
对图算法有兴趣的朋友可以关注微信公众号 :《 Medical与AI的故事》
原文链接:《图算法》第七章-1 图算法实践
随着我们越来越熟悉特定数据集上不同算法的行为,我们对图分析采用的方法也在不断发展。在本章中,我们将通过几个示例来帮助你更好地了解如何使用Yelp和美国运输部的数据集来处理大规模图数据分析。我们将在Neo4j中进行Yelp数据分析,其中包括数据的一般概述,组合算法以制定旅行建议,以及挖掘用户和业务数据以进行咨询。在Spark中,我们将查看美国航空公司数据,以了解不同航空公司的交通模式和延误以及机场如何连接。
由于寻路算法很简单,我们的示例将主要使用这些中心和社区检测算法:
- 用网页排名(PageRank)算法找到有影响力的Yelp评论员,然后关联他们对特定酒店的评分
- 用中介中心性(Betweenness Centrality)算法发现连接到多个组的审阅者,然后提取他们的偏好
- 用带有投影的标签传播(Label Propagation)算法来创建类似Yelp业务的超类别
- 用度中心性(Degree Centrality)算法快速识别美国运输数据集中的机场枢纽
- 用强连接组件(Strong Connected Component)查看美国机场路线集群
用Neo4j分析Yelp数据
Yelp帮助人们根据评论、偏好和建议找到当地企业。截至2018年底,已有超过1.8亿条评论发表在平台上。自2013年以来,Yelp开展了Yelp数据集挑战赛,这项竞赛鼓励人们探索和研究Yelp的开放数据集。 截至挑战的第12轮(2018年进行),开放数据集包括:
- 超过700万条评论和贴士
- 超过150万用户和28万张图片
- 超过188,000家企业拥有140万个属性
- 10个大都市地区 自从发布以来,这个数据集已经变得流行起来,数百篇学术论文都是用这种材料写的。Yelp数据集表示结构良好且高度互联的真实数据。这是一个很好的图算法展示,你也可以下载和探索。
Yelp社交网络
除了撰写和阅读商业评论,Yelp的用户还形成了一个社交网络。用户可以向浏览yelp.com时遇到的其他用户发送好友请求,也可以连接他们的通讯录或Facebook图结构。Yelp数据集还包括一个社交网络。图7-1是Mark Yelp简介的Friends部分的屏幕截图。
 图7-1.Mark的Yelp截图
很显然Mark需要更多的朋友,但是我们的重点是我们已经准备好开始了。为了说明我们如何分析Neo4j中的Yelp数据,我们将使用我们为旅游信息业务工作的场景。我们将首先研究Yelp数据,然后看看如何帮助人们使用我们的应用程序来计划旅行。我们将在Las Vegas等主要城市寻找好的住宿地点和工作建议。
图7-1.Mark的Yelp截图
很显然Mark需要更多的朋友,但是我们的重点是我们已经准备好开始了。为了说明我们如何分析Neo4j中的Yelp数据,我们将使用我们为旅游信息业务工作的场景。我们将首先研究Yelp数据,然后看看如何帮助人们使用我们的应用程序来计划旅行。我们将在Las Vegas等主要城市寻找好的住宿地点和工作建议。
我们业务场景的另一部分将涉及到旅游目的地业务的咨询。在一个例子中,我们将帮助酒店识别有影响力的访客,然后确定他们应该以交叉促销计划为目标的业务。
数据导入
有许多不同的方法可以将数据导入Neo4j,包括导入工具,我们在前面章节中看到的加载csv命令,以及neo4j驱动程序。对于Yelp数据集,我们需要一次性导入大量数据,因此导入工具是最佳选择。更多详情请参见附录的“Neo4j批量数据导入和Yelp”。
图模型
Yelp数据以图模型表示,如图7-2所示。
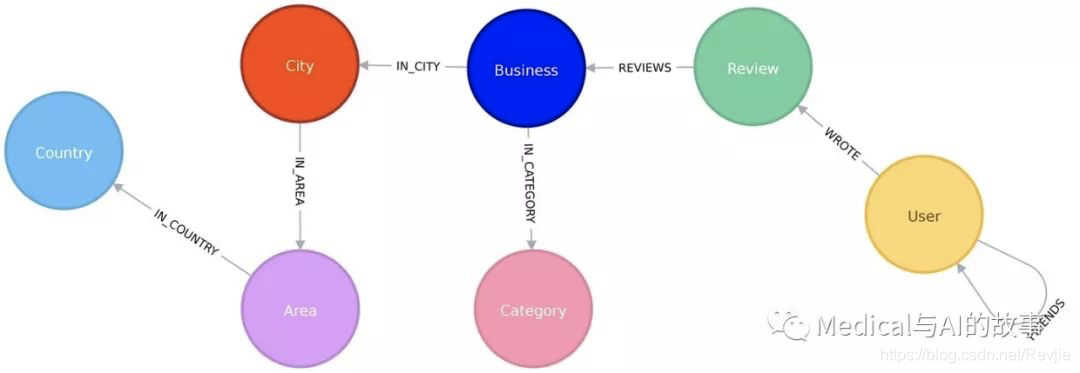 图7-2.Yelp图模型
我们的图包含标签为User的节点,这些节点与其他用户有FRIENDS关系。用户还可以撰写关于Business的Reviews和提示。所有元数据都存储为节点的属性,而业务类别除外。业务类别由单独的Category节点表示。对于位置数据,我们已经将City、Area和Country属性提取到子图中。在其他用例中,将其他属性提取到节点(如日期)或将节点折叠到关系(如审阅)可能是有意义的。
图7-2.Yelp图模型
