模型在类别之间没有任何关系,但是我们可以使用第二章的“单分图、二分图和K-分图”中描述的思想,根据企业如何对自己进行分类来构建一个类别相似性的图。
例如,假设只有一个企业将自己分类为酒店和历史旅游,如图7-8所示。
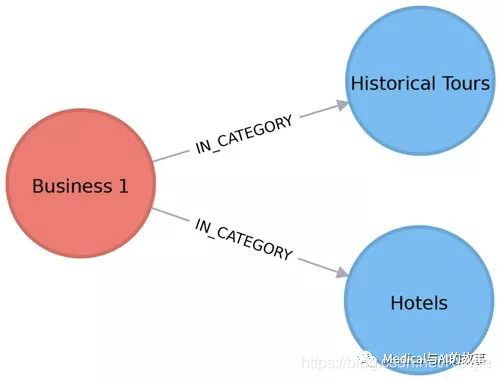 图7-8.有两个类别的企业
如图7-9所示,这将产生一个投影图,该图在酒店和历史旅游之间有一个权重为1的链接。
图7-8.有两个类别的企业
如图7-9所示,这将产生一个投影图,该图在酒店和历史旅游之间有一个权重为1的链接。
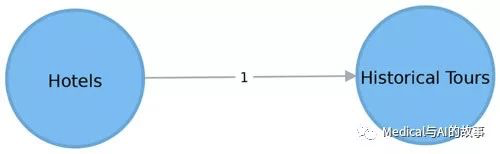 图7-9.投影类别图
在这种情况下,我们实际上不需要创建相似度图,而是可以运行社区检测算法,例如在投影的相似性图上进行标签传播。使用标签传播可以有效地将企业聚集在它们最为共同的超类别周围:
图7-9.投影类别图
在这种情况下,我们实际上不需要创建相似度图,而是可以运行社区检测算法,例如在投影的相似性图上进行标签传播。使用标签传播可以有效地将企业聚集在它们最为共同的超类别周围:
CALL algo.labelPropagation.stream(
'MATCH (c:Category) RETURN id(c) AS id',
'MATCH (c1:Category)<-[:IN_CATEGORY]-()-[:IN_CATEGORY]->(c2:Category)
WHERE id(c1) < id(c2)
RETURN id(c1) AS source, id(c2) AS target, count(*) AS weight',
{graph: "cypher"}
)
YIELD nodeId, label
MATCH (c:Category) WHERE id(c) = nodeId
MERGE (sc:SuperCategory {name: "SuperCategory-" + label})
MERGE (c)-[:IN_SUPER_CATEGORY]->(sc)
让我们给这些超类别一个更友好的名称,用他们最大类别的名称:
MATCH (sc:SuperCategory)<-[:IN_SUPER_CATEGORY]-(category)
WITH sc, category, size((category)<-[:IN_CATEGORY]-()) as size ORDER BY size DESC
WITH sc, collect(category.name)[0] as biggestCategory
SET sc.friendlyName = "SuperCat " + biggestCategory
我们可以在图7-10中看到类别和超类别的示例。
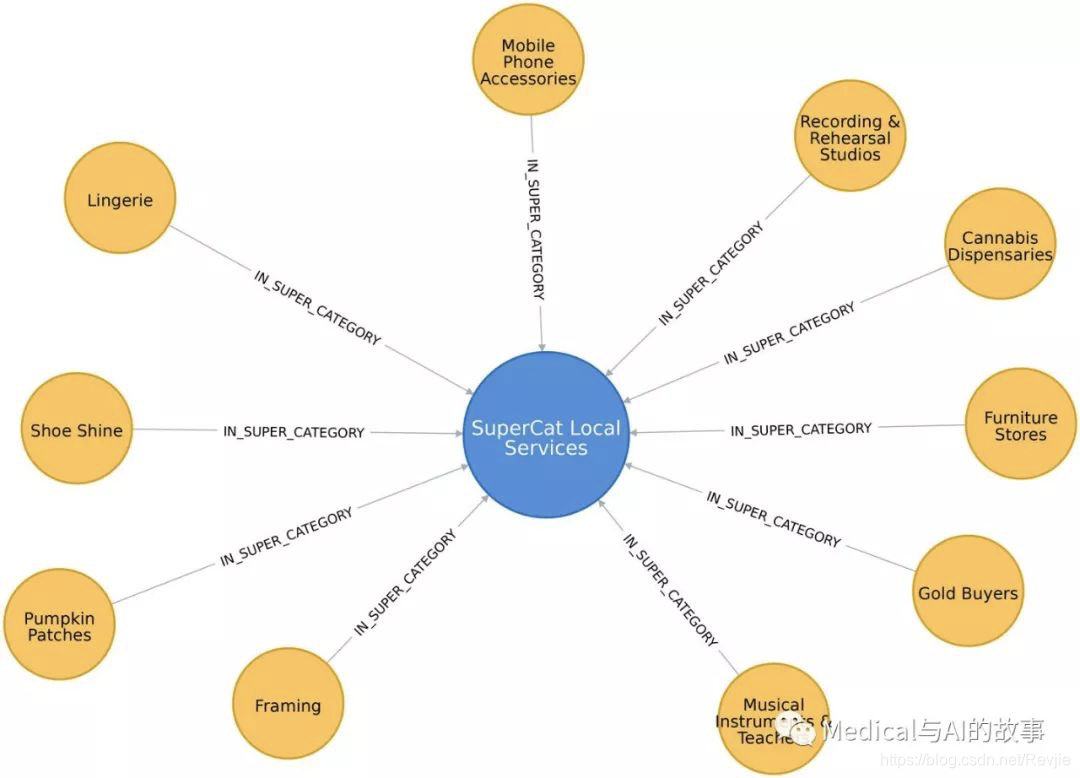 图7-10。类别和超类别
下面的查询查找与拉斯维加斯酒店最常见的类似类别:
图7-10。类别和超类别
下面的查询查找与拉斯维加斯酒店最常见的类似类别:
MATCH (hotels:Category {name: "Hotels"}),
(lasVegas:City {name: "Las Vegas"}), (hotels)-[:IN_SUPER_CATEGORY]->()<-[:IN_SUPER_CATEGORY]-(otherCategory)
RETURN otherCategory.name AS otherCategory,size((otherCategory)<-[:IN_CATEGORY]-(:Business)- [:IN_CITY]->(lasVegas)) AS businesses ORDER BY count DESC LIMIT 10
如果运行该查询,我们将看到以下输出:
+-------------------+------------+
| otherCategory | businesses |
+-------------------+------------+
| Tours | 189 |
| Car Rental | 160 |
| Limos | 84 |
| Resorts | 73 |
| Airport Shuttles | 52 |
| Taxis | 35 |
| Vacation Rentals | 29 |
| Airports | 25 |
| Airlines | 23 |
| Motorcycle Rental | 19 |
+-------------------+------------+
这些结果看起来很奇怪吗?显然,出租车和旅游不是酒店,但请记住,这是基于自我报告的分类。标签传播算法真正向我们展示的是这个相似性组中相邻的业务和服务。
现在,让我们在这些类别中找到一些评级高于平均水平的企业:
