
@TOC Here’s the table of contents:
基于图数据的研报关键词聚合分析
自然语言处理技术是在挖掘文本数据时使用的关键技术之一,基于本体的挖掘词关联对近义词同义词分析是有帮助的。词关联在语音处理标记、解析、实体提取等自然语言处理任务中非常有用。常见的词关联主要有聚合关系和组合关系,本次测试中主要针对的是聚合关系的词关联分析,数据源为研报数据。通过词聚合分析可以生成词语之间的相关性图谱网络,在语料库中就可以方便的得到与某个词强烈相关的词列表。这种分析对于搜索系统、推荐系统是有借签意义的。
一、算法介绍
聚合关系的分析使用词语上下文窗口和Jaccard(杰卡德)算法进行计算。例如计算word1和word2的聚合相关性,则使用Jaccard分别计算两个词的上文相似度和下文相似度,然后求和即可。百科Jaccard系数介绍
二、数据模型
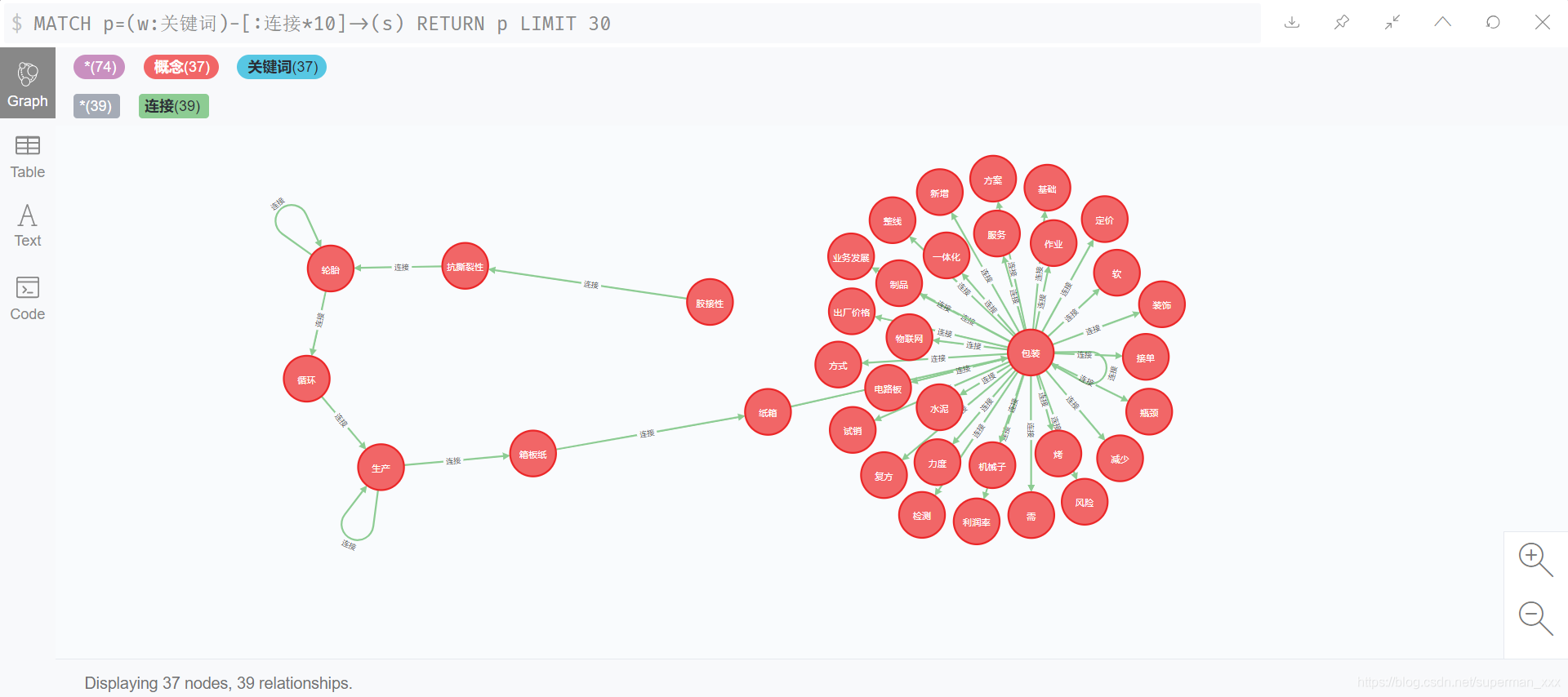
数据模型schema如下所示:(关键词)-[链接]->(关键词)
关键词数据在生成时需要进行分词,并去掉停止词等对业务做分析效果提升不明显的词,可以通过自定义词典的方式实现该目的。生成的
关键词上下文连接网络如图所示。
三、计算关键词上下文聚合相似性
使用CYPHER实现聚合相关性分析算法,支持迭代计算所有关键词之间的聚合相关性,并将最终结果写回图数据库。
MATCH (s:关键词)
// 首先得到s的left和right
// left
MATCH (w:关键词)-[:连接]->(s)
WITH COLLECT(DISTINCT w.name) AS left,s
// right
MATCH (w:关键词)<-[:连接]-(s)
WITH left,s,COLLECT(DISTINCT w.name) AS right
// 匹配除了s的其它单词
MATCH (o:关键词) WHERE NOT s=o
WITH left,right,s,o
// 得到o的left和right
// left
MATCH (w:关键词)-[:连接]->(o)
WITH COLLECT(DISTINCT w.name) AS left_o,left,right,s,o
// right
MATCH (w:关键词)<-[:连接]-(o)
WITH left_o,COLLECT(DISTINCT w.name) AS right_o,left,right,s,o
// 计算left的并集和交集
WITH [x IN left WHERE x IN left_o] AS l_intersect,(left+left_o) AS l_union,right_o,right,s,o
// 计算right的并集和交集
WITH [x IN right WHERE x IN right_o] AS r_intersect,(right+right_o) AS r_union,l_intersect,l_union,s,o
WITH DISTINCT l_intersect,r_intersect,l_union,r_union,s,o
// 计算杰卡德【Jaccard相似系数】
WITH s,o,
// left-Jaccard相似系数
1.0*SIZE(l_intersect)/SIZE(l_union) AS l_jaccard,
// right-Jaccard相似系数