我们的图包含标签为User的节点,这些节点与其他用户有FRIENDS关系。用户还可以撰写关于Business的Reviews和提示。所有元数据都存储为节点的属性,而业务类别除外。业务类别由单独的Category节点表示。对于位置数据,我们已经将City、Area和Country属性提取到子图中。在其他用例中,将其他属性提取到节点(如日期)或将节点折叠到关系(如审阅)可能是有意义的。
Yelp数据集还包括用户提示和照片,但我们不会在示例中使用这些提示和照片。
Yelp数据的快速概述
一旦我们在Neo4j中加载了数据,我们就会执行一些探索性查询。我们将询问每个类别中有多少节点或存在哪种类型的关系,以了解Yelp数据。以前我们已经为我们的Neo4j示例展示了Cypher查询,但我们可能正在从另一种编程语言执行这些查询。由于Python是数据科学家的首选语言,当我们想要将结果连接到Python生态系统中的其他库时,我们将在本节中使用Neo4j的Python驱动程序。如果我们只想显示查询结果,我们将直接使用Cypher。
我们还将展示如何将Neo4j与流行的pandas库相结合,这对于数据库之外的数据争论是有效的。我们将看到如何使用制表库来美化我们从pandas那里得到的结果,以及如何使用matplotlib创建数据的可视化表示。
我们还将使用Neo4j的APOC程序库来帮助我们编写更强大的Cypher查询。在附录的“APOC和其他Neo4j工具”中有关于APOC的更多信息。
让我们首先安装Python库:
pip3 install neo4j-driver tabulate pandas matplotlib
完成后我们将导入这些库:
from neo4j.v1 import GraphDatabase
import pandas as pd
from tabulate import tabulate
在macOS上导入matplotlib可能很繁琐,但以下几行应该可以解决问题:
import matplotlib
matplotlib.use('TkAgg')
import matplotlib.pyplot as plt
如果你在另一个操作系统上运行,则可能不需要中间的那一行。现在让我们创建一个指向本地Neo4j数据库的Neo4j驱动程序的实例:
driver = GraphDatabase.driver("bolt://localhost", auth=("neo4j", "neo")
 你需要用你自己的主机和凭据来修改上面这一行。
你需要用你自己的主机和凭据来修改上面这一行。
首先,让我们看一些节点和关系的一般数字。以下代码计算数据库中节点标签的基数(即,计算每个标签的节点数):
result = {"label": [], "count": []}
with driver.session() as session:
labels = [row["label"] for row in session.run("CALL db.labels()”)]
for label in labels:
query = f"MATCH (:`{label}`) RETURN count(*) as count"
count = session.run(query).single()["count"]
result["label"].append(label)
result["count"].append(count)
df = pd.DataFrame(data=result)
print(tabulate(df.sort_values("count"), headers='keys',tablefmt='psql', showindex=False))
如果运行该代码,我们将看到每个标签有多少个节点:
+----------+---------+
| label | count |
+----------+---------+
| Country | 17 |
| Area | 54 |
| City | 1093 |
| Category | 1293 |
| Business | 174567 |
| User | 1326101 |
| Review | 5261669 |
+----------+---------+
我们还可以使用以下代码创建基数的可视化表示:
plt.style.use('fivethirtyeight')
ax = df.plot(kind='bar', x='label', y='count', legend=None)
