
对图算法有兴趣的朋友可以关注微信公众号 :《 Medical与AI的故事》
原文链接:《图算法》第六章-2 社区检测算法
强连接组件
强连接组件(Strongly Connected Components,SCC)算法是最早的图算法之一。SCC在有向图中查找连接的节点集,其中每个节点都可以从同一集中的任何其他节点的两个方向上访问。它的运行时操作伸缩性很好,与节点数量成比例。在图6-5中,你可以看到SCC组中的节点不需要是直接邻居,但是在集合中的所有节点之间必须有方向路径。
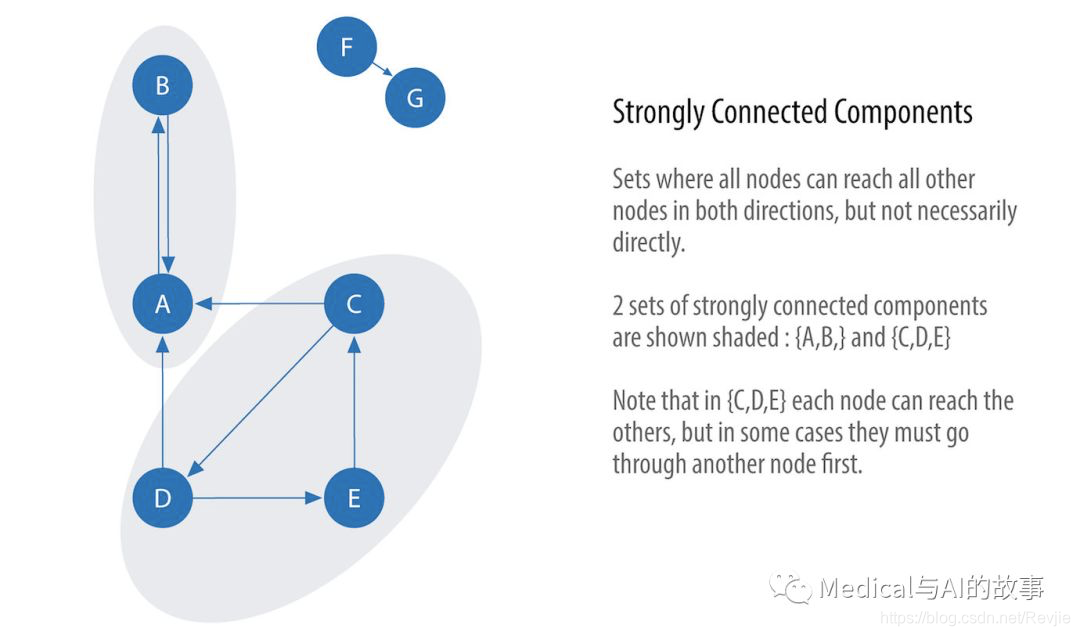 图6-5.强连接组件
图6-5.强连接组件
 将有向图分解为强连接的组件是深度优先搜索算法的经典应用。Neo4j把DFS作为SCC算法的内部实现的一部分。
将有向图分解为强连接的组件是深度优先搜索算法的经典应用。Neo4j把DFS作为SCC算法的内部实现的一部分。
强连接组件的使用场景
使用强连接组件作为图分析的早期步骤,以了解图的结构,或确定可能需要独立调查的紧密集群。对于推荐引擎等应用程序,可以使用强连接的组件来分析组中的类似行为或关注的重点。
类似SCC的许多社区检测算法被用于查找集群并将其折叠为单个节点,以便进一步进行集群间分析。您还可以使用SCC来可视化分析的周期,例如查找可能死锁的进程,因为每个子进程都在等待另一个成员采取操作。
示例用例包括:
- 如S. Vitali、J. B. Glattfelder和S. Battiston对强大跨国公司的分析“The Network of Global Corporate Control”,找出每个成员直接和/或间接拥有其他成员股份的一组公司。
- 测量多重调接式无线网络中的路由性能时,计算不同网络配置的连接性。阅读M.K.Marina和S.R.Das的“Routing Performance in the Presence of Unidirectional Links in Multihop Wireless Networks”中的更多内容。
- 在许多仅适用于强连接图的图算法中,SCC会充当第一步。在社交网络中,我们发现了许多紧密相连的群体。在这些集合中,人们通常有类似的偏好,SCC算法用于查找此类组,并向尚未购买的组员推荐可能喜欢的页面或可能购买的产品。
 有些算法有摆脱无限循环的策略。如果我们正在编写自己的算法或寻找非终止进程,我们可以使用scc来检查循环。
有些算法有摆脱无限循环的策略。如果我们正在编写自己的算法或寻找非终止进程,我们可以使用scc来检查循环。
Apache Spark的强连接组件
我们从Apache Spark开始考察算法。我们先导入Spark和GraphFrames所需的包。
from graphframes import *
from pyspark.sql import functions as F
现在我们已经准备好之行强连接组件算法。我们将会用它来判断是否在图中有环形依赖。
 如果在两个节点之间有双向的通路,这两个节点只能在同一个强连接组件中。
如果在两个节点之间有双向的通路,这两个节点只能在同一个强连接组件中。
我们编写代码如下:
result = g.stronglyConnectedComponents(maxIter=10)
(result.sort("component")
.groupby("component")
.agg(F.collect_list("id").alias("libraries"))
.show(truncate=False))
在PySpark中运行,得到如下的结果:
+-------------+-----------------+
|component |libraries |
+-------------+-----------------+
|180388626432 |[jpy-core] |
|223338299392 |[spacy] |
|498216206336 |[numpy] |
|523986010112 |[six] |
|549755813888 |[pandas] |
|558345748480 |[nbconvert] |
|661424963584 |[ipykernel] |
|721554505728 |[jupyter] |
|764504178688 |[jpy-client] |
|833223655424 |[pytz] |
|910533066752 |[python-dateutil]|
|936302870528 |[pyspark] |
|944892805120 |[matplotlib] |
|1099511627776|[jpy-console] |
|1279900254208|[py4j] |
+-------------+-----------------+
您可能会注意到每个库节点都被分配给一个唯一的组件。这和我们的预期相同,每个节点都在其自己的分区(partition)中。这意味着我们的软件项目在这些库之间没有循环依赖关系。
Neo4j上的强连接组件
让我们使用Neo4j运行相同的算法。执行以下查询以运行算法:
CALL algo.scc.stream("Library", "DEPENDS_ON")
YIELD nodeId, partition