1.0*SIZE(r_intersect)/SIZE(r_union) AS r_jaccard
// 聚合相似性:要计算单词的`left`和`right`集合的系数Jaccard平均值
WITH s,o,l_jaccard,r_jaccard,(l_jaccard+r_jaccard)/2 AS aggSim
CREATE UNIQUE (s)-[r:AggSim]->(o) SET r.parading=aggSim;
//RETURN s,o,l_jaccard,r_jaccard,aggSim
//LIMIT 1
四、关键词上下文聚合性能测试
图数据库服务:单节点图数据库分配的堆内存4G、页面缓存8G;服务器配置:AWS服务器CPU-8核8线程,硬盘-2T机械硬盘;数据规模:关键词图谱节点15万,关系295万。主要测试获取一个关键词上文关键词集合性能,得到的结论是在CYPHER中数据使用WITH传递ID效率会更高,比完整传送节点数据的CYPHER性能提升了3倍左右。
MATCH (s:关键词)
// 首先得到s的left和right
// left
MATCH (w:关键词)-[:连接]->(s)
WITH COLLECT(DISTINCT ID(w)) AS left,ID(s) AS s
RETURN left,s LIMIT 1
// Started streaming 1 records after 3671 ms and completed after 3672 ms.
// Started streaming 1 records after 3731 ms and completed after 3731 ms.
// Started streaming 1 records after 3691 ms and completed after 3691 ms.
MATCH (s:关键词)
// 首先得到s的left和right
// left
MATCH (w:关键词)-[:连接]->(s)
WITH COLLECT(DISTINCT ID(w)) AS left,s
RETURN left,s LIMIT 1
// Started streaming 1 records after 5665 ms and completed after 5665 ms.
// Started streaming 1 records after 5013 ms and completed after 5013 ms.
// Started streaming 1 records after 5048 ms and completed after 5048 ms.
MATCH (s:关键词)
// 首先得到s的left和right
// left
MATCH (w:关键词)-[:连接]->(s)
WITH COLLECT(DISTINCT w.name) AS left,s
RETURN left,s LIMIT 1
// Started streaming 1 records after 9308 ms and completed after 9308 ms.
// Started streaming 1 records after 8312 ms and completed after 8312 ms.
// Started streaming 1 records after 8568 ms and completed after 8568 ms.
