
教程目录 引自:https://neo4j.com/docs/getting-started/cypher-intro/procedures-functions/
如何扩展 Cypher
本指南介绍了如何创建、使用和部署用户定义的程序和函数,这是 Cypher®(Neo4j 的查询语言)的扩展机制。
扩展 Cypher
Cypher 是一种强大且富有表达力的语言,具有一流的图模式和集合支持。但有时您需要做更多的事情,如额外的图算法、并行化或自定义转换。
Cypher 可以通过用户定义的程序和函数进行扩展,详见 Java 参考 → 用户定义程序和 Java 参考 → 用户定义函数。
Neo4j 本身提供并使用自定义程序。Neo4j 浏览器公开的许多监控、自检和安全功能都是使用程序实现的。
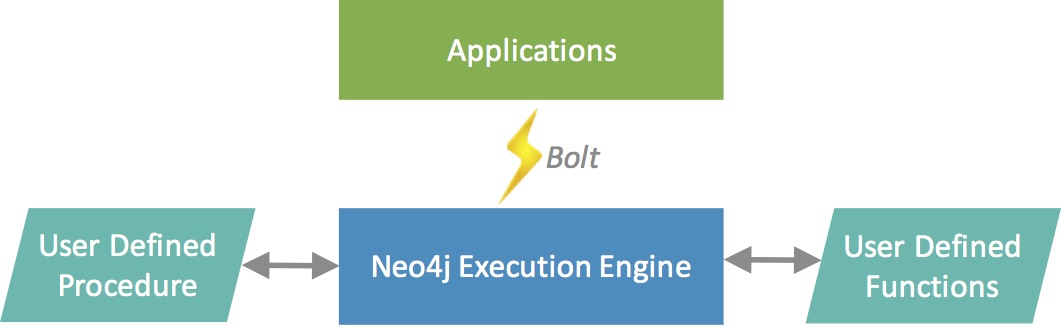
Neo4j 中的程序和函数
- 函数是简单的计算/转换,返回单个值
- 函数可以在任何表达式或谓词中使用
- 程序是更复杂的操作,生成结果流
- 程序可以生成、获取或计算数据,供 Cypher 查询的后续处理步骤使用
要调用数据库中部署的程序,请使用 CALL 子句(详见 Cypher 手册 → CALL 程序)。
列出和使用 Neo4j 的函数和程序
Neo4j 带有多个内置程序。要了解更多信息,请参阅操作手册 → 程序。
要列出 DBMS 中所有可用的函数和程序,使用以下 Cypher 命令:
SHOW FUNCTIONS
SHOW PROCEDURES
您可以参考 Cypher 速查表以快速了解如何使用这些命令。
每个程序返回一列或多列数据。通过 YIELD 子句,可以选择这些列并设置别名,然后在 Cypher 查询中使用。
像其他 Cypher 管理命令一样,SHOW PROCEDURES 可以与 Cypher 子句的子集一起使用,如下所示,我们按 ‘db.’ 前缀过滤并按名称排序返回结果:
SHOW PROCEDURES
YIELD name, signature, description as text
WHERE name STARTS WITH 'db.'
RETURN * ORDER BY name ASC
下面是另一个示例,展示如何按选定的类别(例如包)对可用程序进行分组:
SHOW PROCEDURES
YIELD name, signature, description
RETURN split(name,".")[0..-1] AS package, count(*) AS count,
collect(split(name,".")[-1]) AS names
ORDER BY count DESC
可用程序集取决于您的安装类型和配置设置。结果可能如下:
| package | count | names |
|---|---|---|
| [“dbms”] | 20 | [“checkConfigValue”, “components”, “info”,…] |
| [“db”] | 16 | [“awaitIndex”, “awaitIndexes”, “checkpoint”,…] |
| [“db”,“stats”] | 6 | [“clear”, “collect”, “retrieve”,…] |
| [“dbms”, “cluster”] | 6 | [“checkConnectivity”, “cordonServer”, “protocols”,…] |
| [“db”, “index”, “fulltext”] | 4 | [“awaitEventuallyConsistentIndexRefresh”, “listAvailableAnalyzers”,…] |
用户定义的函数用 Java 编写,部署到数据库中,其调用方式与其他 Cypher 函数相同。可以开发和使用两种主要类型的函数:
- 用户定义的标量函数
- 用户定义的聚合函数
详细信息请参见 Cypher 手册 → 用户定义函数。
您可以将任何程序库部署到自管理服务器,以使用其他程序和函数。
另请查看 Neo4j Java 参考中的程序部分。
部署程序和函数
如果您构建自己的程序或从社区项目下载程序,它们会打包在 JAR 文件中。您可以将该文件复制到 Neo4j 服务器的 $NEO4J_HOME/plugins 目录并重启。
由于程序和函数使用低级 Java API,它们可以访问所有 Neo4j 内部组件以及文件系统和机器。这就是为什么您应该了解部署哪些程序以及原因。只安装来自可信源的程序。如果它们是开源的,请检查其源代码,最好自己构建。
有关如何确保这些附加组件安全性的最佳实践,请参见操作手册 → 保护扩展。
某些程序和函数可用于自管理的 Neo4j 企业版和社区版。 本节中描述的自定义代码与 AuraDB 不兼容。 在 Neo4j AuraDB 中,可用的程序和函数仅限于内置程序和函数以及 APOC Core 库的子集。
程序和函数库
APOC Core 库为您提供了一组有用的 Cypher 程序,以增强数据集成、图算法和数据转换等领域的功能。
例如,用于格式化和解析不同分辨率时间戳的函数:
RETURN apoc.date.format(timestamp()) as time,
apoc.date.format(timestamp(),'ms','yyyy-MM-dd') as date,
apoc.date.parse('13.01.1975','s','dd.MM.yyyy') as unixtime,
apoc.date.parse('2017-01-05 13:03:07') as millis
| time | date | unixtime | millis |
|---|---|---|---|
| “2017-01-05 13:06:39” | “2017-01-05” | 158803200 | 1483621387000 |
在我们的 Neo4j Labs 项目中,您可以找到由社区和员工构建的库集。看看已有的内容,很多需求已经被覆盖,例如:
- 索引操作
- 数据库/API 集成
- 图重构
- 导入和导出
- 空间索引查找
- RDF 导入和导出
- 等等
社区和 Neo4j Labs 项目不受官方支持,我们不提供任何 SLA 或向后兼容性和弃用的保证。
开发自己的程序和函数
您可以在 Neo4j Java 参考中找到有关编写和测试程序的详细信息。
示例 GitHub 存储库包含详细的文档和注释,您可以直接克隆并用作起点。
以下是一些初步提示。
用户定义的函数比较简单,让我们从它们开始:
@UserFunction注解的公共 Java 类中的方法- 默认名称是包名.方法名
- 返回单个值
- 只读
用户定义的程序类似:
@Procedure注解的 Java 方法- 带有附加模式属性(READ, WRITE, DBMS)
- 返回具有公共字段的简单对象的 Java 8 流
- 这些字段名称转换为可用于 YIELD 的结果列
这些特性对两者都有效:
- 使用
@Name注解的参数(带可选默认值) - 可以使用注入的
@Context public GraphDatabaseService - 在 Cypher 语句的事务中运行
- 支持的参数和结果类型有:Long、Double、Boolean、String、Node、Relationship、Path、Object