RETURN partition, collect(algo.getNodeById(nodeId)) AS libraries
ORDER BY size(libraries) DESC
传递的参数如下
 以下是运行之后的结果
以下是运行之后的结果
+--------------------------------------------------+
| partition | libraries |
+--------------------------------------------------+
| 0 | [(:Library {id: "six"})] |
| 1 | [(:Library {id: "pandas"})] |
| 2 | [(:Library {id: "numpy"})] |
| 3 | [(:Library {id: "python-dateutil"})] |
| 4 | [(:Library {id: "pytz"})] |
| 5 | [(:Library {id: "pyspark"})] |
| 6 | [(:Library {id: "matplotlib"})] |
| 7 | [(:Library {id: "spacy"})] |
| 8 | [(:Library {id: "py4j"})] |
| 9 | [(:Library {id: "jupyter"})] |
| 10 | [(:Library {id: "jpy-console"})] |
| 11 | [(:Library {id: "nbconvert"})] |
| 12 | [(:Library {id: "ipykernel"})] |
| 13 | [(:Library {id: "jpy-client"})] |
| 14 | [(:Library {id: "jpy-core"})] |
+--------------------------------------------------+
与Spark示例一样,每个节点都在自己的分区中。
到目前为止,算法仅仅展示了我们的Python库的行为非常好。让我们在图中创建一个循环依赖项,让事情更有趣。这意味着我们将有一些节点在同一个分区中。
以下查询添加了一个额外的库,该库在py4j和pyspark之间创建循环依赖关系:
MATCH (py4j:Library {id: "py4j"})
MATCH (pyspark:Library {id: "pyspark"})
MERGE (extra:Library {id: "extra"})
MERGE (py4j)-[:DEPENDS_ON]->(extra)
MERGE (extra)-[:DEPENDS_ON]->(pyspark)
我们能够在图6-6中清晰地看到这个循环依赖。
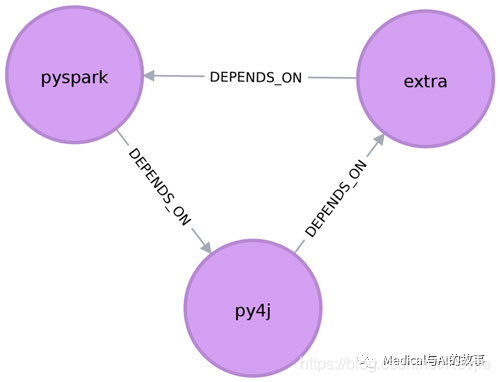 图6-6 在pyspark,py4j和extra之间的循环依赖
我们现在可以运行SCC算法来看是否有不同的结果。
图6-6 在pyspark,py4j和extra之间的循环依赖
我们现在可以运行SCC算法来看是否有不同的结果。
+---------------------------------------------------------------------------------------------+
| partition | libraries |
+---------------------------------------------------------------------------------------------+
| 5 | [(:Library {id: "pyspark"}), (:Library {id: "py4j"}), (:Library {id: "extra"})] |
| 0 | [(:Library {id: "six"})] |
| 1 | [(:Library {id: "pandas"})] |
| 2 | [(:Library {id: "numpy"})] |
| 3 | [(:Library {id: "python-dateutil"})] |
| 4 | [(:Library {id: "pytz"})] |
| 6 | [(:Library {id: "matplotlib"})] |
| 7 | [(:Library {id: "spacy"})] |
| 9 | [(:Library {id: "jupyter"})] |
| 10 | [(:Library {id: "jpy-console"})] |
| 11 | [(:Library {id: "nbconvert"})] |
| 12 | [(:Library {id: "ipykernel"})] |
| 13 | [(:Library {id: "jpy-client"})] |
| 14 | [(:Library {id: "jpy-core"})] |
+---------------------------------------------------------------------------------------------+
pyspark、py4j和extra都是同一分区的一部分,SCC帮助我们找到了循环依赖关系!