ax.xaxis.set_label_text("")
plt.yscale("log")
plt.xticks(rotation=45)
plt.tight_layout()
plt.show()
我们可以在图7-3中看到这个代码生成的图表。请注意,此图表使用的是对数刻度。
 图7-3.每个标签类别的节点数
同样,我们可以计算关系的基数:
图7-3.每个标签类别的节点数
同样,我们可以计算关系的基数:
result = {"relType": [], "count": []}
with driver.session() as session:
rel_types = [row["relationshipType"] for row in session.run ("CALL db.relationshipTypes()")]
for rel_type in rel_types:
query = f"MATCH ()-[:`{rel_type}`]->() RETURN count(*) as count”
count = session.run(query).single()["count”]
result["relType"].append(rel_type)
result["count"].append(count)
df = pd.DataFrame(data=result)
print(tabulate(df.sort_values("count"), headers='keys',tablefmt='psql', showindex=False))
如果运行该代码,我们将看到每种关系类型的数量:
+-------------+----------+
| relType | count |
+-------------+----------+
| IN_COUNTRY | 54 |
| IN_AREA | 1154 |
| IN_CITY | 174566 |
| IN_CATEGORY | 667527 |
| WROTE | 5261669 |
| REVIEWS | 5261669 |
| FRIENDS | 10645356 |
+-------------+----------+
我们可以看到图7-4中的基数图表。与节点基数图表一样,此图表使用的是对数比例。
 图7-4.按关系类型划分分组计算出来的关系数
这些查询不应该显示任何令人惊讶的信息,但是它们对于了解数据中的内容很有用。这还可以快速检查数据是否正确导入。
图7-4.按关系类型划分分组计算出来的关系数
这些查询不应该显示任何令人惊讶的信息,但是它们对于了解数据中的内容很有用。这还可以快速检查数据是否正确导入。
我们假设Yelp有很多酒店评论,但是在我们关注这个行业之前检查是有意义的。通过运行以下查询,我们可以了解该数据中有多少酒店企业以及它们有多少评论:
MATCH (category:Category {name: "Hotels"})
RETURN size((category)<-[:IN_CATEGORY]-()) AS businesses,size((:Review)-[:REVIEWS]->(:Business)-[:IN_CATEGORY]-> (category)) AS reviews
结果如下:
+------------+---------+
| businesses | reviews |
+------------+---------+
| 2683 | 183759 |
+------------+---------+
我们有很多业务要做,以为有好多的评论!在下一节中,我们将进一步探讨我们的业务场景中的数据。
旅行规划应用
为了在我们的应用程序中添加受欢迎的推荐,我们首先找到最受欢迎的酒店作为预订热门选择的启发式方法。我们可以补充一下,他们是如何被评价了解实际经验的。为了查看10家最受关注的酒店并绘制其评级分布,我们使用以下代码:
# Find the 10 hotels with the most reviews
query = """
MATCH (review:Review)-[:REVIEWS]->(business:Business),
(business)-[:IN_CATEGORY]->(category:Category {name: $category}),