// Find businesses in Las Vegas that have the same SuperCategory as Hotels
MATCH (hotels:Category {name: "Hotels"}), (hotels)-[:IN_SUPER_CATEGORY]->()<-[:IN_SUPER_CATEGORY]-(otherCategory),
(otherCategory)<-[:IN_CATEGORY]-(business)
WHERE (business)-[:IN_CITY]->(:City {name: "Las Vegas"})
// Select 10 random categories and calculate the 90th percentile star rating
WITH otherCategory, count(*) AS count,
collect(business) AS businesses, percentileDisc(business.averageStars, 0.9) AS p90Stars
ORDER BY rand() DESC LIMIT 10
// Select businesses from each of those categories that have an average rating
// higher than the 90th percentile using a pattern comprehension
WITH otherCategory, [b in businesses where b.averageStars >= p90Stars] AS businesses
// Select one business per category
WITH otherCategory, businesses[toInteger(rand() * size(businesses))] AS business
RETURN otherCategory.name AS otherCategory, business.name AS business,
business.averageStars AS averageStars
在这个查询中,我们第一次使用模式理解(pattern comprehension)。模式理解是一种基于模式匹配创建列表的语法构造。它使用匹配子句和谓词的WHERE子句查找特定的模式,然后生成自定义投影。Cypher的这个功能是受GraphQL启发而来,GraphQL是一种用于API的查询语言。
如果运行该查询,将看到以下结果:
+-----------------------+-----------------------------------+-------------------+
| otherCategory | business | averageStars |
+-----------------------+-----------------------------------+-------------------+
| Motorcycle_Rental | Adrenaline_Rush_Slingshot_Rentals | 5.0 |
| Snorkeling | Sin_City_Scuba | 5.0 |
| Guest_Houses | Hotel_Del_Kacvinsky | 5.0 |
| Car_Rental | The_Lead_Team | 5.0 |
| Food_Tours | Taste_BUZZ_Food_Tours | 5.0 |
| Airports | Signature_Flight_Support | 5.0 |
| Public_Transportation | JetSuiteX | 4.6875 |
| Ski_Resorts | Trikke_Las_Vegas | 4.833333333333332 |
| Town_Car_Service | MW_Travel_Vegas | 4.866666666666665 |
| Campgrounds | McWilliams_Campground | 3.875 |
+-----------------------+-----------------------------------+-------------------+
然后,我们可以根据用户的即时应用程序行为实时提出建议。例如,当用户在浏览Las Vegas的酒店时,我们现在可以标注出邻近的高分企业。我们可以将这些方法推广到任何地方的任何业务类别,如餐馆或剧院。 读者练习 你能否绘制出一个城市酒店的评论随时间的变化情况? 对于特定的酒店或其他业务怎么办? 是否有流行趋势(季节性或其他)? 最有影响力的评审员是否只与其他有影响力的评审员联系起来?