五、计算聚合相似性【CYPHER优化】
在这个优化脚本中,主要实现了向下传送的数据修改为节点ID,性能比第
三节中脚本提升了3倍左右。
MATCH (s:关键词)
// 首先得到s的left和right
// left
MATCH (w:关键词)-[:连接]->(s)
WITH COLLECT(DISTINCT ID(w)) AS left,ID(s) AS sId
// right
MATCH (w:关键词)<-[:连接]-(s:关键词) WHERE ID(s)=sId
WITH left,sId,COLLECT(DISTINCT ID(w)) AS right
// 匹配除了s的其它单词
MATCH (o:关键词) WHERE NOT ID(o)=sId
WITH left,right,sId,ID(o) AS oId
// 得到o的left和right
// left
MATCH (w:关键词)-[:连接]->(o) WHERE ID(o)=oId
WITH COLLECT(DISTINCT ID(w)) AS left_o,left,right,sId,oId
// right
MATCH (w:关键词)<-[:连接]-(o) WHERE ID(o)=oId
WITH left_o,COLLECT(DISTINCT ID(w)) AS right_o,left,right,sId,oId
// 计算left的并集和交集
WITH [x IN left WHERE x IN left_o] AS l_intersect,(left+left_o) AS l_union,right_o,right,sId,oId
// 计算right的并集和交集
WITH [x IN right WHERE x IN right_o] AS r_intersect,(right+right_o) AS r_union,l_intersect,l_union,sId,oId
WITH DISTINCT l_intersect,r_intersect,l_union,r_union,sId,oId
// 计算杰卡德【Jaccard相似系数】
WITH sId,oId,
// left-Jaccard相似系数
1.0*SIZE(l_intersect)/SIZE(l_union) AS l_jaccard,
// right-Jaccard相似系数
1.0*SIZE(r_intersect)/SIZE(r_union) AS r_jaccard
// 聚合相似性:要计算单词的`left`和`right`集合的系数Jaccard平均值
WITH sId,oId,l_jaccard,r_jaccard,(l_jaccard+r_jaccard)/2 AS aggSim
//CREATE UNIQUE (s)-[r:AggSim]->(o) SET r.parading=aggSim;
RETURN sId,oId,l_jaccard,r_jaccard,aggSim
LIMIT 1
六、词对计算聚合相似性
这个脚本在第
五节基础上修改为两个词的聚合相似性分析。
MATCH (s:关键词) WHERE s.name IN ['商业','工业']
// 首先得到s的left和right
// left
MATCH (w:关键词)-[:连接]->(s)
WITH COLLECT(DISTINCT ID(w)) AS left,ID(s) AS sId
// right
MATCH (w:关键词)<-[:连接]-(s:关键词) WHERE ID(s)=sId
WITH left,sId,COLLECT(DISTINCT ID(w)) AS right
// 匹配除了s的其它单词
MATCH (o:关键词) WHERE NOT ID(o)=sId AND o.name IN ['商业','工业']
WITH left,right,sId,ID(o) AS oId
// 得到o的left和right
// left
MATCH (w:关键词)-[:连接]->(o) WHERE ID(o)=oId
WITH COLLECT(DISTINCT ID(w)) AS left_o,left,right,sId,oId
// right
MATCH (w:关键词)<-[:连接]-(o) WHERE ID(o)=oId
WITH left_o,COLLECT(DISTINCT ID(w)) AS right_o,left,right,sId,oId
// 计算left的并集和交集
WITH [x IN left WHERE x IN left_o] AS l_intersect,(left+left_o) AS l_union,right_o,right,sId,oId
// 计算right的并集和交集
WITH [x IN right WHERE x IN right_o] AS r_intersect,(right+right_o) AS r_union,l_intersect,l_union,sId,oId
WITH DISTINCT l_intersect,r_intersect,l_union,r_union,sId,oId
// 计算杰卡德【Jaccard相似系数】
WITH sId,oId,
// left-Jaccard相似系数
1.0*SIZE(l_intersect)/SIZE(l_union) AS l_jaccard,
// right-Jaccard相似系数
1.0*SIZE(r_intersect)/SIZE(r_union) AS r_jaccard
// 聚合相似性:要计算单词的`left`和`right`集合的系数Jaccard平均值
//WHERE l_jaccard>0 OR r_jaccard>0
WITH sId,oId,l_jaccard,r_jaccard,(l_jaccard+r_jaccard)/2 AS aggSim
//CREATE UNIQUE (s)-[r:AggSim]->(o) SET r.parading=aggSim;
RETURN sId,oId,l_jaccard,r_jaccard,aggSim
七、并发计算聚合相似性【CYPHER优化二】
// 缺省情况下,最大分区数/并行数为CPU内核数 x 100;
// 最多批次数为10000。例如,如果Neo4j数据库被分配了4个内核,
// 那么并行的最多进程数为400。
CALL apoc.cypher.parallel(
fragment,
params,
parallelizeOn
) YIELD value
// 1个词对
// Started streaming 2 records in less than 1 ms and completed after 499 ms.
// Started streaming 2 records in less than 1 ms and completed after 498 ms.
// Started streaming 2 records after 1 ms and completed after 500 ms.
CALL apoc.cypher.parallel(
'MATCH (s:关键词) WHERE s.name IN $name MATCH (w:关键词)-[:连接]->(s) WITH COLLECT(DISTINCT ID(w)) AS left,ID(s) AS sId MATCH (w:关键词)<-[:连接]-(s:关键词) WHERE ID(s)=sId WITH left,sId,COLLECT(DISTINCT ID(w)) AS right MATCH (o:关键词) WHERE NOT ID(o)=sId AND o.name IN $name WITH left,right,sId,ID(o) AS oId MATCH (w:关键词)-[:连接]->(o) WHERE ID(o)=oId WITH COLLECT(DISTINCT ID(w)) AS left_o,left,right,sId,oId MATCH (w:关键词)<-[:连接]-(o) WHERE ID(o)=oId WITH left_o,COLLECT(DISTINCT ID(w)) AS right_o,left,right,sId,oId WITH [x IN left WHERE x IN left_o] AS l_intersect,(left+left_o) AS l_union,right_o,right,sId,oId WITH [x IN right WHERE x IN right_o] AS r_intersect,(right+right_o) AS r_union,l_intersect,l_union,sId,oId WITH DISTINCT l_intersect,r_intersect,l_union,r_union,sId,oId WITH sId,oId, 1.0*SIZE(l_intersect)/SIZE(l_union) AS l_jaccard, 1.0*SIZE(r_intersect)/SIZE(r_union) AS r_jaccard WITH sId,oId,l_jaccard,r_jaccard,(l_jaccard+r_jaccard)/2 AS aggSim RETURN sId,oId,l_jaccard,r_jaccard,aggSim',
{name:[['工业','商业']]},
'name'
)
// 该查询生成了一个包含一百个词的词列表
MATCH (s:关键词),(o:关键词) WITH s.name AS s,o.name AS o limit 100
WITH [s,o] AS list
return COLLECT(list)
// 100个词对
// Started streaming 200 records after 2 ms and completed after 47239 ms.
// Started streaming 200 records after 1 ms and completed after 48107 ms.
// Started streaming 200 records in less than 1 ms and completed after 48266 ms.
CALL apoc.cypher.parallel(
'MATCH (s:关键词) WHERE s.name IN $name MATCH (w:关键词)-[:连接]->(s) WITH COLLECT(DISTINCT ID(w)) AS left,ID(s) AS sId MATCH (w:关键词)<-[:连接]-(s:关键词) WHERE ID(s)=sId WITH left,sId,COLLECT(DISTINCT ID(w)) AS right MATCH (o:关键词) WHERE NOT ID(o)=sId AND o.name IN $name WITH left,right,sId,ID(o) AS oId MATCH (w:关键词)-[:连接]->(o) WHERE ID(o)=oId WITH COLLECT(DISTINCT ID(w)) AS left_o,left,right,sId,oId MATCH (w:关键词)<-[:连接]-(o) WHERE ID(o)=oId WITH left_o,COLLECT(DISTINCT ID(w)) AS right_o,left,right,sId,oId WITH [x IN left