
教程目录 引自:https://neo4j.com/docs/getting-started/cypher-intro/subqueries/
Cypher 中的子查询
回顾我们的示例图
我们所有的代码示例将继续使用我们之前使用过的其中一个图示例,但包括更多数据以用于此页面上的查询。下图是新图,一个由人员、他们工作的公司以及他们喜欢的技术组成的网络。
我们添加了一个 Person 节点(蓝色),该节点 WORKS_FOR 一个 Company 节点(红色)并且 LIKES 一个 Technology 节点(绿色):Ryan 为 Company Z 工作并且喜欢 Python。您可以在图的右侧找到此数据。
回顾一下,每个人也可能与其他人有多个 IS_FRIENDS_WITH 关系。

图 1. 人员、他们工作的公司以及他们喜欢的技术的网络
您可以使用以下 Cypher® 查询创建此数据集:
CREATE (diana:Person {name: "Diana"})-[:LIKES]->(query:Technology {type: "Query Languages"})
CREATE (melissa:Person {name: "Melissa", twitter: "@melissa"})-[:LIKES]->(query)
CREATE (dan:Person {name: "Dan", twitter: "@dan", yearsExperience: 6})-[:LIKES]->(etl:Technology {type: "Data ETL"})<-[:LIKES]-(melissa)
CREATE (xyz:Company {name: "XYZ"})<-[:WORKS_FOR]-(sally:Person {name: "Sally", yearsExperience: 4})-[:LIKES]->(integrations:Technology {type: "Integrations"})<-[:LIKES]-(dan)
CREATE (sally)<-[:IS_FRIENDS_WITH]-(john:Person {name: "John", yearsExperience: 5, birthdate: "1985-04-04"})-[:LIKES]->(java:Technology {type: "Java"})
CREATE (john)<-[:IS_FRIENDS_WITH]-(jennifer:Person {name: "Jennifer", twitter: "@jennifer", yearsExperience: 5, birthdate: "1988-01-01"})-[:LIKES]->(java)
CREATE (john)-[:WORKS_FOR]->(xyz)
CREATE (sally)<-[:IS_FRIENDS_WITH]-(jennifer)-[:IS_FRIENDS_WITH]->(melissa)
CREATE (joe:Person {name: "Joe", birthdate: "1988-08-08"})-[:LIKES]->(query)
CREATE (mark:Person {name: "Mark", twitter: "@mark"})
CREATE (ann:Person {name: "Ann"})
CREATE (x:Company {name: "Company X"})<-[:WORKS_FOR]-(diana)<-[:IS_FRIENDS_WITH]-(joe)-[:IS_FRIENDS_WITH]->(mark)-[:LIKES]->(graphs:Technology {type: "Graphs"})<-[:LIKES]-(jennifer)-[:WORKS_FOR]->(:Company {name: "Neo4j"})
CREATE (ann)<-[:IS_FRIENDS_WITH]-(jennifer)-[:IS_FRIENDS_WITH]->(mark)