在继续下一个算法之前,我们将从图中删除额外的库及其关系:
MATCH (extra:Library {id: "extra"})
DETACH DELETE extra
连接组件
连接组件算法(Connected Components,有时称为联合查找或弱连接组件)在无向图中查找连接节点集,其中每个节点都可以从同一集中的任何其他节点访问。它不同于SCC算法,因为它只需要在一个方向上的节点对之间存在路径,而SCC需要在两个方向上都存在路径。BernardA.Galler和MichaelJ.Fischer在1964年的论文“An Improved Equivalence Algorithm”中首次描述了这种算法。
连接组件的使用场景
与SCC一样,连接的组件通常在分析的早期用于理解图的结构。因为它可以有效地伸缩,所以考虑使用此算法来处理需要频繁更新的图。它可以快速显示组之间的新节点,这对于欺诈检测等分析非常有用。
建立起来这样的习惯:事先运行连接组件来测试图是否连接,作为一般图分析的准备步骤。执行这个快速测试可以避免在图的一个孤岛组件上运行算法,那最终会得到不正确的结果。 示例用例包括:
- 跟踪数据库记录的集群,作为删除重复数据过程的一部分。重复数据删除是主数据管理应用程序中的一项重要任务;该方法在A.Monge和C.Elkan的“An Efficient Domain-Independent Algorithm for Detecting Approximately Duplicate Database Records”中有更详细的描述。
- 分析引文网络。一项研究使用连接的组件来计算一个网络连接的好坏,然后看看如果“集线器”或“权威”节点从图中移走,连接是否仍然存在。本用例将在Y. AN、J.C.M. Janssen和E. E. Milios的论文“Characterizing and Mining Citation Graph of Computer Science Literature”中进一步解释。
Apache Spark上的连接组件
从Apache Spark上先开始,我们将首先从Spark和GraphFrames包中导入所需的包:
from pyspark.sql import functions as F
现在我们准备执行连接组件算法。
现在我们准备执行连接组件算法。
 如果两个节点之间有一条路径,则两个节点可以位于同一连接组件中。
为此,我们编写以下代码:
如果两个节点之间有一条路径,则两个节点可以位于同一连接组件中。
为此,我们编写以下代码:
spark.sparkContext.setCheckpointDir('/home/retire2053/checkpoint')
result = g.connectedComponents()
(result.sort("component")
.groupby("component")
.agg(F.collect_list("id").alias("libraries"))