(business)-[:IN_CITY]->(:City {name: $city})
RETURN business.name AS business, collect(review.stars) AS allReviews
ORDER BY size(allReviews) DESC
LIMIT 10
“""
fig = plt.figure()
fig.set_size_inches(10.5, 14.5)
fig.subplots_adjust(hspace=0.4, wspace=0.4)
with driver.session() as session:
params = { "city": "Las Vegas", "category": "Hotels”}
result = session.run(query, params)
for index, row in enumerate(result):
business = row["business"]
stars = pd.Series(row["allReviews”])
total = stars.count()
average_stars = stars.mean().round(2)
# Calculate the star distribution
stars_histogram = stars.value_counts().sort_index()
stars_histogram /= float(stars_histogram.sum())
# Plot a bar chart showing the distribution of star ratings
ax = fig.add_subplot(5, 2, index+1)
stars_histogram.plot(kind="bar", legend=None, color="darkblue",title=f"{business}\nAve: {average_stars}, Total:
{total}")
plt.tight_layout()
plt.show()
我们受城市和类别的限制,只能专注于Las Vegas的酒店。我们运行代码,得到图7-5中的图表。请注意,X轴代表酒店的星级,Y轴代表每个等级的总百分比。
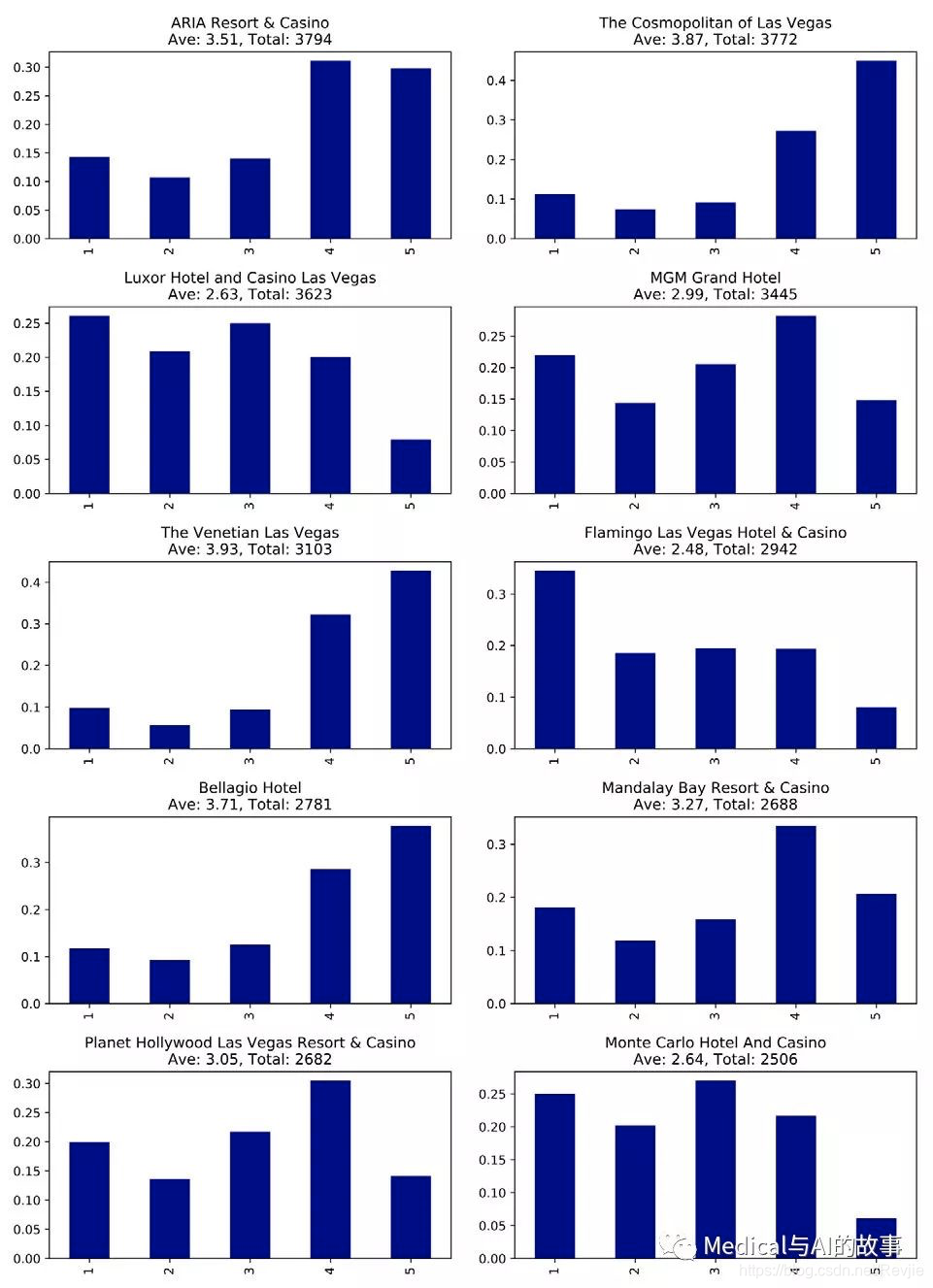 图7-5.最受欢迎的10家酒店,X轴上的星级数和Y轴上的总体评分百分比
这些酒店有很多评论,远远超过任何人可能读到的。最好是向我们的用户展示最相关评论的内容,并使它们在我们的应用程序中更加突出。为了进行这个分析,我们将从基本的图探索转向使用图算法。
图7-5.最受欢迎的10家酒店,X轴上的星级数和Y轴上的总体评分百分比
这些酒店有很多评论,远远超过任何人可能读到的。最好是向我们的用户展示最相关评论的内容,并使它们在我们的应用程序中更加突出。为了进行这个分析,我们将从基本的图探索转向使用图算法。
寻找有影响力的酒店评论
我们如何决定发布哪些评论呢?其中的一种方法是根据评论人对Yelp的影响来排序评论。我们将运行PageRank算法,对所有浏览过至少三家酒店的用户的投影图进行搜索。请记住,在前面的章节中,投影可以帮助过滤不必要的信息,并添加关系数据(有时是推断出来的关系)。我们将使用Yelp的朋友关系图作为用户之间的关系。PageRank算法将发现那些对更多用户有更大影响力的评论者,即使评论者和用户之间不是直接的朋友。
 如果两个人是朋友,他们之间有两种FRIENDS关系。例如,如果A和B是朋友,那么A和B之间会有FRIENDS关系,B和A之间会有FRIENDS关系。
如果两个人是朋友,他们之间有两种FRIENDS关系。例如,如果A和B是朋友,那么A和B之间会有FRIENDS关系,B和A之间会有FRIENDS关系。
我们需要编写一个查询,用三个以上的评论来投影用户的子图,然后在投影的子图上执行pagerank算法。
用一个小例子更容易理解子图投影是如何工作的。图7-6显示了三个共同的朋友Mark、Arya和Pravena的关系图。Mark和Pravena都对三家酒店进行了审查,并将成为投影图的一部分。另一方面,Arya只审查了一家酒店,因此将被排除在预测之外。
 图7-6.一个Yelp图的采样子图