CREATE (john)-[:LIKES]->(:Technology {type: "Application Development"})<-[:LIKES]-(ann)-[:IS_FRIENDS_WITH]->(dan)-[:WORKS_FOR]->(abc:Company {name: "ABC"})
CREATE (ann)-[:WORKS_FOR]->(abc)
CREATE (a:Company {name: "Company A"})<-[:WORKS_FOR]-(melissa)-[:LIKES]->(graphs)<-[:LIKES]-(diana)
CREATE (:Technology {type: "Python"})<-[:LIKES]-(:Person {name: "Ryan"})-[:WORKS_FOR]->(:Company {name: "Company Z"})
子查询简介
子查询是在 Neo4j 4.0 中引入的。
有关如何使用它们的详细信息,请转到 Cypher 手册 → 子查询。
以下类型的子查询在 Neo4j 中是可能的:
EXISTS子查询COUNT子查询CALL {…}子查询子句CALL {…} IN TRANSACTIONS子查询子句COLLECT子查询(在 5.6 中引入)
EXISTS、COUNT 和 CALL {…} 子查询在本节中介绍。
要了解有关使用 CALL {…} IN TRANSACTIONS 的更多信息,请参阅以下教程中的代码示例,了解如何将 CSV 数据导入到 Neo4j 数据库中:
- 教程:导入数据
- 将 CSV 数据导入到 Neo4j
COLLECT 子查询是在 Neo4j 5.6 中引入的。这是一种新型的子查询,用于将子查询的结果收集到列表中,以便可以执行进一步的操作,如 DISTINCT、ORDER BY、LIMIT 和 SKIP。COLLECT 子查询与 COUNT 和 EXISTS 子查询的不同之处在于,最终的 RETURN 子句是强制性的。COLLECT 子查询中的 RETURN 子句必须只返回一列。
Cypher 子查询
子查询是在其自身范围内执行的一组 Cypher 语句。子查询通常从外部封闭查询中调用。
以下是关于子查询的一些重要事项:
- 子查询返回
RETURN子句中变量引用的值。 - 子查询不能返回与封闭查询中使用的变量同名的变量。
- 您必须显式地将变量从封闭查询传递到子查询。
- 子查询用大括号 (
{}) 划定。
在获取正确的结果一章的过滤模式部分中,您学习了如何基于模式进行过滤。例如,您可以编写以下查询来查找为 Neo4j 工作的人的朋友:
MATCH (p:Person)-[r:IS_FRIENDS_WITH]->(friend:Person)
WHERE exists((p)-[:WORKS_FOR]->(:Company {name: 'Neo4j'}))
RETURN p, r, friend
如果您在 Neo4j 浏览器中运行此查询,将返回以下图:
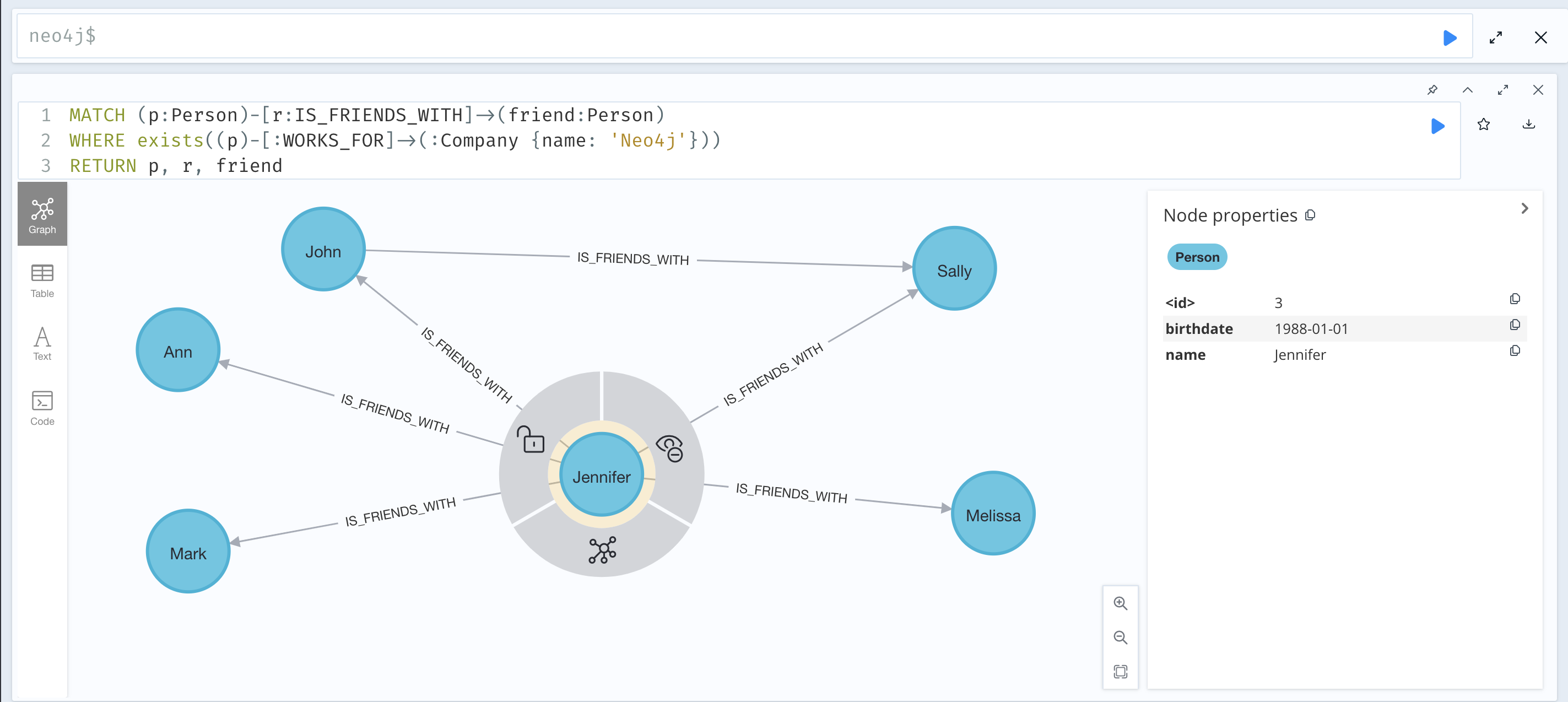
图 2. 图格式的输出
Cypher 子查询支持更强大的模式过滤。您可以不使用 WHERE 子句中的 exists 函数,而是使用 EXISTS 子查询。您可以使用以下查询重现前面的示例:
MATCH (p:Person)-[r:IS_FRIENDS_WITH]->(friend:Person)
WHERE EXISTS {
MATCH (p)-[:WORKS_FOR]->(:Company {name: 'Neo4j'})
}
RETURN p, r, friend
您将获得相同的结果,这很好,但到目前为止,您所实现的只是用更多的代码做同样的事情!
接下来,让我们编写一个子查询,该子查询的过滤能力比单独使用 WHERE 子句或 exists 函数所能实现的更强大。
假设:
- 您想找到为名称以“Company”开头的公司工作的人,并且他们喜欢至少一项被三个或更多人喜欢的技术。
- 您不感兴趣知道这些技术是什么。
您可以尝试使用以下查询来回答这个问题:
MATCH (person:Person)-[:WORKS_FOR]->(company)
WHERE company.name STARTS WITH "Company"
AND (person)-[:LIKES]->(t:Technology)
AND COUNT { (t)<-[:LIKES]-() } >= 3
RETURN person.name as person, company.name AS company;
如果您运行此查询,您将看到以下输出:
Variable `t` not defined (line 4, column 25 (offset: 112))
"AND (person)-[:LIKES]->(t:Technology)"
^
您可以找到喜欢某项技术的人,但您无法检查是否至少有其他三个人也喜欢该技术,因为变量 t 不在 WHERE 子句的范围内。让我们将两个 AND 语句移动到 EXISTS 子查询块中,从而得到以下查询:
MATCH (person:Person)-[:WORKS_FOR]->(company)
WHERE company.name STARTS WITH "Company"
AND EXISTS {
MATCH (person)-[:LIKES]->(t:Technology)
WHERE COUNT { (t)<-[:LIKES]-() } >= 3
}
RETURN person.name as person, company.name AS company;
现在您可以成功运行查询,该查询返回以下结果:
person company
"Melissa" "CompanyA"
"Diana" "CompanyX"
如果您回忆起本指南开头的图可视化,Ryan 是唯一另一个为名称以“Company”开头的公司工作的人。他已在此查询中被过滤掉,因为他喜欢的唯一技术是 Python,并且没有其他三个人喜欢 Python。
结果返回子查询
到目前为止,您已经学习了如何使用子查询来过滤掉结果,但这并没有完全显示它们的强大功能。您还可以使用子查询来返回结果。
假设您要编写一个查询,查找喜欢 Java 或有多个朋友的人。除此之外,您希望按出生日期降序对结果进行排序。这可以使用 UNION 子句和 COUNT 子查询部分实现:
MATCH (p:Person)-[:LIKES]->(:Technology {type: "Java"})
RETURN p.name AS person, p.birthdate AS dob
ORDER BY dob DESC
UNION
MATCH (p:Person)
WHERE COUNT { (p)-[:IS_FRIENDS_WITH]->() } > 1
RETURN p.name AS person, p.birthdate AS dob
ORDER BY dob DESC;
如果您运行该查询,您将看到以下输出:
person dob
"Jennifer" "1988-01-01"
"John" "1985-04-04"
"Joe" "1988-08-08"
您得到了正确的人。但是 UNION 方法只允许我们按 UNION 子句对结果进行排序,而不是对所有行进行排序。
您可以尝试另一种方法,即分别执行每个子查询,并使用 collect() 函数从每个部分收集人员。有些人喜欢 Java 并且有多个朋友,因此您需要在 RETURN 子句中使用 DISTINCT 运算符来删除重复项:
// Find people who like Java
MATCH (p:Person)-[:LIKES]->(:Technology {type: "Java"})
WITH collect(p) AS peopleWhoLikeJava
// Find people with more than one friend
MATCH (p:Person)
WHERE COUNT { (p)-[:IS_FRIENDS_WITH]->() } > 1
WITH collect(p) AS popularPeople, peopleWhoLikeJava