.show(truncate=False))
运行连接组件算法需要预先提供一个checkpoint目录,并使用setCheckpiontDir方法来实现。运行代码,将会得到如下的结果:
+------------+------------------------------------------------------------------+
|component |libraries |
+------------+------------------------------------------------------------------+
|180388626432|[jpy-core, nbconvert, ipykernel, jupyter, jpy-client, jpy-console]|
|223338299392|[spacy, numpy, six, pandas, pytz, python-dateutil, matplotlib] |
|936302870528|[pyspark, py4j] |
+------------+------------------------------------------------------------------+
这个结果显示了三个节点的聚类,在图6-7中可以看到
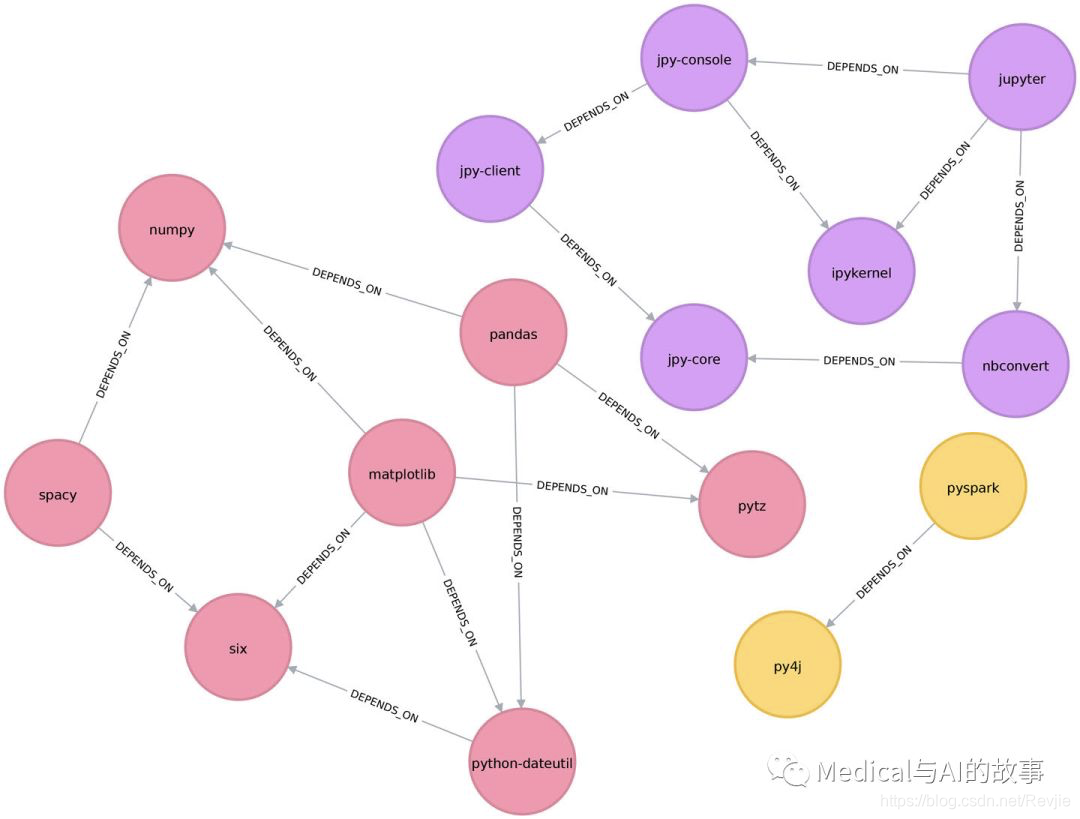 图6-7.通过连接组件算法找到的群集
图6-7.通过连接组件算法找到的群集
在这个例子中,很容易看到仅仅通过目视检查就有三个组件。该算法在较大的图上显示出更多的价值,在这些图中,视觉检查不可能或非常耗时。
Neo4j上的连接组件
我们还可以通过运行以下查询在Neo4j中执行此算法:
CALL algo.unionFind.stream("Library", "DEPENDS_ON")
YIELD nodeId,setId
RETURN setId, collect(algo.getNodeById(nodeId)) AS libraries
ORDER BY size(libraries) DESC
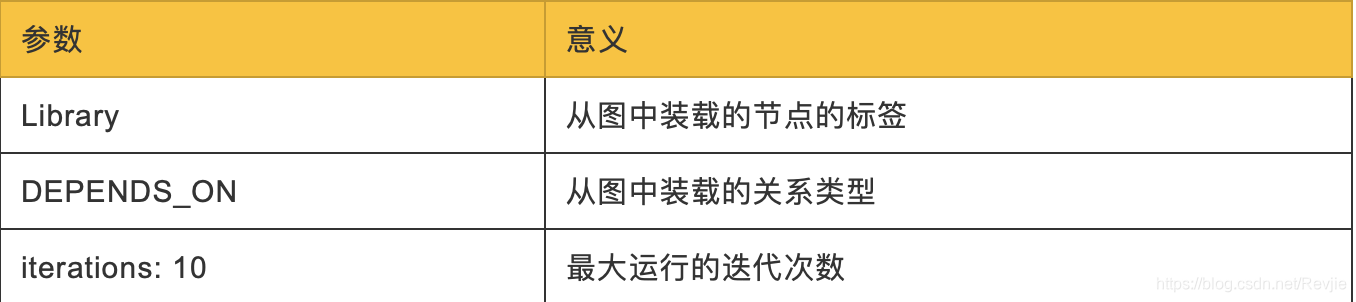
传入该算法的参数如下: Library:从图中装载的节点的标签 DEPENDS_ON:从图中装载的关系类型 以下是输出的结果:
+-------+--------------------------------------------------------------------------------------+
| setId | libraries |
+-------+--------------------------------------------------------------------------------------+