WHERE x IN left_o] AS l_intersect,(left+left_o) AS l_union,right_o,right,sId,oId WITH [x IN right WHERE x IN right_o] AS r_intersect,(right+right_o) AS r_union,l_intersect,l_union,sId,oId WITH DISTINCT l_intersect,r_intersect,l_union,r_union,sId,oId WITH sId,oId, 1.0*SIZE(l_intersect)/SIZE(l_union) AS l_jaccard, 1.0*SIZE(r_intersect)/SIZE(r_union) AS r_jaccard WITH sId,oId,l_jaccard,r_jaccard,(l_jaccard+r_jaccard)/2 AS aggSim RETURN sId,oId,l_jaccard,r_jaccard,aggSim',
{name:[['工业','商业'],['胶接性','抗撕裂性'],['胶接性','供略'],['胶接性','较估值'],['胶接性','南通新有斐大酒店'],['胶接性','徐长江'],['胶接性','东文峰'],['胶接性','单晶营'],['胶接性','嘉宝集团'],['胶接性','嘉宝'],['胶接性','菊园'],['胶接性','盛创'],['胶接性','风范房'],['胶接性','格林风范'],['胶接性','港湾城'],['胶接性','限成'],['胶接性','科技园期'],['胶接性','上海安亭老庙黄金'],['胶接性','上海高泰稀贵金属股份'],['胶接性','高泰'],['胶接性','中国核工业集团'],['胶接性','锆管'],['胶接性','生产核反应堆'],['胶接性','形材'],['胶接性','29X-31X'],['胶接性','油罐'],['胶接性','上海市浦东新区土地资源储备中心'],['胶接性','安那州'],['胶接性','类磁性'],['胶接性','平海'],['胶接性','网电量'],['胶接性','551'],['胶接性','控本'],['胶接性','营建许'],['胶接性','清养'],['胶接性','订奶'],['胶接性','订奶量'],['胶接性','新皇'],['胶接性','乳业店'],['胶接性','得分'],['胶接性','思尔产能增'],['胶接性','打制'],['胶接性','摊销期权'],['胶接性','来定'],['胶接性','国有资产管理'],['胶接性','包袱-'],['胶接性','惠州市德赛聚能电池'],['胶接性','上海市经信委'],['胶接性','看聚'],['胶接性','瓷土'],['胶接性','长园科技实业'],['胶接性','保护板'],['胶接性','德赛'],['胶接性','达高点'],['胶接性','供略大于求'],['胶接性','净增加额'],['胶接性','华钟'],['胶接性','万买楼'],['胶接性','洗牌年'],['胶接性','宜通'],['胶接性','季三费率'],['胶接性','川南子'],['胶接性','评价中心'],['胶接性','美德'],['胶接性','增注'],['胶接性','哈默斯利'],['胶接性','柬埔寨柏威夏区'],['胶接性','西澳州'],['胶接性','上能'],['胶接性','青岛天信'],['胶接性','康能'],['胶接性','豪杰'],['胶接性','协鑫占'],['胶接性','覆丝机'],['胶接性','纺纱机'],['胶接性','墙胶'],['胶接性','门窗胶'],['胶接性','工业胶'],['胶接性','受益于'],['胶接性','厦门三虹'],['胶接性','江西巨通实业'],['胶接性','合金粉'],['胶接性','钴酸理'],['胶接性','根据证'],['胶接性','快钱'],['胶接性','MNC'],['胶接性','灵通网'],['胶接性','华友世纪'],['胶接性','恶劣化'],['胶接性','北纬公司'],['胶接性','信流量'],['胶接性','彻'],['胶接性','介〕'],['胶接性','由来'],['胶接性','内机'],['胶接性','张裕冰'],['胶接性','质量酒'],['胶接性','白葡萄酒'],['胶接性','无一例外'],['胶接性','张裕卡斯']]},
'name'
)
八、词对计算CYPHER脚本生成为过程