我们的投影图只包括Mark和Pravena,如图7-7所示。
图7-6.一个Yelp图的采样子图
我们的投影图只包括Mark和Pravena,如图7-7所示。
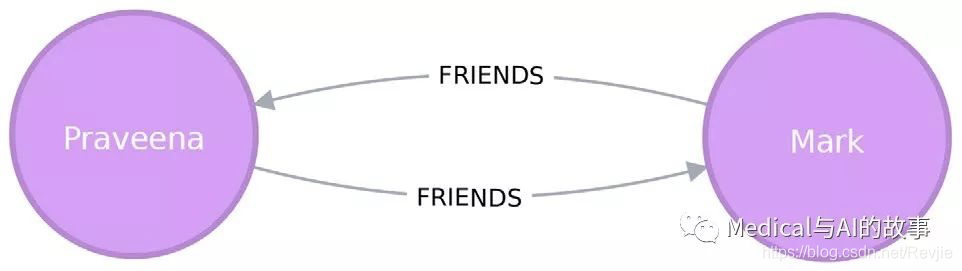 图7-7.我们的示例投影图
既然我们已经了解了图投影是如何工作的,那么让我们继续前进。下面的查询对投影图执行pagerank算法,并将结果存储在每个节点的hotelPageRank属性中:
图7-7.我们的示例投影图
既然我们已经了解了图投影是如何工作的,那么让我们继续前进。下面的查询对投影图执行pagerank算法,并将结果存储在每个节点的hotelPageRank属性中:
CALL algo.pageRank(
'MATCH (u:User)-[:WROTE]->()-[:REVIEWS]->()-[:IN_CATEGORY]->(:Category {name: $category})
WITH u, count(*) AS reviews
WHERE reviews >= $cutOff
RETURN id(u) AS id',
'MATCH (u1:User)-[:WROTE]->()-[:REVIEWS]->()-[:IN_CATEGORY]->(:Category {name: $category})
MATCH (u1)-[:FRIENDS]->(u2)
RETURN id(u1) AS source, id(u2) AS target',{graph: "cypher", write: true, writeProperty: "hotelPageRank",
params: {category: "Hotels", cutOff: 3}}
)
你可能已经注意到,我们没有设置第5章中讨论的阻尼因子或最大迭代限制。如果没有明确设置,Neo4j默认为0.85阻尼系数,maxIterations设置为20。 现在让我们看看pagerank值的分布,这样我们就知道如何过滤数据:
MATCH (u:User)
WHERE exists(u.hotelPageRank)
RETURN count(u.hotelPageRank) AS count,
avg(u.hotelPageRank) AS ave,
percentileDisc(u.hotelPageRank, 0.5) AS `50%`,
percentileDisc(u.hotelPageRank, 0.75) AS `75%`,
percentileDisc(u.hotelPageRank, 0.90) AS `90%`,
percentileDisc(u.hotelPageRank, 0.95) AS `95%`,
percentileDisc(u.hotelPageRank, 0.99) AS `99%`,
percentileDisc(u.hotelPageRank, 0.999) AS `99.9%`,
percentileDisc(u.hotelPageRank, 0.9999) AS `99.99%`,
percentileDisc(u.hotelPageRank, 0.99999) AS `99.999%`,
percentileDisc(u.hotelPageRank, 1) AS `100%`
如果我们运行这个查询,我们将得到这个输出:
+---------+-----------+------+------+----------+----------+----------+----------+----------+----------+----------+
| count | ave | 50% | 75% | 90% | 95% | 99% | 99.9% | 99.99% | 99.999% | 100% |
+---------+-----------+------+------+----------+----------+----------+----------+----------+----------+----------+
| 1326101 | 0.1614898 | 0.15 | 0.15 | 0.157497 | 0.181875 | 0.330081 | 1.649511 | 6.825738 | 15.27376 | 22.98046 |
+---------+-----------+------+------+----------+----------+----------+----------+----------+----------+----------+
为了解释这个百分比表,90%的值0.157497意味着90%的用户的pagerank得分比这个得分更低。99.99%反映了前0.0001%评审员的影响等级,100%仅仅表示的是最高的pagerank分数。
有趣的是,我们90%的用户的得分低于0.16,接近总体平均值,仅略高于通过pagerank算法初始化的0.15。这一数据似乎反映了幂律法则分布,其中有几个非常有影响力的评论家。
因为我们只想找到最有影响力的用户,所以我们将编写一个查询,它只查找pagerank分数在所有用户中排名前0.001%的用户。接下来的查询将查找pagerank分数高于1.64951的审阅者(请注意,这是99.9%的组):
// Only find users that have a hotelPageRank score in the top 0.001% of users
MATCH (u:User)
WHERE u.hotelPageRank > 1.64951
// Find the top 10 of those users
WITH u ORDER BY u.hotelPageRank DESC
LIMIT 10
RETURN u.name AS name,
u.hotelPageRank AS pageRank,
size((u)-[:WROTE]->()-[:REVIEWS]->()-[:IN_CATEGORY]-> (:Category {name: "Hotels"})) AS hotelReviews,
size((u)-[:WROTE]->()) AS totalReviews, size((u)-[:FRIENDS]-()) AS friends
如果运行该查询,我们将在此处看到结果:
+---------+--------------------+--------------+--------------+---------+
| name | pageRank | hotelReviews | totalReviews | friends |
+---------+--------------------+--------------+--------------+---------+
| Phil | 17.361242 | 15 | 134 | 8154 |
| Philip | 16.871013 | 21 | 620 | 9634 |
| Carol | 12.416060999999997 | 6 | 119 | 6218 |
| Misti | 12.239516000000004 | 19 | 730 | 6230 |
| Joseph | 12.003887499999998 | 5 | 32 | 6596 |
| Michael | 11.460049 | 13 | 51 | 6572 |
| J | 11.431505999999997 | 103 | 1322 | 6498 |
| Abby | 11.376136999999998 | 9 | 82 | 7922 |
| Erica | 10.993773 | 6 | 15 | 7071 |
| Randy | 10.748785999999999 | 21 | 125 | 7846 |
+---------+--------------------+--------------+--------------+---------+
这些结果表明Phil是最可信的评论人,尽管他没有评论过很多酒店。他可能和一些很有影响力的人有关系,但如果我们想要一系列新的评论,他的个人资料就不是最好的选择。Philip的分数稍低,但朋友最多,写评论的次数比Phil多五倍。虽然J写的评论最多,而且有相当数量的朋友,但J的pagerank分数并不是最高的,但仍在前10名。对于我们的应用程序,我们选择突出显示来自Phil、Philip和J的酒店评论,为我们提供适当的影响者和评论数量组合。 既然我们已经通过相关的评论改进了我们的应用内建议,那么让我们转到业务的另一个方面:咨询。