| 1 | [ "six", "pandas", "numpy", "python-dateutil", "pytz", "matplotlib", "spacy"] |
| 9 | [ "jupyter", "jpy-console", "nbconvert", "ipykernel", "jpy-client", "jpy-core"] |
| 5 | [ "pyspark", "py4j"] |
+-------+--------------------------------------------------------------------------------------+
正如预期的那样,我们得到的结果与Spark完全相同。 到目前为止,我们所讨论的两种社区检测算法都是确定性的:每次运行它们时,它们返回相同的结果。接下来的两个算法是非确定性算法的例子,如果我们多次运行它们,即使在相同的数据上,也可能会看到不同的结果。
标签传播
标签传播算法( Label Propagation algorithm,LPA)是一种在图中快速查找社区的算法。在LPA中,节点根据其直接邻居选择其组。这个过程非常适合在分组不太清晰,但权重可以用来帮助节点确定将自己放在哪个社区中的那些网络。它也适合半监督学习,因为您可以用预先分配的、指示性的节点标签为进程种子。
该算法的灵感是,在一组密集连接的节点中,单个标签可以很快占据主导地位,但在穿越稀疏连接区域时会遇到困难。标签被困在一组密集连接的节点中,当算法完成时,最终具有相同标签的节点被视为同一社区的一部分。该算法通过将成员资格分配给具有最高组合关系和节点权重的标签邻域来解决重叠,其中节点可能是多个集群的一部分。
LPA是U. N. Raghavan, R. Albert, 和 S. Kumara于2007年在题为“Near Linear Time Algorithm to Detect Community Structures in Large-Scale Networks”的论文中提出的一种相对较新的算法。
图6-8描述了标签传播的两种变化,一种是简单的push方法,另一种是依赖关系权重的更典型的pull方法。pull方法很适合并行化。
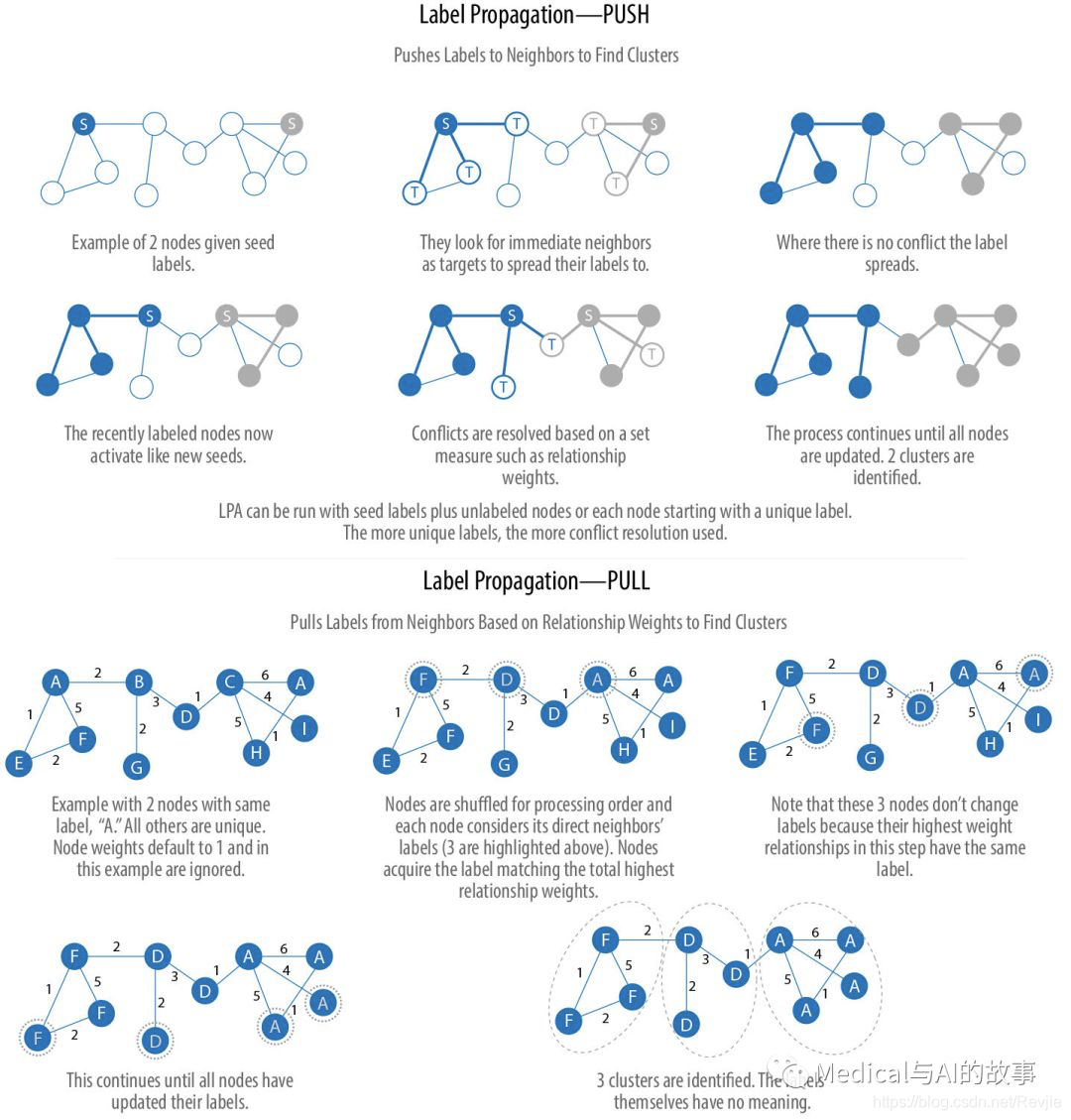 图6-8.标签传播的两种变体
图6-8.标签传播的两种变体
标签传播pull方法常用的步骤有:
- 每个节点都用一个唯一的标签(标识符)初始化,并且可以使用可选的初步的“种子”标签。
- 这些标签通过网络传播。
- 在每次传播迭代中,每个节点更新其标签以匹配具有最大权重的节点,该权重是根据相邻节点的权重及其关系计算得出的。
- 当每个节点都有其相邻节点的大多数标签时,LPA就会达到收敛。 随着标签的传播,密集连接的节点群很快就在一个独特的标签上达成共识。在传播结束时,只保留少数标签,具有相同标签的节点属于同一个社区。
半监督学习和种子标签