WITH popularPeople + peopleWhoLikeJava AS people
// Unpack the collection of people and order by birthdate
UNWIND people AS p
RETURN DISTINCT p.name AS person, p.birthdate AS dob
ORDER BY dob DESC
如果您运行该查询,您将获得以下输出:
person dob
"Joe" "1988-08-08"
"Jennifer" "1988-01-01"
"John" "1985-04-04"
这种方法有效,但更难编写,因为您必须不断地将查询的各个部分传递到它的下一部分。
CALL {…} 子句为您提供了两全其美的优势:
- 您可以使用
UNION方法来运行各个查询并删除重复项。 - 您可以在之后对结果进行排序。
我们使用 CALL {…} 子句的查询如下所示:
CALL {
MATCH (p:Person)-[:LIKES]->(:Technology {type: "Java"})
RETURN p
UNION
MATCH (p:Person)
WHERE COUNT { (p)-[:IS_FRIENDS_WITH]->() } > 1
RETURN p
}
RETURN p.name AS person, p.birthdate AS dob
ORDER BY dob DESC;
如果您运行该查询,您将获得以下输出:
person dob
"Joe" "1988-08-08"
"Jennifer" "1988-01-01"
"John" "1985-04-04"
您可以进一步扩展查询以返回这些人喜欢的技术以及他们拥有的朋友。以下查询显示了如何执行此操作:
CALL {
MATCH (p:Person)-[:LIKES]->(:Technology {type: "Java"})
RETURN p
UNION
MATCH (p:Person)
WHERE COUNT { (p)-[:IS_FRIENDS_WITH]->() } > 1
RETURN p
}
WITH p,
[(p)-[:LIKES]->(t) | t.type] AS technologies,
[(p)-[:IS_FRIENDS_WITH]->(f) | f.name] AS friends
RETURN p.name AS person, p.birthdate AS dob, technologies, friends
ORDER BY dob DESC;
person dob technologies friends
"Joe" "1988-08-08" ["Query Languages"] ["Mark", "Diana"]
"Jennifer" "1988-01-01" ["Graphs", "Java"] ["Sally", "Mark", "John", "Ann", "Melissa"]
"John" "1985-04-04" ["Java", "Application Development"] ["Sally"]
您还可以将聚合函数应用于子查询的结果。以下查询返回喜欢 Java 或有多个朋友的人中最年轻和最年长的人。
CALL {
MATCH (p:Person)-[:LIKES]->(:Technology {type: "Java"})
RETURN p
UNION
MATCH (p:Person)
WHERE COUNT { (p)-[:IS_FRIENDS_WITH]->() } > 1
RETURN p
}
RETURN min(p.birthdate) AS oldest, max(p.birthdate) AS youngest
oldest youngest
"1985-04-04" "1988-08-08"
总结
您已经了解了如何使用 EXISTS {} 子查询编写复杂的过滤模式,以及如何使用 CALL {} 子句执行返回结果的子查询。
Similar code found with 1 license type