
“Cypher”是一个描述性的图形查询语言,允许不必编写图形结构的遍历代码对图形存储有表现力和效率的查询。Cypher还在继续发展和成熟,这也就意味着有可能会出现语法的变化。同时也意味着作为组件没有经历严格的性能测试。
Cypher设计的目的是一个人类查询语言,适合于开发者和在数据库上做点对点模式(ad-hoc)查询的专业操作人员(我认为这个很重要)。它的构念是基于英语单词和灵巧的图解。
Cyper通过一系列不同的方法和建立于确定的实践为表达查询而激发的。许多关键字如like和order by是受SQL的启发。模式匹配的表达式来自于SPARQL。正则表达式匹配实现实用Scala programming language语言。
Cypher是一个申明式的语言。对比命令式语言如Java和脚本语言如Gremlin和JRuby,它的焦点在于从图中如何找回(what to retrieve),而不是怎么去做。这使得在不对用户公布的实现细节里关心的是怎么优化查询。
这个查询语言包含以下几个明显的部分:
- START:在图中的开始点,通过元素的ID或所以查找获得。
- MATCH:图形的匹配模式,束缚于开始点。
- WHERE:过滤条件。
- RETURN:返回所需要的。
在下例中看三个关键字
示例图片如下:
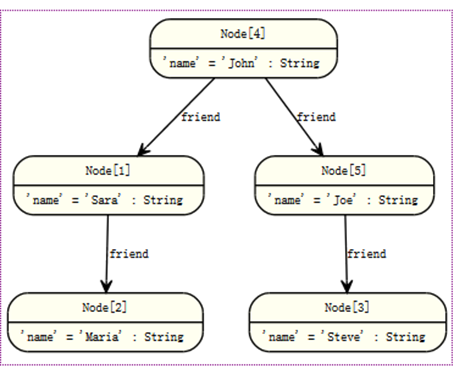
如:这个有个查询,通过遍历图找到索引里一个叫John的朋友的朋友(不是他的直接朋友),返回John和找到的朋友的朋友。
START john=node:node_auto_index(name = 'John')
MATCH john-[:friend]->()-[:friend]->fof
RETURN john, fof
返回结果:

下一步添加过滤:
在下一个例子中,列出一组用户的id并遍历图查找这些用户接出friend关系线,返回有属性name并且其值是以S开始的用户。
START user=node(5,4,1,2,3)
MATCH user-[:friend]->follower
WHERE follower.name =~ /S.*/
RETURN user, follower.name
返回结果:

操作符
Cypher中的操作符有三个不同种类:数学,相等和关系。
数学操作符有+,-,*,/和%。当然只有+对字符有作用。
等于操作符有=,<>,<,>,<=,>=。
因为Neo4j是一个模式少的图形数据库,Cypher有两个特殊的操作符?和!。
有些是用在属性上,有些事用于处理缺少值。对于一个不存在的属性做比较会导致错误。为替代与其他什么做比较时总是检查属性是否存在,在缺失属性时问号将使得比较总是返回true,感叹号使得比较总是返回false。
WHEREn.prop? = "foo"
这个断言在属性缺失情况下将评估为true。
WHEREn.prop! = "foo"
这个断言在属性缺失情况下将评估为false。
警告:在同一个比较中混合使用两个符号将导致不可预料的结果。
参数
Cypher支持带参数的查询。这允许开发者不需要必须构建一个string的查询,并且使得Cypher的查询计划的缓存更容易。
参数可以在where子句,start子句的索引key或索引值,索引查询中作为节点/关系id的引用。
以下是几个在java中使用参数的示例:
节点id参数
Map<String, Object> params = new HashMap<String, Object>();
params.put( "id", 0 );
ExecutionResult result = engine.execute( "start n=node({id}) return n.name", params );
节点对象参数
Map<String, Object> params = new HashMap<String, Object>();
params.put( "node", andreasNode );
ExecutionResult result = engine.execute( "start n=node({node}) return n.name", params );
多节点id参数
Map<String, Object> params = new HashMap<String, Object>();
params.put( "id", Arrays.asList( 0, 1, 2 ) );
ExecutionResult result = engine.execute( "start n=node({id}) return n.name", params );
字符串参数
Map<String, Object> params = new HashMap<String, Object>();
params.put( "name", "Johan" );
ExecutionResult result = engine.execute( "start n=node(0,1,2) where n.name = {name} return n", params );
索引键值参数
Map<String, Object> params = new HashMap<String, Object>();
params.put( "key", "name" );
params.put( "value", "Michaela" );
ExecutionResult result = engine.execute( "start n=node:people({key} = {value}) return n", params );
索引查询参数
Map<String, Object> params = new HashMap<String, Object>();
params.put( "query", "name:Andreas" );
ExecutionResult result = engine.execute( "start n=node:people({query}) return n", params );
- SKIP 与LIMIT * 的数字参数
Map<String, Object> params = new HashMap<String, Object>();
params.put( "s", 1 );
params.put( "l", 1 );
ExecutionResult result = engine.execute( "start n=node(0,1,2) return n.name skip {s} limit {l}", params );
- 正则表达式参数
Map<String, Object> params = new HashMap<String, Object>();
params.put( "regex", ".*h.*" );
ExecutionResult result = engine.execute( "start n=node(0,1,2) where n.name =~ {regex} return n.name", params );
标识符
当你参考部分的模式时,需要通过命名完成。定义的不同的命名部分就被称为标识符。
如下例中:
START n=node(1) MATCH n-->b RETURN b
标识符为n和b。
标识符可以是大写或小些,可以包含下划线。当需要其他字符时可以使用`符号。对于属性名的规则也是一样。
注解
可以在查询语句中使用双斜杠来添加注解。如:
START n=node(1) RETURN b //这是行结束注释
START n=node(1) RETURN b
START n=node(1) WHERE n.property = "//这部是一个注释" RETURN b
Start
每一个查询都是描述一个图案(模式),在这个图案(模式)中可以有多个限制点。一个限制点是为模式匹配的从开始点出发的一条关系或一个节点。可以通过id或索引查询绑定点。
通过id绑定点
通过node(*)函数绑定一个节点作为开始点
查询:
START n=node(1)
RETURN n
返回引用的节点。
结果:
通过id绑定关系
可以通过relationship()函数绑定一个关系作为开始点。也可以通过缩写rel()。
查询:
START r=relationship(0)
RETURN r
Id为0的关系将被返回
结果:
通过id绑定多个节点
选择多个节点可以通过逗号分开。
查询:
START n=node(1, 2, 3)
RETURN n
结果:

所有节点
得到所有节点可以通过星号(*),同样对于关系也适用。
查询:
START n=node(*)
RETURN n
这个查询将返回图中所有节点。
结果:

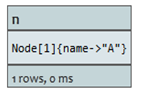
通过索引查询获取节点
如果开始节点可以通过索引查询得到,可以如此来写:
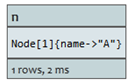
node:index-name(key=”value”)。在此列子中存在一个节点索引叫nodes。
查询:
START n=node:nodes(name = "A")
RETURN n
索引中命名为A的节点将被返回。
结果:
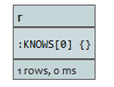
通过索引查询获取关系
如果开始点可以通过索引查询得到,可以如此做:
Relationship:index-name(key=”value”)。
查询:
START r=relationship:rels(property ="some_value")
RETURN r
索引中属性名为”some_value”的关系将被返回。
结果:

多个开始点
有时需要绑定多个开始点。只需要列出并以逗号分隔开。
查询:
START a=node(1), b=node(2)
RETURN a,b
A和B两个节点都将被返回。
结果:

Match
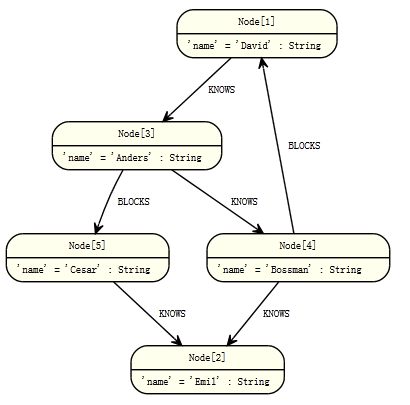
在一个查询的匹配(match)部分申明图形(模式)。模式的申明导致一个或多个以逗号隔开的路径(path)。
节点标识符可以使用或者不是用圆括号。使用圆括号与不使用圆括号完全对等,如:
MATCH(a)-->(b) 与 MATCH a-->b 匹配模式完全相同。
模式的所有部分都直接或者间接地绑定到开始点上。可选关系是一个可选描述模式的方法,但在真正图中可能没有匹配(节点可能没有或者没有此类关系时),将被估值为null。与SQL中的外联结类似,如果Cypher发现一个或者多个匹配,将会全部返回。如果没有匹配,Cypher将返回null。
如以下例子,b和p都是可选的病都可能包含null:
START a=node(1) MATCH p = a-[?]->b
START a=node(1) MATCH p = a-[*?]->b
START a=node(1) MATCH p = a-[?]->x-->b
START a=node(1), x=node(100) MATCH p = shortestPath( a-[*?]->x )
相关节点
符号—意味着相关性,不需要关心方向和类型。
查询:
START n=node(3)
MATCH (n)--(x)
RETURN x
所有与A相关节点都被返回。
结果:

接出关系(Outgong relationship)
当对关系的方向感兴趣时,可以使用-->或<--符号,如:
查询:
START n=node(3)
MATCH (n)-->(x)
RETURN x
所有A的接出关系到达的节点将被返回.
结果:

定向关系和标识符
如果需要关系的标识符,为了过滤关系的属性或为了返回关系,可如下例使用标识符。
查询:
START n=node(3)
MATCH (n)-[r]->()
RETURN r
所有从节点A接出的关系将被返回。
结果:

通过关系类型匹配
当已知关系类型并想通过关系类型匹配时,可以通过冒号详细描述。
查询:
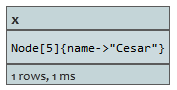
START n=node(3)
MATCH (n)-[:BLOCKS]->(x)
RETURN x
返回A接出关系类型为BLOCKS的节点。
结果:
通过关系类型匹配和使用标识符
如果既想获得关系又要通过已知的关系类型,那就都添加上,如:
查询:
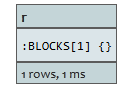
START n=node(3)
MATCH (n)-[r:BLOCKS]->()
RETURN r
所有从A接出的关系为BLOCKS的关系都被返回。
结果:
带有特殊字符的关系类型
有时候数据库中有非字母字符类型,或有空格在内时,使用单引号。
查询:
START n=node(3)
MATCH (n)-[r:`TYPE WITH SPACE IN IT`]->()
RETURN r
返回类型有空格的关系。
结果:

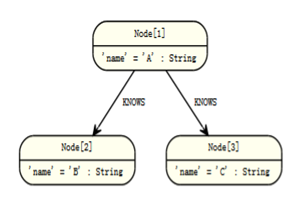
多重关系
关系可以通过使用在()—()多个语句来表达,或可以串在一起。如下:
查询:
START a=node(3)
MATCH (a)-[:KNOWS]->(b)-[:KNOWS]->(c)
RETURN a,b,c
路径中的三个节点。
结果:

可变长度的关系
可变数量的关系->节点可以使用-[:TYPE*minHops..maxHops]->。
查询:
START a=node(3), x=node(2, 4)
MATCH a-[:KNOWS*1..3]->x
RETURN a,x
如果在1到3的关系中存在路径,将返回开始点和结束点。
结果:

在可变长度关系的关系标识符
当连接两个节点的长度是可变的不确定的时,可以使用一个关系标识符遍历所有关系。
查询:
START a=node(3), x=node(2, 4)
MATCH a-[r:KNOWS*1..3]->x
RETURN r
如果在1到3的关系中存在路径,将返回开始点和结束点。
结果:

零长度路径
当使用可变长度路径,可能其路径长度为0,这也就是说两个标识符指向的为同一个节点。如果两点间的距离为0,可以确定这是同一个节点。
查询:
START a=node(3)
MATCH p1=a-[:KNOWS*0..1]->b, p2=b-[:BLOCKS*0..1]->c
RETURN a,b,c, length(p1), length(p2)
这个查询将返回四个路径,其中有些路径长度为0.
结果:

可选关系
如果关系为可选的,可以使用问号表示。与SQL的外连接类似。如果关系存在,将被返回。如果不存在在其位置将以null代替。
查询:
START a=node(2)
MATCH a-[?]->x
RETURN a,x
返回一个节点和一个null,因为这个节点没有关系。
结果:
可选类型和命名关系
通过一个正常的关系,可以决定哪个标识符可以进入,那些关系类型是需要的。
查询:
START a=node(3)
MATCH a-[r?:LOVES]->()
RETURN a,r
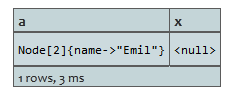
返回一个节点和一个null,因为这个节点没有关系。
结果:
可选元素的属性
返回可选元素上的属性,null值将返回null。
查询:
START a=node(2)
MATCH a-[?]->x
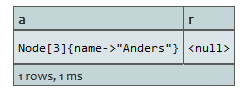
RETURN x, x.name
元素x在查询中为null,所有其属性name为null。
结果:

复杂匹配
在Cypher中,可哟通过更多复杂模式来匹配,像一个钻石形状模式。
查询:
START a=node(3)
MATCH (a)-[:KNOWS]->(b)-[:KNOWS]->(c),(a)-[:BLOCKS]-(d)-[:KNOWS]-(c)
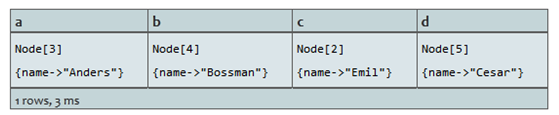
RETURN a,b,c,d
路径中的四个节点。
结果:
最短路径
使用shortestPath函数可以找出一条两个节点间的最短路径,如下。
查询:
START d=node(1), e=node(2)
MATCH p = shortestPath( d-[*..15]->e )
RETURN p
这意味着:找出两点间的一条最短路径,最大关系长度为15.圆括号内是一个简单的路径连接,开始节点,连接关系和结束节点。关系的字符描述像关系类型,最大数和方向在寻找最短路径中都将被用到。也可以标识路径为可选。
结果:

所有最但路径
找出两节点节点所有的最短路径。
查询:
START d=node(1), e=node(2)
MATCH p = allShortestPaths( d-[*..15]->e )
RETURN p
这将在节点d与e中找到两条有方向的路径。
结果:

命名路径
如果想在模式图上的路径进行过滤或者返回此路径,可以使用命名路径(named path)。
查询:
START a=node(3)
MATCH p = a-->b
RETURN p
开始节点的两个路径。
结果:

在绑定关系上的匹配
当模式中包含一个绑定关系时,此关系模式没有明确的方向,Cypher将尝试着切换连接节点的边匹配关系。
查询:
START a=node(3), b=node(2)
MATCH a-[?:KNOWS]-x-[?:KNOWS]-b
RETURN x
将返回两个连接节点,一次为开始节点,一次为结束节点。
结果:
