
@TOC Here’s the table of contents:
股权网络92毫秒穿透一百层测试后续
【图数据】股权网络穿透一千层需要多久?上一篇测试结果出来之后,基于开源的Neo4j搭建的图数据库集群性能得到验证。有朋友对其它测试细节比较感兴趣,关于其它的性能指标分析在这里做一下总结。另外Neo4j图数据库的连通图分析与并发计算性能测试也在本文中。
一、关于业务价值
上一篇的测试结果出来以后,看到社区有人提问,股权网络穿透一百层的意义是什么?业务价值是什么?这个问题回答我截图记录了一下,不同的场景不同的需求,仅仅代表个人观点,仅供参考。
Neo4j研发团队目前发力的重点是人工智能领域,相关生态发展的也更快,说明了类似的图数据库架构在人工智能模型训练上的优势是的确存在的。人工智能模型的最关键指标是准和快,数据系统和计算系统是支持模型训练的两个关键基础设施,其性能是非常重要的。感兴趣的话可以去Neo4j官网查看一下关于未来的发展规划的介绍,挺有意思的!:)
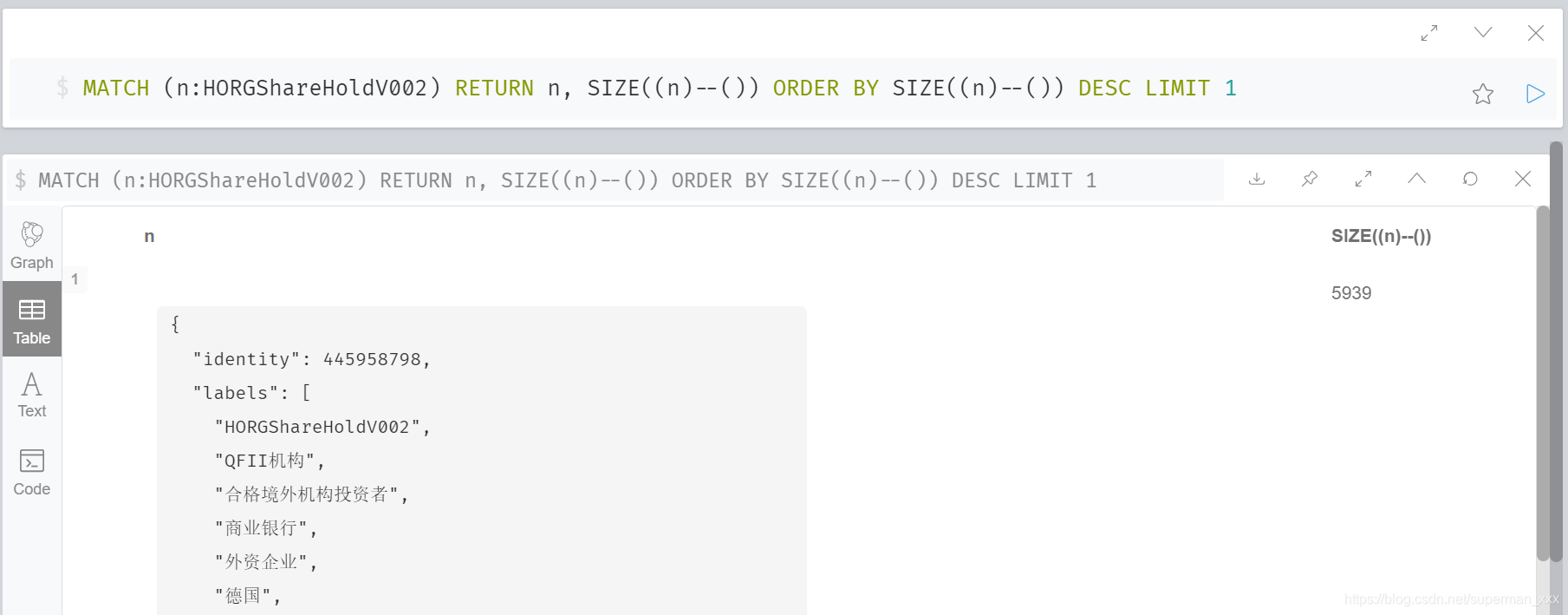
二、超级节点的规模
关于超级节点的规模,在本次测试的股权网络中为5939。如有规模更大的超级节点,也可以优化数据模型来实现,可以参考下面的文章。 针对图谱超级节点的一种优化解决方案
- 查询语句
MATCH (n:HORGShareHoldV002) RETURN n, SIZE((n)--()) ORDER BY SIZE((n)--()) DESC LIMIT 1
- 结果
三、一百层穿透其它性能指标
3.1 数据规模
【图数据】股权网络穿透一千层需要多久?这篇文章有数据规模的统计数据,在此不再赘述。
3.2 测试结果
从测试结果可以看到,返回路径全部数据会对性能有一定影响;一百层路径加SKIP参数为一千万的时候查询时间基本都是分钟级,SKIP参数为一百万的时候查询时间大概在10秒左右。
3.3 相关查询
- 使用HTTP接口查询方式
四、超千万的联通图内穿透测试
在本次测试中,使用了弱连通图【WCC】进行分析。本节中查询测试都是在此最大弱联通图分析的结果之上进行性能测试。并一同测试了Neo4j的并发计算的性能。基础数据规模、Neo4j集群部署方式以及服务器性能在上一篇文章中已有说明。【图数据】股权网络穿透一千层需要多久?
4.1 数据规模
最大弱连通图规模,节点与关系数均超过1198万。
4.2 弱连通图分析方法
CALL algo.unionFind.stream(label:String, relationship:String, {weightProperty:'propertyName', threshold:0.42, defaultValue:1.0,concurrency:4)
YIELD nodeId, setId - yields a setId to each node id
4.2.1 最小团分析
CALL algo.unionFind.stream('HORGShareHoldV002','持股',{concurrency:8}) YIELD nodeId,setId
WITH nodeId,algo.asNode(nodeId).name AS name,setId
WITH COLLECT(setId) AS setIdList
WITH apoc.coll.sortMaps(apoc.coll.frequencies(setIdList),'^count') AS sortMaps
WITH FILTER(map IN sortMaps WHERE map.count>1) AS reSortMaps
RETURN reSortMaps[0] AS minClique
// 运行结果:最小团包含1189万节点;耗时67478毫秒,67.478秒
{
"count": 2,
"item": 133559
}
4.2.2 最大团分析
CALL algo.unionFind.stream('HORGShareHoldV002','持股',{concurrency:8}) YIELD nodeId,setId
WITH nodeId,algo.asNode(nodeId).name AS name,setId
WITH COLLECT(setId) AS setIdList
WITH apoc.coll.sortMaps(apoc.coll.frequencies(setIdList),'count') AS sortMaps
RETURN sortMaps[0] AS maxClique
// 运行结果:最大团包含1189万节点;耗时228823毫秒,228.823秒
{
"count": 11891440,
"item": 14739839
}
4.2.3 从最大团找到一个节点供后续分析使用
CALL algo.unionFind.stream('HORGShareHoldV002','持股',{concurrency:8}) YIELD nodeId,setId
WITH nodeId,setId
WITH COLLECT(nodeId) AS nodeIdList,setId
WITH SIZE(nodeIdList) AS size,nodeIdList[0] AS oneId,setId
RETURN size,oneId,setId ORDER BY size DESC LIMIT 1
// 运行结果:耗时29682毫秒,29.682秒
╒════════╤═════════╤═══════╕
│"size" │"oneId" │"setId"│
╞════════╪═════════╪═══════╡
│11891440│396614326│6022290│
└────────┴─────────┴───────┘
4.2.4 并发分析最大团测试报告
关于并发参数的设置:并发数concurrency通常设置成分配给数据库服务运行的CPU内核数的整数倍。例如,图数据库服务运行在8个CPU内核的虚拟或物理主机上,那么concurrency可以是8、16、24等值。 从测试结果可以看到,根据目前的服务器资源四核八线程,设置为8线程时性能最佳,大于8线程性能并没有提升,因为服务器只能支持到8线程的并发。 该分析过程想要进一步提速,可以将数据导入到spark等
分布式计算系统进行计算,性能也许会更好。
4.3 测试结果
在本节分析的
最大团上执行数据穿透测试。穿透起点为国资委国务院国有资产监督管理委员会,向下穿透100层。可以看到SKIP参数设置为10万时,查询进入了秒级别;SKIP参数超过一千万时,查询接近一分钟;SKIP参数设置为一亿时,查询已经在17分钟左右。
4.4 相关查询
五、阅读原文
六、技术交流
微信公众号:马超的博客