与其他算法不同,标签传播可以在同一个图上多次运行时返回不同的社区结构。LPA评估节点的顺序可能会影响最终的社区形成结果。
当某些节点被赋予初始标签(即种子标签),而其他节点则没有标记,最终方案的范围就在缩小。未标记的节点更可能采用初步标记。
标签传播的这种使用可以被认为是一种半监督学习方法来寻找社区。半监督学习是一类机器学习任务和技术,它对少量标记数据以及大量未标记数据进行操作。我们还可以在图演化时在图上重复运行该算法。
最后,LPA有时不收敛于单个解决方案。在这种情况下,我们的社区结果将不断地在几个非常相似的社区之间切换,并且算法永远不会完成。种子标签有助于引导它走向解决方案。
Spark和Neo4j使用一组最大迭代次数来避免无休止的执行。你应该测试数据的迭代设置,以平衡准确性和执行时间。
标签传播的使用场景
在大型网络中使用标签传播进行初始社区检测,特别是在有权重的情况下。该算法可以并行化,因此在图划分方面速度非常快。 示例用例包括:
- 将Tweet的极性指定为语义分析的一部分。在这个场景中,来自分类器的正种子标签和负种子标签与Twitter关注图相结合使用。有关更多信息,请参见M. Speriosu等人的“Twitter Polarity Classification with Label Propagation over Lexical Links and the Follower Graph”。
- 根据化学相似性和副作用特征,找出可能的联合处方药物的潜在危险组合。参见P.Zhang等人的论文“Label Propagation Prediction of Drug–Drug Interactions Based on Clinical Side Effects”。
- 推断机器学习模型的对话特征和用户意图。有关更多信息,请参阅Y. Murase等人的论文“Feature Inference Based on Label Propagation on Wikidata Graph for DST”。
在Apache Spark上使用标签传播
让我们从Apache Spark开始,首先从Spark和GraphFrames包中导入所需的包:
from pyspark.sql import functions as F
我们开始运行LPA,以下是代码:
result = g.labelPropagation(maxIter=10)
(result
.sort("label")
.groupby("label")
.agg(F.collect_list("id"))
.show(truncate=False))
运行代码,将会得到如下的结果:
+-------------+-----------------------------------+
|label |collect_list(id) |
+-------------+-----------------------------------+