8.1 进一步优化查询
在第
六节的基础上继续优化该查询,之前的查询在MATCH时会重复匹配关键词,在这里优化词对的生成方式,支持两个词的分析;暂时不支持指定上下文深度,默认一度。
MATCH (s:关键词 {name:'商业'}) MATCH (o:关键词 {name:'工业'})
WITH ID(s) AS sId,ID(o) AS oId
WITH sId,oId
WHERE sId<>oId
// 获取词
MATCH (s:关键词) WHERE ID(s)=sId
// 首先得到s的left和right
// left
MATCH (w:关键词)-[:连接]->(s)
WITH COLLECT(DISTINCT ID(w)) AS left,sId,oId
// right
MATCH (w:关键词)<-[:连接]-(s:关键词) WHERE ID(s)=sId
WITH left,COLLECT(DISTINCT ID(w)) AS right,sId,oId
// 匹配除了s的其它单词
MATCH (o:关键词) WHERE ID(o)=oId
WITH left,right,sId,oId
// 得到o的left和right
// left
MATCH (w:关键词)-[:连接]->(o) WHERE ID(o)=oId
WITH COLLECT(DISTINCT ID(w)) AS left_o,left,right,sId,oId
// right
MATCH (w:关键词)<-[:连接]-(o) WHERE ID(o)=oId
WITH left_o,COLLECT(DISTINCT ID(w)) AS right_o,left,right,sId,oId
// 计算left的并集和交集
WITH [x IN left WHERE x IN left_o] AS l_intersect,(left+left_o) AS l_union,right_o,right,sId,oId
// 计算right的并集和交集
WITH [x IN right WHERE x IN right_o] AS r_intersect,(right+right_o) AS r_union,l_intersect,l_union,sId,oId
WITH DISTINCT l_intersect,r_intersect,l_union,r_union,sId,oId
// 计算杰卡德【Jaccard相似系数】
WITH sId,oId,
// left-Jaccard相似系数
1.0*SIZE(l_intersect)/SIZE(l_union) AS l_jaccard,
// right-Jaccard相似系数
1.0*SIZE(r_intersect)/SIZE(r_union) AS r_jaccard
// 聚合相似性:要计算单词的`left`和`right`集合的系数Jaccard平均值
WITH sId,oId,l_jaccard,r_jaccard,(l_jaccard+r_jaccard)/2 AS aggSim
//CREATE UNIQUE (s)-[r:AggSim]->(o) SET r.parading=aggSim;
RETURN sId,oId,l_jaccard,r_jaccard,aggSim
8.2 将查询安装为过程
将一个复杂的查询包装为过程或函数,可以方便数据分析师的调用。
8.2.1 上下文Jaccard系数相加
CALL apoc.custom.asProcedure(
'jaccard.agg.lr.sum',
'MATCH (s:关键词 {name:$first}) MATCH (o:关键词 {name:$second}) WITH ID(s) AS sId,ID(o) AS oId WITH sId,oId WHERE sId<>oId MATCH (s:关键词) WHERE ID(s)=sId MATCH (w:关键词)-[:连接]->(s) WITH COLLECT(DISTINCT ID(w)) AS left,sId,oId MATCH (w:关键词)<-[:连接]-(s:关键词) WHERE ID(s)=sId WITH left,COLLECT(DISTINCT ID(w)) AS right,sId,oId MATCH (o:关键词) WHERE ID(o)=oId WITH left,right,sId,oId MATCH (w:关键词)-[:连接]->(o) WHERE ID(o)=oId WITH COLLECT(DISTINCT ID(w)) AS left_o,left,right,sId,oId MATCH (w:关键词)<-[:连接]-(o) WHERE ID(o)=oId WITH left_o,COLLECT(DISTINCT ID(w)) AS right_o,left,right,sId,oId WITH [x IN left WHERE x IN left_o] AS l_intersect,(left+left_o) AS l_union,right_o,right,sId,oId WITH [x IN right WHERE x IN right_o] AS r_intersect,(right+right_o) AS r_union,l_intersect,l_union,sId,oId WITH DISTINCT l_intersect,r_intersect,l_union,r_union,sId,oId WITH sId,oId, 1.0*SIZE(l_intersect)/SIZE(l_union) AS l_jaccard, 1.0*SIZE(r_intersect)/SIZE(r_union) AS r_jaccard WITH sId,oId,l_jaccard,r_jaccard,(l_jaccard+r_jaccard) AS aggSim RETURN sId,oId,l_jaccard,r_jaccard,aggSim',
'READ',
[['sId','LONG'],['oId','LONG'],['l_jaccard','DOUBLE'],['r_jaccard','DOUBLE'],['aggSim','DOUBLE']],
[['first','STRING'],['second','STRING']],
'分析两个词对的聚合相似性:上下文杰卡德相似性相加'
);
// CALL custom.jaccard.agg.lr.sum('商业','工业')
8.2.1 上下文Jaccard系数求平均
CALL apoc.custom.asProcedure(
'jaccard.agg.lr.avr',
'MATCH (s:关键词 {name:$first}) MATCH (o:关键词 {name:$second}) WITH ID(s) AS sId,ID(o) AS oId WITH sId,oId WHERE sId<>oId MATCH (s:关键词) WHERE ID(s)=sId MATCH (w:关键词)-[:连接]->(s) WITH COLLECT(DISTINCT ID(w)) AS left,sId,oId MATCH (w:关键词)<-[:连接]-(s:关键词) WHERE ID(s)=sId WITH left,COLLECT(DISTINCT ID(w)) AS right,sId,oId MATCH (o:关键词) WHERE ID(o)=oId WITH left,right,sId,oId MATCH (w:关键词)-[:连接]->(o) WHERE ID(o)=oId WITH COLLECT(DISTINCT ID(w)) AS left_o,left,right,sId,oId MATCH (w:关键词)<-[:连接]-(o) WHERE ID(o)=oId WITH left_o,COLLECT(DISTINCT ID(w)) AS right_o,left,right,sId,oId WITH [x IN left WHERE x IN left_o] AS l_intersect,(left+left_o) AS l_union,right_o,right,sId,oId WITH [x IN right WHERE x IN right_o] AS r_intersect,(right+right_o) AS r_union,l_intersect,l_union,sId,oId WITH DISTINCT l_intersect,r_intersect,l_union,r_union,sId,oId WITH sId,oId, 1.0*SIZE(l_intersect)/SIZE(l_union) AS l_jaccard, 1.0*SIZE(r_intersect)/SIZE(r_union) AS r_jaccard WITH sId,oId,l_jaccard,r_jaccard,(l_jaccard+r_jaccard)/2 AS aggSim RETURN sId,oId,l_jaccard,r_jaccard,aggSim',