|180388626432 |[jpy-core, jpy-console, jupyter] |
|223338299392 |[matplotlib, spacy] |
|498216206336 |[python-dateutil, numpy, six, pytz]|
|549755813888 |[pandas] |
|558345748480 |[nbconvert, ipykernel, jpy-client] |
|936302870528 |[pyspark] |
|1279900254208|[py4j] |
+-------------+-----------------------------------+
与连接组件算法相比,本例中有更多的库的集群。就如何确定集群而言,LPA比连接组件的标准更松散。使用标签传播可以发现两个相互邻近的节点(直接连接的节点)位于不同的集群中。但是,使用连接组件,节点将始终与它的相邻节点处于同一个集群中,因为该算法严格基于关系进行分组。
在我们的示例中,最明显的区别是jupyter库分处于两个社区,一个包含库的核心部分,另一个包含面向客户机的工具。
Neo4j上的LPA
现在让我们用Neo4j上尝试同样的算法。我们可以通过运行以下查询来执行LPA:
CALL algo.labelPropagation.stream("Library", "DEPENDS_ON",
{ iterations: 10 })
YIELD nodeId, label
RETURN label,
collect(algo.getNodeById(nodeId).id) AS libraries
ORDER BY size(libraries) DESC
传给该查询的参数如下:
 得到的结果如下:
得到的结果如下:
+---------------------------------------------------------------------------+
| label | libraries |
+---------------------------------------------------------------------------+
| 14 | ["jupyter", "jpy-console", "nbconvert", "jpy-client", "jpy-core"] |
| 0 | ["six", "python-dateutil", "matplotlib"] |
| 2 | ["pandas", "numpy", "spacy"] |
| 8 | ["pyspark", "py4j"] |
| 4 | ["pytz"] |
| 12 | ["ipykernel"] |
+---------------------------------------------------------------------------+
在图6-9中可以看到这个结果,和再Apache Spark中得到的结果类似。