'READ',
[['sId','LONG'],['oId','LONG'],['l_jaccard','DOUBLE'],['r_jaccard','DOUBLE'],['aggSim','DOUBLE']],
[['first','STRING'],['second','STRING']],
'分析两个词对的聚合相似性:上下文杰卡德相似性相加'
);
// CALL custom.jaccard.agg.lr.avr('商业','工业')
8.2.2 过程使用以及返回值说明
// sId:第一个关键词
// oId:第二个关键词
// l_jaccard:上文相似度
// r_jaccard:下文相似度
// aggSim:聚合相似度
CALL custom.jaccard.agg.lr.avr('商业','工业') YIELD sId,oId,l_jaccard,r_jaccard,aggSim RETURN sId,oId,l_jaccard,r_jaccard,aggSim
CALL custom.jaccard.agg.lr.sum('商业','工业') YIELD sId,oId,l_jaccard,r_jaccard,aggSim RETURN sId,oId,l_jaccard,r_jaccard,aggSim
九、分析研报关键词列表的聚合相关性
9.1 词列表分析
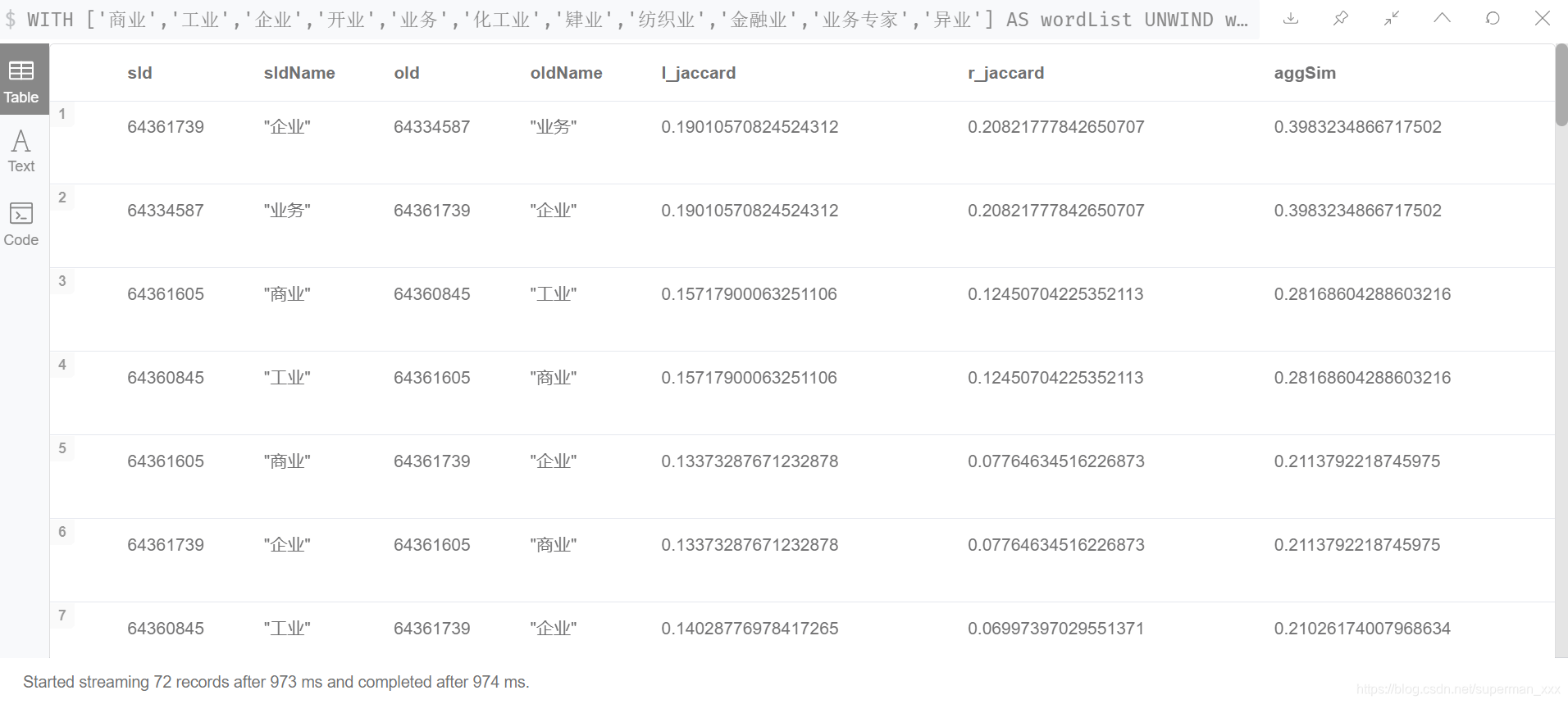
WITH ['商业','工业','企业','开业','业务','化工业','肄业','纺织业','金融业','业务专家','异业'] AS wordList
UNWIND wordList AS first
UNWIND wordList AS second
WITH first,second
WHERE first<>second
CALL custom.jaccard.agg.lr.sum(first,second) YIELD sId,oId,l_jaccard,r_jaccard,aggSim RETURN sId,algo.asNode(sId).name AS sIdName,oId,algo.asNode(oId).name AS oIdName,l_jaccard,r_jaccard,aggSim ORDER BY aggSim DESC
9.2 词列表分析优化
从上一小节的分析结果可以看到,词对的计算结果有重复。避免在CYPHER中重复计算可以极大提升查询的性能指标【QPS】。N个不重复关键词的词对聚合相关性分析计算结果应该为C(n,m)条,
因此优化上一节中的查询如下,其中对关键词进行编号是为了方便实现上述的组合公式。
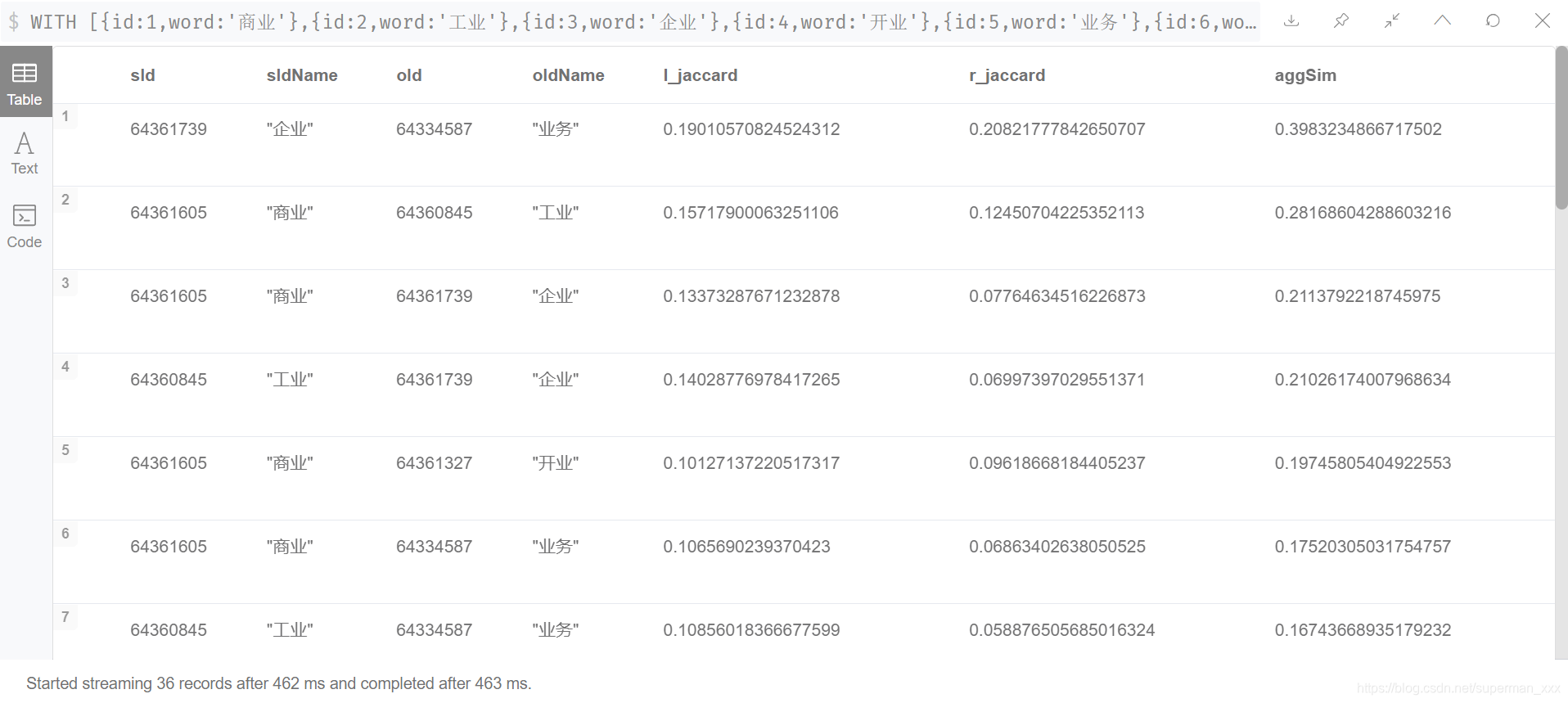
WITH [{id:1,word:'商业'},{id:2,word:'工业'},{id:3,word:'企业'},{id:4,word:'开业'},{id:5,word:'业务'},{id:6,word:'化工业'},{id:7,word:'肄业'},{id:8,word:'纺织业'},{id:9,word:'金融业'},{id:10,word:'业务专家'},{id:11,word:'异业'}] AS wordList
UNWIND wordList AS first
UNWIND wordList AS second
WITH first,second
WHERE first.id<second.id
WITH first.word AS first,second.word AS second
MATCH (o:关键词),(s:关键词) WHERE o.name=first AND s.name=second
CALL custom.jaccard.agg.lr.sum(first,second) YIELD sId,oId,l_jaccard,r_jaccard,aggSim RETURN sId,algo.asNode(sId).name AS sIdName,oId,algo.asNode(oId).name AS oIdName,l_jaccard,r_jaccard,aggSim ORDER BY aggSim DESC
十、技术交流
微信公众号:马超的博客