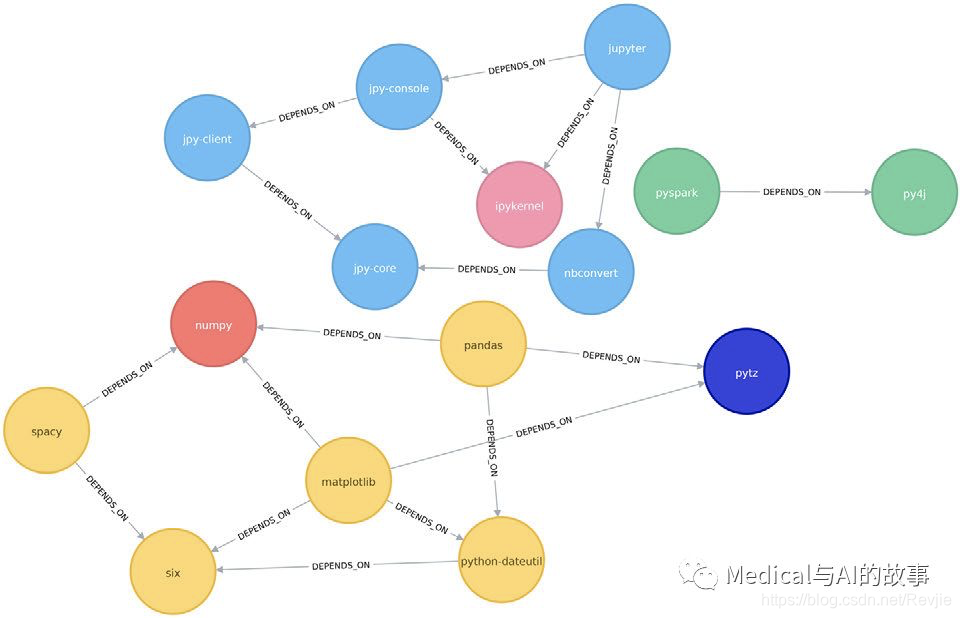 图6-9.标签传播算法发现的聚类
我们也可以在假设图是无向的情况下运行该算法,这意味着节点将尝试采用它们所依赖的库以及依赖这些库的库中的标签。
图6-9.标签传播算法发现的聚类
我们也可以在假设图是无向的情况下运行该算法,这意味着节点将尝试采用它们所依赖的库以及依赖这些库的库中的标签。
为此,我们将 DIRECTION:BOTH参数都传递给算法:
CALL algo.labelPropagation.stream("Library", "DEPENDS_ON",
{ iterations: 10, direction: "BOTH" })
YIELD nodeId, label
RETURN label,
collect(algo.getNodeById(nodeId).id) AS libraries
ORDER BY size(libraries) DESC
如果运行程序,得到如下的结果:
+----------------------------------------------------------------------------------------+
| label | libraries |
+----------------------------------------------------------------------------------------+
| 2 | ["six", "pandas", "numpy", "python-dateutil", "pytz", "matplotlib", "spacy"] |
| 14 | ["jupyter", "jpy-console", "nbconvert", "ipykernel", "jpy-client", "jpy-core"] |
| 5 | ["pyspark", "py4j"] |
+----------------------------------------------------------------------------------------+
聚类的数量从6个减少到了4个,图中matplotlib部分的所有节点现在都分组在一起。这可以在图6-10中更清楚地看到。
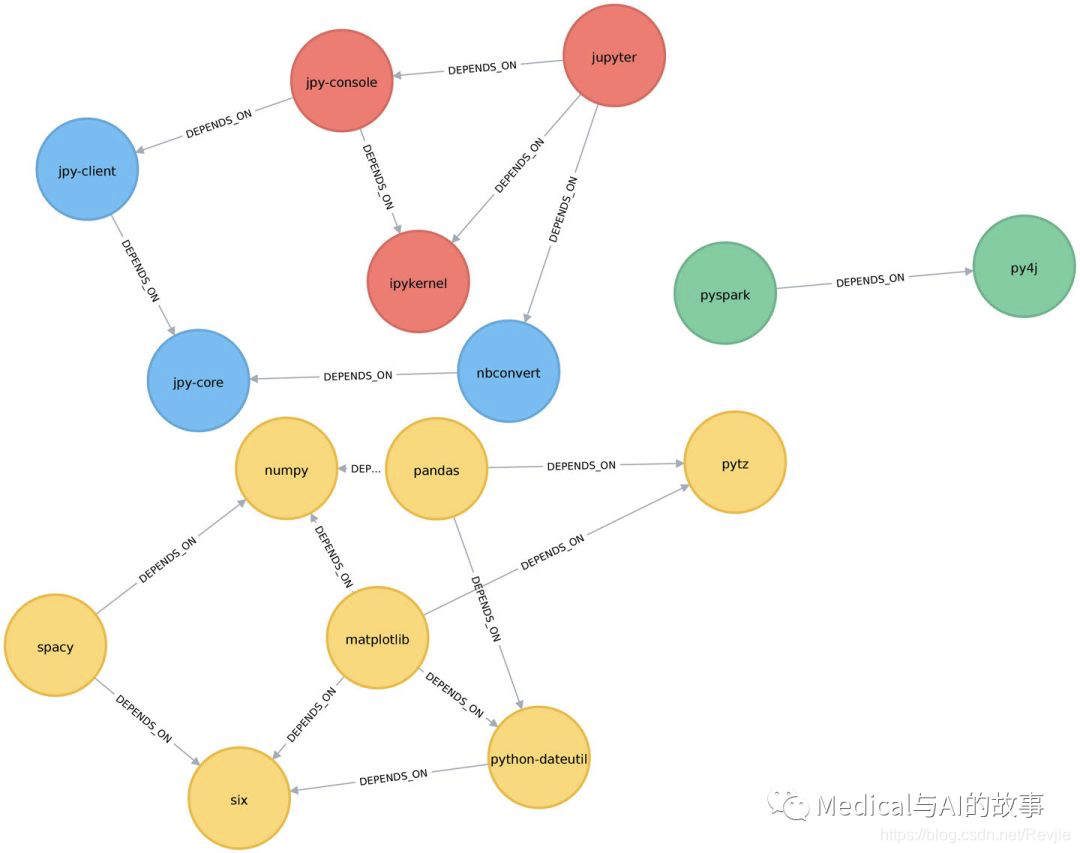 图6-10。忽略关系方向时,标签传播算法找到的聚类
虽然在这些数据上运行标签传播的结果对于无向和有向计算是相似的,但是在复杂的图上,您会看到更显著的差异。这是因为忽略方向会导致节点尝试采用更多的标签,而不考虑关系的方向。
图6-10。忽略关系方向时,标签传播算法找到的聚类
虽然在这些数据上运行标签传播的结果对于无向和有向计算是相似的,但是在复杂的图上,您会看到更显著的差异。这是因为忽略方向会导致节点尝试采用更多的标签,而不考虑关系的方向。